
一、描述
工作中需要调用第三方接口(百度AI接口),实现一些AI相关的功能。但是开通付费接口后,但仍有10QPS的限制,超出的部分会被百度拒绝,直接报错。而我们的业务需求是要基本保证调用成功的。因此需要一个漏桶/限流器来控制调用速度去适配这10QPS的限制,剩余的请求进入等待队列。
在完成适配后,10QPS对于业务并发峰值的场景是不够的,而QPS叠加包长期购买太贵,阶段购买又太麻烦,遂采用多帐号的方案去应对并发峰值。一开始计划是通过某种负载均衡的策略去实现,后来发现百度AI接口调用量上来后是有打折优惠的,因此设计多级漏桶去实现。
二、前置知识
2.1 漏桶与令牌桶
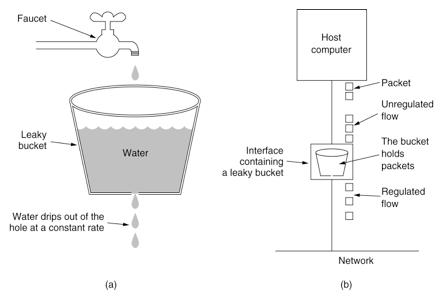
漏桶
漏桶算法思路很简单,水(请求)先进入到漏桶里,漏桶以一定的速度出水,当水流入速度过大会直接溢出,可以看出漏桶算法能强行限制数据的传输速率。
令牌桶
对于很多应用场景来说,除了要求能够限制数据的平均传输速率外,还要求允许某种程度的突发传输。这时候漏桶算法可能就不合适了,令牌桶算法更为适合。令牌桶算法的原理是系统会以一个恒定的速度往桶里放入令牌,而如果请求需要被处理,则需要先从桶里获取一个令牌,当桶里没有令牌可取时,则拒绝服务。
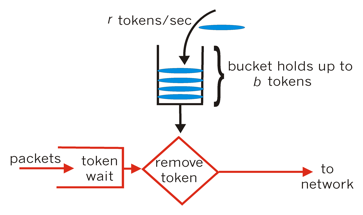
应用场景:
并不能说明令牌桶一定比漏洞好,她们使用场景不一样。令牌桶可以用来保护自己,主要用来对调用者频率进行限流,为的是让自己不被打垮。所以如果自己本身有处理能力的时候,如果流量突发(实际消费能力强于配置的流量限制),那么实际处理速率可以超过配置的限制。而漏桶算法,这是用来保护他人,也就是保护他所调用的系统。主要场景是,当调用的第三方系统本身没有保护机制,或者有流量限制的时候,我们的调用速度不能超过他的限制,由于我们不能更改第三方系统,所以只有在主调方控制。这个时候,即使流量突发,也必须舍弃。因为消费能力是第三方决定的。
总结起来:如果要让自己的系统不被打垮,用令牌桶。如果保证别人的系统不被打垮,用漏桶算法。
2.2 限流利器-Semaphore
在 JUC 包下,有一个 Semaphore 类,翻译成信号量,Semaphore(信号量)是用来控制同时访问特定资源的线程数量,它通过协调各个线程,以保证合理的使用公共资源。Semaphore 跟锁(synchronized、Lock)有点相似,不同的地方是,锁同一时刻只允许一个线程访问某一资源,而 Semaphore 则可以控制同一时刻多个线程访问某一资源。
Semaphore(信号量)并不是 Java 语言特有的,几乎所有的并发语言都有。所以也就存在一个「信号量模型」的概念,如下图所示:
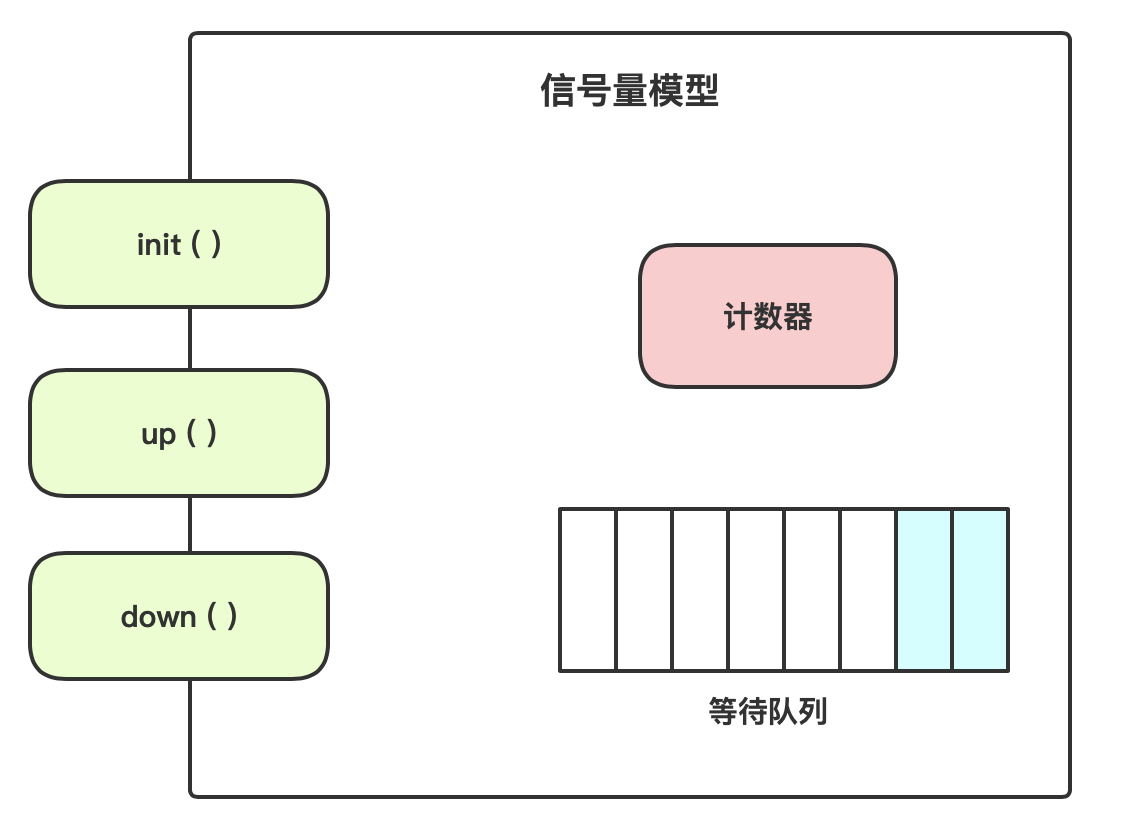
信号量模型比较简单,
