双语数据预处理
学习目标:了解和学习开发汉英双语数据预处理模块。
双语数据预处理是统计机器翻译系统构建的第一步,为词对齐处理提供分词后的
双语数据。预处理的工作本质上就是双语数据的分词处理,与传统分词不同的一
点在于需要对一些特定类型词汇进行泛化处理,如数字词汇“123.45”泛化为
“$number”来代替原文。本讲中以汉英双语数据为处理内容。
本讲学习内容:
中文分词预处理
采用传统基于词典的正向最大匹配法来完成中文分词。基本流程如图所示:

由于数字 、日期 、时间网址 等不可枚举,无法通过词典简单查找来分。 可以采用正则表达式或者自动机进行识别,并给予特殊名字泛化。 可以采用正则表达式或者自动机进行识别,并给予特殊名字泛化。 例如 :
数字类型 $number $number $number $number $number $number 如: 123
日期类型 $date $date 如: 1993 年 12 月 3日
时间类型 $time $time 如: 3:10
网址等类型 $literal $literal 如: www.cnblogs.com
实际上 大家可以总结更多类型,并自行定 大家可以总结更多类型,并自行定 义泛化名字进行替换原文。 泛化的 目的是为了有效解决数据稀疏问题。
需要注意一点的是,建议不对组织机构名进行捆绑为个词汇。例如将“东 需要注意一点的是,建议不对组织机构名进行捆绑为个词汇。例如将“东 需要注意一点的是,建议不对组织机构名进行捆绑为个词汇。例如将“东 需要注意一点的是,建议不对组织机构名进行捆绑为个词汇。例如将“东 北大学信息院”最好分成两个词“东”“。这样做的处是为 北大学信息院”最好分成两个词“东”“。这样做的处是为 北大学信息院”最好分成两个词“东”“。这样做的处是为 北大学信息院”最好分成两个词“东”“。这样做的处是为 北大学信息院”最好分成两个词“东”“。这样做的处是为 北大学信息院”最好分成两个词“东”“。这样做的处是为 了
例如双语句对:
中文: 4月 14 日我买了 10 本书。
英文: I bought 10 books on April 14.
预处理结果:
中文: $date 我 买 了 $number 本 书 。
英文: i bought $number books on $date .
其它说明:
1) 中文的全角字符可以考虑改写为半角字符来处理;
2) 同一类型的泛化名字在中英文中最好一样,如中文/英文数字=>$number;
3) 也可以采用 CRF 或者语言模型来实现高性能中文分词;
4) 注意区分英文的句尾符号“.”和“Mr. Smith”的“.”;
5) 双语句对的泛化结果需要检查一致性,例如中文句子中包含$number,正 常情况下,英文句子中也应该包含$number 等;
6) 目前有很多开源的分词工具可以被使用,如 NiuTrans 提供的双语数据预
处理工具从 http://www.nlplab.com/NiuPlan/NiuTrans.YourData.html 下载。 本讲资源(UTF8 编码):10 万行汉英双语句对和中文电子词典。
词对齐
学习目标:学会使用词对齐工具 GIZA++并自行开发词对齐对称化程序。 词对齐是统计机器翻译系统构建的第二步,经过第一步双语数据预处理后,
得到分词后的双语数据。而词对齐的任务就是要得到中英文词语的对应关系。
本讲学习内容:
GIZA++的使用
GIZA++是 GIZA(SMT 工具包 EGYPT 的一个组成部分)的扩展,扩展部分 主要由 Franz Josef Och 开发。GIZA++主要算法是 IBM model、HMM 等。
1、GIZA++运行环境:Linux,并预装软件 gcc、g++。
2、GIZA++下载地址:
http://code.google.com/p/giza-pp/downloads/detail?name=giza-pp-v1.0.7.tar.gz
3、编译:
a)首先进入到 GIZA++根目录
b)解压包,指令:tar zxvf giza-pp-v1.0.7.tar.gz c)进入到解压后的目录,指令:cd giza-pp
d)编译,指令:make
4、GIZA++运行:
a)新建目录 Alignment,并将编译后的 GIZA++-v2 目录下的“GIZA++”、
“snt2cooc.out”、“plan2snt.out”文件和 mkcls-v2 目录下的“mkcls”文件,拷贝到
Alignment 目录下,同时将预处理后的文件 c.txt 和 e.txt 作为 GIZA++工具的 输入文件放到其中。
b)在终端依次运行以下命令,获得下一步需要的文件:c2e.A3.final 和
e2c.A3.final。
$> ./plain2snt.out e.txt c.txt
$> ./snt2cooc.out c.vcb e.vcb c_e.snt> cooc.ce
