本文主要提供了一个基于bert的篇章级编码器,能够编码一篇文章并获取每一句话的表征。为了提取句子,我们的提取模型是建立在编码器的顶层,通过叠加一些句间Transformer层来获取篇章级特征。而抽象模型提出了一个编码器-解码器结构,结合相同的预训练bert编码器(使用随机初始化的Transformer解码器)。论文设计了一个新的训练流程,能够分开编码器和解码器的优化步骤来适应编码器和解码器,因为前者是预训练的,而后者必须从头训练。
本文的贡献主要有三点:
-
证明了篇章级编码对于摘要任务的重要性。目前有各种各样的技术用来增强摘要性能,包括复制机制(copying mechanisms)、增强学习、多交互编码器(multiple communicating encoders)。我们使用最小需求的模型、没有使用任何其他的机制就获取了更好地结果。
-
我们展示了在抽取和抽象的设置下有效利用预训练模型进行摘要的方法;我们希望在模型与训练中的任何改进都能更好地进行摘要的特征抽取。
-
提出的模型可以做提高摘要新能的基石,也可以作为测试新方案的baseline
二、背景
1、抽取摘要
抽取摘要系统通过识别(和子连接)一篇文章中最重要的句子进行摘要。神经模型将提取摘要视作句子分类问题:一个神经编码器创建了一个句子表征,一个分类器预测这个句子是否应该被选做摘要。
2、抽象摘要
抽象式摘要的神经方法将这个任务概念化为seq2seq问题,seq2seq将编码器将一篇文章中的一个句子映射为一系列tokens,如在原始文章中x=[x1,...,xn],转变为一个句子的连续表征z=[z1,...,zn],而解码器会token-by-token的生成目标摘要y=[y1,...,ym],使用自回归(auto-regressive)方法,因此模型化条件概率:p(y1,...,ym|x1,...,xn)
3、模型结构
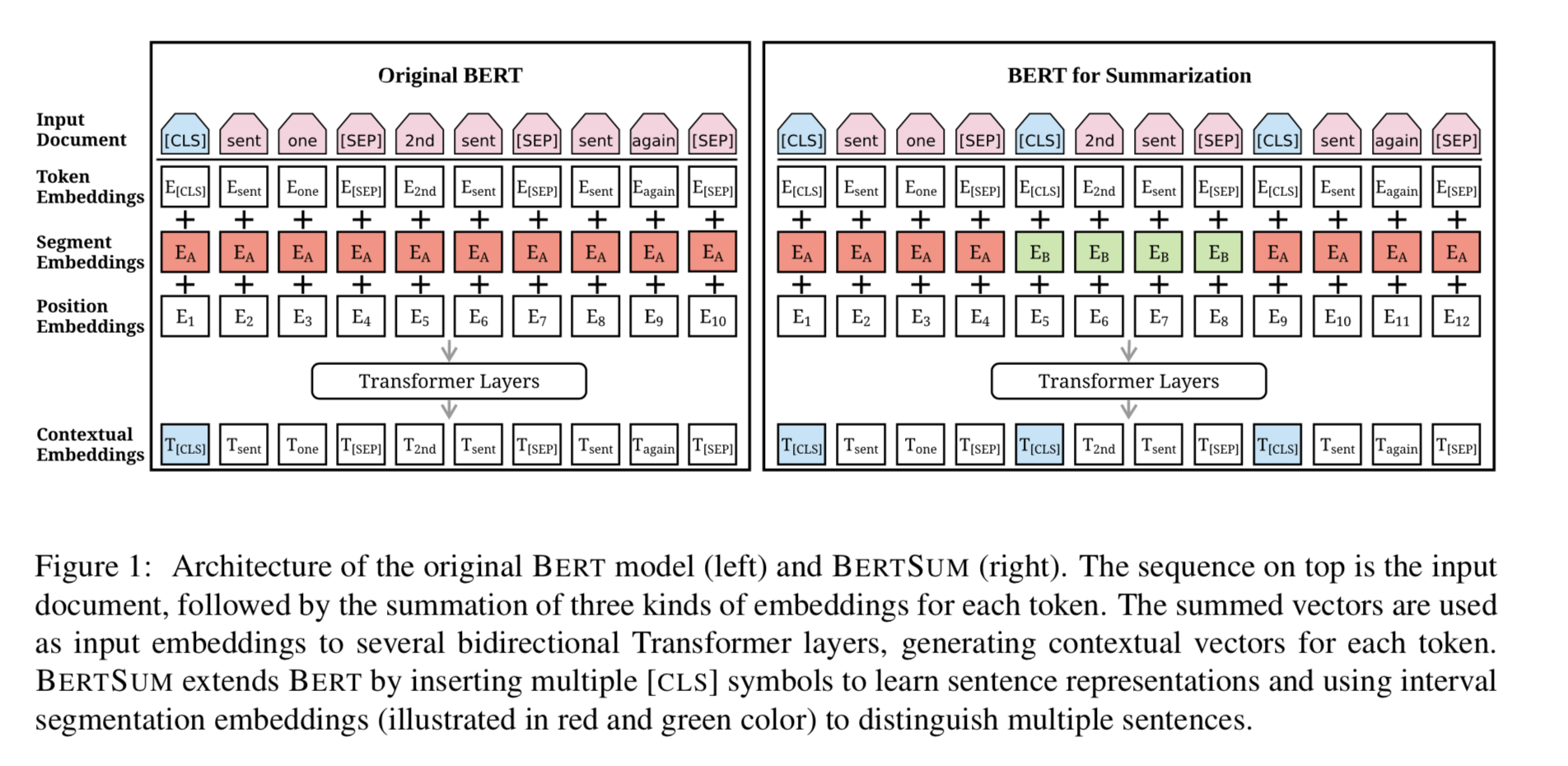
如下图所示,左图为原始bert图,右侧为应用于摘要的bert结构图,命名为bertSum,可以看出,右图主要有两个变化:
①每一句话都使用[CLS]开头,以[SEP]结尾,而原始bert只在最开始的时候有一个[CLS],并且用[SEP]来分割句子。
②是segment embedding,原始bert因为有NSP训练过程因此使用E_A,E_B表示两句话,而bertSum由于输入的是篇章,因此使用E_A,E_B,E_A,E_B,...等来表征不同语句,如输入是x=[x1,x2,x3,x4,x5,x6],则seg_emb=[A,B,A,B,A,B]
三、微调bert
1、提取式摘要
令d表示一篇文章,d=[sent1,sent2,...,sent_m],其中sent_i表示文章d中的第i句话。向量t_i,是顶层中第i个[CLS]标志的用于表征第i句话sent_i的向量。
为了提取摘要,在bert的输出上叠加一些句间Transformer层来获取篇章级特征。
最终的输出层是一个sigmoid分类器。
我们通过最顶层(第L层)的Transformer来获取sent_i的向量,实验时,我们通过设置L=1,2,3层Transformer来进行测试,发现当L=2时,即有2层Transformer时性能最好,最终命名该模型为BERTSUMEXT。
