一、基础知识准备:
1.散列函数即哈希函数:一般的线性表,树中,记录在结构中的相对位置是随机的,即元素位置和记录的关键字之间不存在确定的关系,因此,在结构中查找记录时需进行一系列和关键字的比较。这一类查找方法建立在“比较“的基础上,查找的效率依赖于查找过程中所进行的比较次数。 理想的情况是能直接找到需要的记录,因此必须在记录的存储位置和它的关键字之间建立一个确定的对应关系f,使每个关键字和结构中一个唯一的存储位置相对 应,这种关系就是就是数学上的散列函数,说白了哈希函数就是一种数学关系式。
2.散列表(Hash table,也叫哈希表),是根据(Key value)而直接进行访问的数据结构。也就是说,它通过把(Key value)映射到表中一个位置来访问记录,以加快查找的速度。这个映射函数叫做散列函数,存放记录的数组叫做散列表
3.冲突:对不同的关键字可能得到同一散列地址,即key1≠key2,而f(key1)=f(key2),这种现象称冲突。具有相同函数值的关键字对该散列函数来说称做同义词,必须继续寻址,耗费大量时间
对哈希表的使用者一一人来说,这是一瞬间的事。哈希表运算得非常快,在计算机程序中,如果需要在一秒种内查找上千条记录通常使用哈希表(例如拼写检查器)哈希表的速度明显比树快,树的操作通常需要O(N)的时间级。哈希表不仅速度快,编程实现也相对容易。
缺点:排序、容量填满重新映射hash地址扩容时
哈希表也有一些缺点它是基于数组的,数组创建后难于扩展某些哈希表被基本填满时,性能下降得非常严重,所以程序虽必须要清楚表中将要存储多少数据(或者准备好定期地把数据转移到更大的哈希表中,这是个费时的过程),初始化时给它设置指定初始容量和加载因子。
而且,也没有一种简便的方法可以以任何一种顺序〔例如从小到大〕遍历表中数据项。如果需要这种能力,就只能选择其他数据结构。
总结:然而如果不需要有序遍历数据,井且可以提前预测数据量的大小。那么哈希表在速度和易用性方面是无与伦比的。
三、实现原理
HashMap的工作原理:Entry数组+Entry链表
Entry<K,V>:


static class Entry<K,V> implements Map.Entry<K,V> { //key final K key; //value V value; //链表里对下一个Entry<K,V>的引用 Entry<K,V> next; //Entry<K,V>存储的hash位置值 int hash; public final boolean equals(Object o) { if (!(o instanceof Map.Entry)) return false; Map.Entry e = (Map.Entry)o; Object k1 = getKey(); Object k2 = e.getKey(); if (k1 == k2 || (k1 != null && k1.equals(k2))) { Object v1 = getValue(); Object v2 = e.getValue(); if (v1 == v2 || (v1 != null && v1.equals(v2))) return true; } return false; } public final int hashCode() { return (key==null ? 0 : key.hashCode()) ^ (value==null ? 0 : value.hashCode()); } public final String toString() { return getKey() + "=" + getValue(); } }
获取对象:
public V get(Object key) { if (key == null) return getForNullKey(); Entry<K,V> entry = getEntry(key); return null == entry ? null : entry.getValue(); } //键为空 private V getForNullKey() { for (Entry<K,V> e = table[0]; e != null; e = e.next) { if (e.key == null) return e.value; } return null; } //遍历数组里面的键值对对象:Entry,如果key的hashcode值与某个Entry的hash相等,key也相等,那么就返回Entry<K,V> final Entry<K,V> getEntry(Object key) { int hash = (key == null) ? 0 : hash(key); for (Entry<K,V> e = table[indexFor(hash, table.length)]; e != null; e = e.next) { Object k; if (e.hash == hash && ((k = e.key) == key || (key != null && key.equals(k)))) return e; } return null; }
储存对象:
public V put(K key, V value) { if (key == null) return putForNullKey(value); //得到key的hash值 int hash = hash(key); //得到元素在数组中存放的索引位置index值 int i = indexFor(hash, table.length); for (Entry<K,V> e = table[i]; e != null; e = e.next) { Object k; //如果key和hashcode相同,原来Entry存储的value值会被新的value值替代 if (e.hash == hash && ((k = e.key) == key || key.equals(k))) { V oldValue = e.value; e.value = value; //LinkedHashMap实现了此方法,HashMap是空实现,还请哪位大神赐教?