可以概括为:「一个计数器、一个队列、三个方法」。
计数器:记录当前还可以运行多少个资源访问资源。
队列:待访问资源的线程
init():初始化计数器的值,可就是允许多少线程同时访问资源。
up():计数器加1,有线程归还资源时,如果计数器的值大于或者等于 0 时,从等待队列中唤醒一个线程
down():计数器减 1,有线程占用资源时,如果此时计数器的值小于 0 ,线程将被阻塞。
鉴于我们是部署多实例的分布式系统,JUC实现Semaphore的并不是适用,使用Redisson实现的分布式信号量。
<dependency>
<groupId>org.redisson</groupId>
<artifactId>redisson-spring-boot-starter</artifactId>
</dependency>
下面介绍一下关于Semaphore的主要方法:
//获取指定名称的信号量实例
RSemaphore getSemaphore(String name);
//获取指定名称的信号量实例,许可带有过期时间
RPermitExpirableSemaphore getPermitExpirableSemaphore(String name);
//尝试设置信号量许可个数
boolean trySetPermits(int permits);
//从信号量中获取许可,相当于获取到执行权,获取不到会阻塞,直到获取到为止
String acquire() throws InterruptedException;
//获取一个指定过期时间的许可
String acquire(long leaseTime, TimeUnit unit) throws InterruptedException;
//尝试获取一个许可,不会阻塞,获取不到返回null
String tryAcquire();
//尝试在指定时间内获取一个许可
String tryAcquire(long waitTime, TimeUnit unit) throws InterruptedException;
//尝试在指定时间内获取一个指定过期时间的许可
String tryAcquire(long waitTime, long leaseTime, TimeUnit unit) throws InterruptedException;
//尝试通过许可id释放
boolean tryRelease(String permitId);
//通过id释放许可
void release(String permitId);
三、调用百度AI接口适配实现
通过对漏桶、令牌桶概念的了解,以及对限流利器-semaphore的的认识;就可以通过漏桶的理念以及redisson的semaphore API 去实现限制对百度接口的调用,保证10QPS匀速调用;
还有一个问题:“漏桶”的容量如何确定?