$> ./snt2cooc.out e.vcb c.vcb e_c.snt > cooc.ec
$> ./mkcls -m2 -c80 -n10 -pe.txt -Ve.vcb.classes opt
$> ./mkcls -m2 -c80 -n10 -pc.txt -Vc.vcb.classes opt
$> ./GIZA++ -S c.vcb –T e.vcb –C c_e.snt -CoocurrenceFile cooc.ce -O c2e
$> ./GIZA++ -S e.vcb –T c.vcb –C e_c.snt -CoocurrenceFile cooc.ec -O e2c
l 词对齐对称化
由于 GIZA++程序中,原语=>目标语和目标语=>原语的对齐过程是彼此独立 的,因此会产生两个对齐文件,词对齐对称化的任务就是通过一定的算法合并这
两个对齐文件。
1、输入:GIZA++运行目录中的 c2e.A3.final 文件和 e2c.A3.final 文件,格式如下:
c2e.A3.final 文件的一个句对:
# Sentence pair (1) source length 5 target length 7 alignment score : 3.53407e-09 the weather is very good today .
NULL ({ 1 3 6 }) 今天 ({ }) 天气 ({ 2 }) 真 ({ 4 }) 好 ({ 5 }) . ({ 7 })
e2c.A3.final 文件的一个句对:
# Sentence pair (1) source length 7 target length 5 alignment score : 5.24219e-08
今天 天气 真 好 .
NULL ({ }) the ({ 2 }) weather ({ 2 }) is ({ }) very ({ 3 }) good ({ 4 }) today ({ 1 }) . ({ 5 })
其中,第三行大括号里面的数字,代表该大括号前面的词语对应的目标语的词的
位置。
如:“天气 ({ 2 })”中的“2”表示对应的英语中的“weather”。
“weather ({ 2 })”中的“2”表示对应的汉语中的“天气”。 因此,“天气”和“weather”构成了一个双向对齐“天气”ó“weather”。
“today ({ 1 })”中的“1”表示对应的汉语中的“今天”。 而“今天”后的({})为空,并未与“today”对应。
因此,“today”和“今天”就构成了一个单向对齐“today”=>“今天”。
另外,“NULL ({ 1 3 6 })”表示英文中“the”“is”“today”对空,即形成空 对齐“the”=>“NULL”,“is”=>“NULL”,“today”=>“NULL”。
2、输出:将两个输入文件通过算法合并为对齐文件,文件中每一行格式如下:
0-5 1-0 1-1 2-3 3-4 4-6
其中,0-5 表示经过算法合并后,中文中第 0 个词“今天”与英文中第 5 个词“today” 对齐。
3、词对齐对称化算法:
算法流程如下:
Matrix[src_len][trg_len];
neighboring = (上,下,左,右,左上,左下,右上,右下); 寻找对齐节点,将双向对齐节点加入 Alignment 循环直到没有新节点出现
遍历 Alignment,查看该节点的 neighboring
若某一 neighboring 单向对齐,且该点的原语或目标语未双向对齐 则加入该节点到 Alignment
遍历 Matrix 如果存在某节点单向对齐,且该点的原语或目标语未双向对齐 则加入该节点到 Alignment
该算法与 Philipp Koehn 的 GROW-DIAG-FINAL 算法类似。
4、算法说明:
以上面的句对作为示例:
中文到英文:
# Sentence pair (1) source length 5 target length 7 alignment score : 3.53407e-09 the weather is very good today .
NULL ({ 1 3 6 }) 今天 ({ }) 天气 ({ 2 }) 真 ({ 4 }) 好 ({ 5 }) . ({ 7 })
英文到中文:
# Sentence pair (1) source length 7 target length 5 alignment score : 5.24219e-08
今天 天气 真 好 .
NULL ({ }) the ({ 2 }) weather ({ 2 }) is ({ }) very ({ 3 }) good ({ 4 }) today ({ 1 }) . ({ 5 })
1) 首先,找到对齐的词语对,将所有双向对齐加入 Alignment。如图(矩阵中
实心方格表示双向对齐,虚线空心方格表示单向对齐):