当调用put(k,v)方法存入键值对时,如果k已经存在,原value被重写时,则该方法被调用 e.recordAccess(this); return oldValue; } } modCount++; addEntry(hash, key, value, i); return null; } //确定最终的在数组中存放的下标:bucketIndex void addEntry(int hash, K key, V value, int bucketIndex) { if ((size >= threshold) && (null != table[bucketIndex])) { //容量不够时,先扩容一倍,再遍历entry里面的key,大部分key都要根据key重新映射hash值,再把entry一一拷贝到新数组中,灰常耗性能 resize(2 * table.length); hash = (null != key) ? hash(key) : 0; bucketIndex = indexFor(hash, table.length); } createEntry(hash, key, value, bucketIndex); } //将要存的数据放入数组中 void createEntry(int hash, K key, V value, int bucketIndex) { Entry<K,V> e = table[bucketIndex]; table[bucketIndex] = new Entry<>(hash, key, value, e); size++; }
a:Entry<K,V> e = table[bucketIndex];
b:table[bucketIndex] = new Entry<>(hash, key, value, e); 这就是hashmap里面产生链表的地方,没有冲突,hashmap其实就是一个灰常牛b的数组
常常说编程之美,编程之美,在这里面还真的看到了很牛叉的地方
从b句可以看出,hashmap始终会将新的entry对象存入数组中,如果之前的位置有对象存在,新节点就指向e,反之则指向空对象e,也就没有所谓的链表
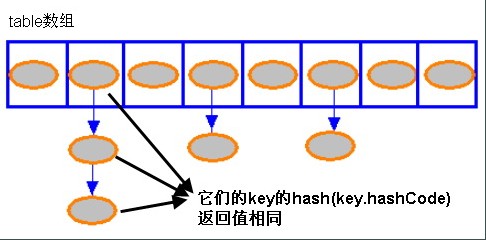
HashMap基于hashing原理,我们通过put()和get()方法储存和获取对象。
1.当我们将键值对传递给put()方法时,它调用键对象 的hashCode()方法来计算hashcode,让后找到bucket位置来储存值对象。
int hash = hash(key); //调用键对象 的hashCode()方法来计算hashcode
int bucketIndex = indexFor(hash, table.length); //hashcode值最终来确定bucketIndex的值
2.当获取对象时,通过键对象的equals()方法找到正确的键值对,然后返回值对象。
3.HashMap使用链表来解决碰撞问题,当发生碰撞了,对象将会储存在链表的下一个节点中。 HashMap在每个链表节点中储存键值对对象。
Entry<K,V> e = table[bucketIndex];
table[bucketIndex] = new Entry<>(hash, key, value, e);
4.当两个不同的键对象的hashcode相同时会发生什么? 它们会储存在同一个bucket位置的链表中。键对象的equals()方法用来找到键值对。
四、涉及的问题或知识点
为什么任何作为key的对象都必须实现hashCode和equals方法
1.Object的hashcode():key相等,返回的hashcode必须一致
根据散列函数的定义(对应Object的hashcode()的api):如果两个对象相同,即obj1.equals(obj2)=true,则它们的hashCode必须相同(value的地址Addr = a+ b*key,a、b都固定了,那么key一样,addr的值肯定也一样,所以这里的hashcode对应Addr也一样)
2.Object的equals():两个对象都是对同一个对象的引用,那么两个对象才是相等,他是比较对象引用的内存地址
Map<Student,String> m = new HashMap<Student,String>(); m.put(new Student(1,"zhangsan"), "aa"); m.put(new Student(1,"zhangsan"), "bb");
都能put进去
3.为什么任何作为key的对象都必须重写equals方法
在我们正常的商业或实际逻辑下,我们会认为new Student(1,"zhangsan")是重复的键,不能作为重复的键,一定得相等,但是程序认为他不是重复的键,最直观的理由因为两个值都put进去了,因为他们不是对某一个对象的相同引用,所以将对象作为map的key时必须重写equals
4.为什么任何作为key的对象都必须必须重写hashCode()
由object对象的hashCode方法api可知,obj1.equals(obj2)==false,那么对这两个对象中的任一对象上调用 hashCode 方法不要求一定生成不同的整数结果,也就可以这么理解:不同的对象可能会产生相同的整数结构,那就会产生链表,当你查询时就会影响效率,由下可知,所以为了提高hash表的效率,我们必须重写hashcode
final Entry<K,V> getEntry(Object key) { int hash = (key == null) ? 0 : hash(key);
//不同key,有相同hash,Entry就会产生链表即e.next有对象,就会有遍历,影响查询性能 for (Entry<K,V> e = table[indexFor(hash, table.length)]; e != null; e = e.next) { Object k; if (e.hash == hash && ((k = e.key) == key || (key != null && key.equals(k)))) return e; } return null; }
为什么String, Interger这样的wrapper类适合作为键?
String, Interger这样的wrapper类作为HashMap的键是再适合不过了,而且String最为常用。因为String是不可变的,也是final 的,而且已经重写了equals()和hashCode()方法了。其他的wrapper类也有这个特点。不可变性是必要的,因为为了要计算 hashCode(),就要防止键值改变,如果键值在放入时和获取时返回不同的hashcode的话,那么就不能从HashMap中找到你想要的对象。不 可变性还有其他的优点如线程安全