根据业务需求而定,假设调用AI接口的等待时间“容忍度”是 10s,假设AI接口本身2s的耗时,那么对于同一个AI接口的请求就是80个,“漏桶”的容量(等等队列)就是80。
同样可以使用现成的redisson提供的分布式队列API,去实现、假如队列满,直接拒绝。
当然这个AI接口本身的耗时会根据它的类型以及数据的大小而改变,这里使用线程池执行器 ThreadPoolExecutor 的一些特性以及自带的队列去实现功能,具体:
- future.get(TIME_OUT, TimeUnit.MILLISECONDS); 控制“容忍”时间
- 线程池等待队列大小来控制“桶”的容量,超出拒绝。
部分代码实现:
1.构建调用任务,期中maxQPS为百度AI接口的最大QPS限制,TIME_WINDOW为信号量释放时间 = 1s
public class BaiduAIClientTask implements Callable<BaiduAIClientTask> {
@Override
public BaiduAIClientTask call() {
RPermitExpirableSemaphore semaphore = redissonClient.getPermitExpirableSemaphore("key");
semaphore.trySetPermits(maxQPS);
semaphoreAll.acquire(TIME_WINDOW,TimeUnit.MILLISECONDS);
//调用百度接口
this.jsonObject = aiClient.send(aipRequest);
}
}
2.定义线程池执行任务
public class ClientAIOperation {
public JSONObject getResponse(AipRequest aipRequest) {
//获取固定线程的线程池(单例),设置线程数量、队列大小
ExecutorService executorService = baiduAIClientContext.getExecutorService(nThreads,ququeSize);
JSONObject jsonObject = null;
Future<BaiduAIClientTask> future = null;
try {
future = executorService.submit(task);
BaiduAIClientTask baiduAIClientTask = future.get(TIME_OUT, TimeUnit.MILLISECONDS);
jsonObject = baiduAIClientTask.getJsonObject();
} catch (RejectedExecutionException e) {
throw new BaiduClientException("系统繁忙~");