模型的损失函数是预测值y_i和标签y_i的二分类熵值。句间Transformer层会联合微调BertSum。
我们使用adam优化器(beta1=0.9,beta2=0.999)。
学习率按照warming-up安排(warmup=10000).
lr = 2e^{−3} · min (step^{−0.5}, step · warmup^{−1.5})
2、抽象式摘要
使用标准的编码器-解码器框架来进行抽象式摘要。编码器是与训练的BERTSUM,而解码器是一个6层的随机初始化的Transformer层。可以想象的在编码器和解码器之间会有一个不匹配现象,因为编码器是预训练的而解码器必须从头训练。这会导致微调不稳定,比如说编码器是过拟合而解码器是欠拟合的,反之亦然。
本文提出了一个新的微调手段,是将编码器和解码器的优化器分开设计。
我们使用两个adam优化器,其中编码器的优化器使用参数如下:beta1=0.9,beta2=0.999,而解码器的则不同,使用不同的warmup-steps和学习率如下:

这样做的依据是:假设与训练的编码器应该使用更小的学习率和更平滑的decay进行微调(以便于编码器可以使用更精确地梯度进行训练而解码器可以变得稳定)。该模型命名为BERTSUMABS.
另外,我们提出了一个两阶段微调方法,第一阶段是在提取式摘要任务上微调编码器,然后在抽象式摘要任务上进行微调。该模型命名为BERTSUMEXTABS.
四、实验细节
1、数据:CNN/DailyMail,NYT,XSum
2、提取式摘要:
-
在3 GPUs(GTX 1080 Ti)上训练50000步,每两步进行一次梯度累积。
-
保存和评估模型的checkpoints,是在验证集上每1000步进行一次。
-
使用验证集上的评估损失,我们选取损失最低的3个checkpoints,然后报告测试集上的平均结果。
-
我们使用贪心算法来获取每篇文章的最佳的摘要来训练提取模型。这个算法生成一个最佳的包含多个句子的摘要,相对于标签的摘要来说它能获取最高的rouge-2分数。
-
当进行预测时,我们使用这个模型获取每个句子的得分,并从高到低排序,然后选取最顶层的3个句子作为摘要。
-
在句子选择的过程中,我们使用三元组块来减少冗余。在给出摘要S和候选句子c的情况下,如果c和S之间存在三元组重叠,则跳过c。这一直觉性的选择类似于MMR(Maximal Marginal Relevance),我们希望能够最小化候选的句子和已经选择作为摘要的句子之间的相似性。
3、抽象式摘要:
-
在所有的抽象的模型中,我们在所有的线性层前应用dropout(probability=0.1),标签滑动且滑动因子=0.1。
-
Transformer的解码器有768个隐藏神经元,所有前馈层的隐藏size=2048.
-
所有的模型训练200000步,在4块GPU上(GTX 1080 Ti),每5步进行一次梯度累积。
-
每2500步进行一次模型保存和评估(在验证集上)
-
选择验证集上评估损失最低的3个模型参数应用在测试集上并报告其平均结果。
-
在解码阶段我们使用beam search(size=5),然后为了进行长度惩罚,在验证集上解码时从0.6到1之间调整alpha
-
我们解码直到最后一个句子token都被处理然后重复三元组被组成块。