2) 遍历 Alignment,对其邻居进行检测,如果邻居中存在单向对齐的点,并且 该点的两个词中存在一个没有与任何词双向对齐,则将该点加入 Alignment。 循环这个操作直到没有新节点加入。如上图中,当遍历到“weather-天气”时, 发现该点左边存在单向对齐点“the-天气”,且“the”尚未与任何词双向对 齐,则将该点加入 Alignment。

3) 在一个没有与任何词双向对齐,则将该点也加入 Alignment。如图,当遍历 到“today-今天”时,发现该点是一个单向对齐点,并且“today”尚未与任何3) 最后遍历矩阵中所有节点,如果存在单向对齐的点,并且该点的两个词中存
词双向对齐,则将该点加入 Alignment。

4) 最后获得最终的对齐信息输出到文件,如上图所示,得到的对称化的词对齐 信息为:
0-5 1-0 1-1 2-3 3-4 4-6
短语翻译表构造 --短语抽取
学习目标:深刻理解基于短语统计机器翻译系统中短语1抽取的基本算法,可自行开发短语抽取模块。 短语抽取是统计机器翻译系统构建的第三步,经过第二步词对齐后,获得双语平行句对间的词对
齐信息。短语抽取是短语翻译表构造的第一步2,短语抽取的任务是从含有词对齐信息的双语平行句
对中学习解码器在翻译过程中使用的翻译短语。 本讲学习内容:
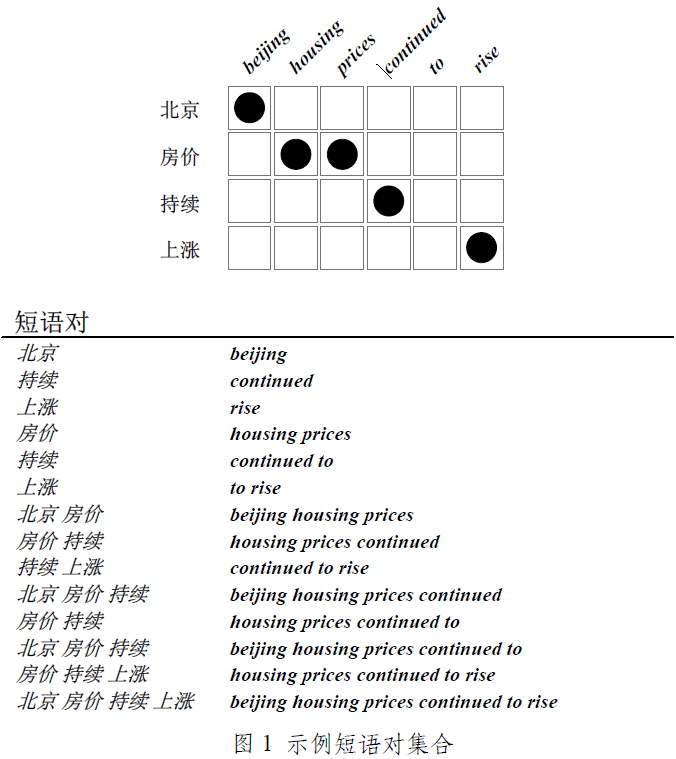
l 示例短语

短语抽取的本质是从含有词对齐信息的平行句对中抽取基于短语的统计机器翻译系统中使用的 翻译短语。图 1 中展示了从含有词对齐信息的双语平行句对(图 1 中上方图所示)中抽取的短语对(图
1 中下方的“示例短语”所示)。从图 1 中可以看出,在给定词对齐信息的双语平行句对中,理想情 况下是可以抽取与词对齐保持一致的短语对,如“示例短语”中所示的短语对。
l 一致性短语
使用含有词对齐信息的双语平行句对进行短语抽取时,抽取出的短语对需要与词对齐保持一致。 下面给出一致性的定义。