} catch (TimeoutException e) {
future.cancel(true);
throw new BaiduClientException("执行超时,请重试~");
}
return jsonObject;
}
}
四、多帐号提升QPS瓶颈
上面的操作也是仅是尽可能保证用户在容忍时间内能调用成功,支持10QPS的并发。
QPS叠加包
通过调研了解,百度AI接口提供QPS叠加包服务,在对应上课时间购买QPS叠加包,来应对高并发调用。
缺点:
①需要关心具体业务使用时间,频繁的购买相应的QPS叠加包。
②太贵了 ,如下表:200QPS每天就是 2000元,而且仅仅是单个接口
| 接口 | 按天购买价格(元/QPS/天) | 按月购买价格(元/QPS/月) |
|---|---|---|
| 通用物体和场景识别 | 50 | 750 |
| logo识别-检索 | 10 | 150 |
| 图像主体检测(单主体) | 5 | 75 |
| 植物识别 | 10 | 150 |
| 动物识别 | 10 | 150 |
| 菜品识别 | 10 | 150 |
| 自定义菜品识别-检索 | 50 | 750 |
| 果蔬识别 | 10 | 150 |
| 地标识别 | 10 | 150 |
| 图像主体检测(多主体) | 10 | 150 |
多账号解决方案
鉴于QPS叠加包高额费用以及需要频繁的购买相应服务,那么我们采用多帐号的方案来解决。
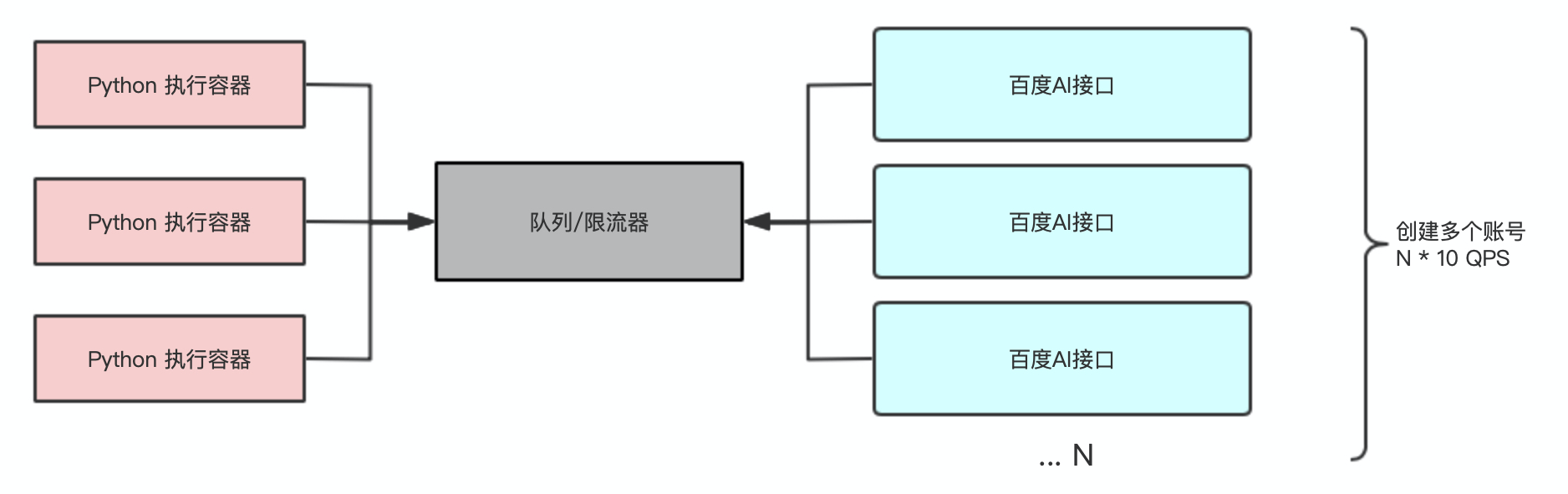
五、多级漏桶设计
但是多帐号同样面临一个问题,一般AI能力服务会随着调用量的增加而费用减少,如下表:
| 月调用量(万次) | 菜品识别(元/千次) |
|---|---|
| 0<月调用量<=5 | 0.70 |
| 5<月调用量<=10 | 0.60 |
| 10<月调用量<=20 | 0.50 |
| 20<月调用量<=50 | 0.40 |
| 50<月调用量<=100 | 0.35 |
| 100<月调用量 | 0.30 |
为了尽量使得一个账号达到减免额度,采用如下图所示设计,当用户请求过来默认进入第一个『桶』中,当并发量过大,第一个『桶』处理不过来,溢出到下一个桶中,依次溢出。当最后一个『桶』满后,剩下的请求在『蓄水池』{等待队列}中等待
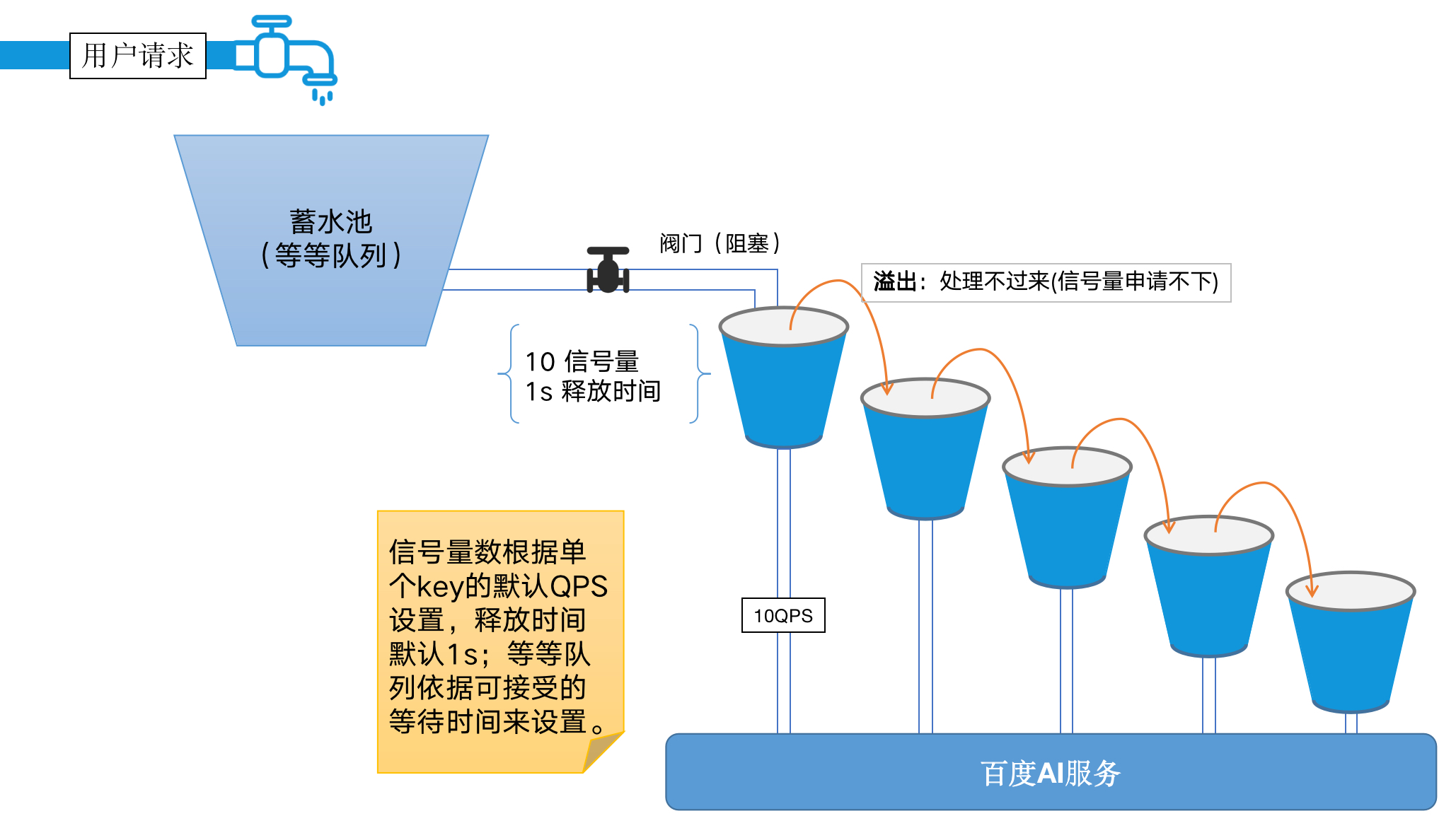
部分代码实现:
通过递归与tryAcquire()方法的特行,实现让桶溢出后流入下一个桶。
@Override
public BaiduAIClientTask call() {
//蓄水池外流速度信号量
RPermitExpirableSemaphore semaphoreAll = redissonClient.getPermitExpirableSemaphore(“蓄水池”);