短语抽取算法 在定义“一致性短语”后,本节给出在含有词对齐信息的双语平行数据中抽取所有满足“一致性”
定义短语对的算法。
算法 1 的核心思想:长度从 1 到 I 遍历目标语端词串并且在源语端找到与之匹配的最小词串。如 果目标语端词串中所有词汇在词对齐中对应的项都在与之匹配的源语词串范围内,并且源语端词串中 所有词汇在词对齐中所对应的项都在目标语词串范围内时,同时源语、目标语词串不能只包含对空词
汇,此时找到的源语端、目标语端词串便与词对齐保持一致,称双语端词串对为短语对。
算法 1 详细解释如下:
1. 算法第 1 行与第 2 行在目标语端进行二重循
环,目的是遍历目标语端所有可能出现的短 语;算法第 2 行设臵当前目标语端词串的起始位置。
2. 算法第 3 行设臵当前目标语端词串的结束位置。
3. 算法第 4 行设臵当前源语端词串的起始位置与结束位置。起始位置设为源语句子长度的最大值,结束位置设为0。该设置可快速判断是否可找到与词对齐保持一致的短语。
4. 算法第5-10行确保目标语端词串![]() 中的所有词汇在词对齐中对应的词汇在源语端词串
中的所有词汇在词对齐中对应的词汇在源语端词串![]() 范围内。
范围内。
5. 算法第11行使用extract j1,j2,i1,i2 函数对找到的可能短语对进行验证和扩展,确保找到短语对与词对齐保持一致。

算法2中extract函数是算法1中第11行使用的对找到的短语进行验证和扩展的函数。在与词对齐保持一致的短语对的扩展过程中,主要是短语对中源语端与目标语端边缘对空词汇的扩展。根据一致性的定义,边缘对空词汇不会影响短语一致性的性质,同时,抽取更多边缘对空扩展对空短语可获得更多上下文信息、可适当缓解词对齐不精确带来的问题。
算法2详细解释如下:
1.算法第1-3行保证找到的源语端词串中至少有一个词汇在词对齐中对应的项在目标语词串![]() 内。
内。
2.算法第4-8行确保源语端词串![]() 中的所有词汇在词对齐中对应的词汇在目标语端词串
中的所有词汇在词对齐中对应的词汇在目标语端词串![]() 范围内,即找到与词对齐一致的短语对。
范围内,即找到与词对齐一致的短语对。
3. 算法第9行初始化短语对集合为空。
4. 算法第10-18行扩展与词对齐保持一致的短语对,如果找到的短语对的源语端或目标语端的边界词汇对空,则扩展该短语对,将新短语对加入到短语对集合![]() 中。
中。
5. 算法第19行返回短语对集合![]() 。
。

短语抽取流程

图2 短语抽取流程,其中蓝色点为异常点
图2 展示应用短语抽取算法1、2 抽取短语对的基本流程。其中“从目标语长度n 开始循环”为算法1 的第1 行;每组三个图如“(a),(b)和(c)”为算法1 中第2 行至第12 行。图(2)中(a)图展示抽取的一个与词对齐保持一致的短语对“北京,beijing”;(b)图展示一个非法的短语对“房价,housing”,其中目标语端词汇“prices”为异常点。
满足一致性的短语:
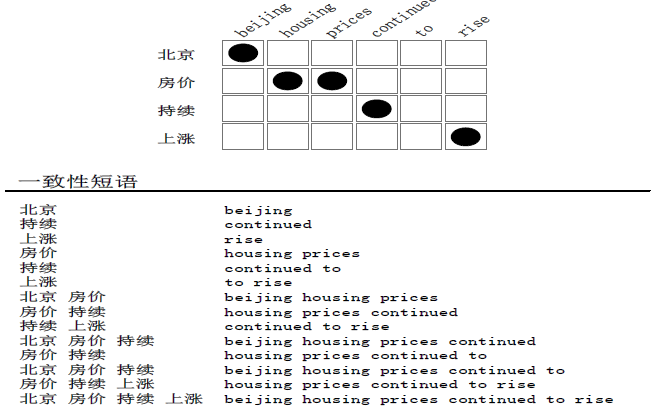
图3 双语数据与词对齐信息中抽取满足一致性定义的所有短语对,以算法1 实际短语抽取顺序排序
图3中所示“一致性短语”为根据上文“一致性”定义及“算法1、2”从示例含有词对齐信息的双语平行句对中抽取的所有与词对齐保持一致的短语对。
短语翻译表构造 –概率估计
学习目标:深刻理解基于短语统计机器翻译系统中短语翻译表概率估计的基本步骤,可自行开发概率
估计模块。
短语翻译表概率估计是统计机器翻译系统构建的第四步,经过第三步短语抽取后,获得基于短语
系统使用的翻译短语对,概率估计的作用是对翻译短语对的正确性进行合理的评估。
本讲学习内容:
示例短语对集合