//桶的总流量 = 桶流速 * 桶数
semaphoreAll.trySetPermits(maxQPS * baiduAIClientList.size());
try {
//申请蓄水池信号量,如果满了会阻塞于此 模拟阀门
semaphoreAll.acquire(TIME_WINDOW,TimeUnit.MILLISECONDS);
//第一个桶开始工作 leakyBucketNumber = 0
this.leakyBucketWork(leakyBucketNumber,baiduAIClientList);
} catch (RedissonShutdownException rse) {
log.warn("【AI接口调用】终止!{}", rse.getMessage());
} catch (InterruptedException e) {
log.info("【AI接口调用】线程中断,执行失败");
}
return this;
}
/**
* 漏桶工作,递归处理溢出
*
* @param leakyBucketNumber - 漏桶编号
* @param baiduAIClientList - 调用百度client集合
*/
private void leakyBucketWork(Integer leakyBucketNumber, List<BaiduAIClient> baiduAIClientList) throws InterruptedException {
//单个桶流速信号量 命名:url.leakyBucketNumber
RPermitExpirableSemaphore semaphore = redissonClient.getPermitExpirableSemaphore(“单桶 + 编号”);
semaphore.trySetPermits(maxQPS);
String acquire = semaphore.tryAcquire(0,TIME_WINDOW, TimeUnit.MILLISECONDS);
if (Strings.isNotEmpty(acquire)) {
log.info("桶编号-{},获取到信号量:{},开始执行任务",leakyBucketNumber,acquire);
BaiduAIClient aiClient = baiduAIClientList.get(leakyBucketNumber);
this.jsonObject = aiClient.send(aipRequest);
} else if (leakyBucketNumber < baiduAIClientList.size() - 1) {
//溢出:流向下一个桶
leakyBucketNumber++;
leakyBucketWork(leakyBucketNumber,baiduAIClientList);
}
}