
负责的一个任务平台项目的spark版本是1.6.1的,主要变成语言是python;
现阶段要把spark从1.6.1 直接 升级到2.4.6版本,这期间遇到很多问题,特此记录:
1、语法兼容问题
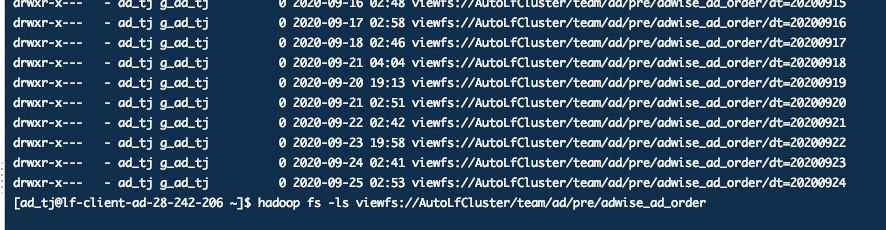
数据平台任务会分成天任务、小时任务,我们会把处理后的数据写入到hive的表里面(分区里面)
比如:
1.6版本使用的最终落地语法是:
source.write.format("orc").partitionBy(%s).insertInto("%s.%s", True)
当升级到2.4以后,报错:
insertInto() can't be used together with partitionBy()
因为在spark2.0以后,认为insertInto本身要插入的表是有分区的(分区是在创建表的时候指明的),所以不需要使用partitionBy
但是我们的表是需要进行分区插入的,比如:


CREATE EXTERNAL TABLE `ad.adwise_ad_order`( `sdate` int COMMENT '日期', `order_id` string COMMENT '广告订单ID', `req_num` bigint COMMENT '广告请求量', `imp_filter_pv` bigint COMMENT '广告展现过滤PV', `click_filter_pv` bigint COMMENT '广告点击过滤PV', `imp_num` bigint COMMENT '广告曝光量', `vis_req_num` bigint COMMENT '广告可见请求量', `vis_imp_num` bigint COMMENT '广告可见曝光量', `vis_display_num` bigint COMMENT '广告可见展现量', `click_num` bigint COMMENT '广告点击量', `lands_num` bigint COMMENT '广告线索量', `req_uv` bigint COMMENT '广告请求UV', `imp_uv` bigint COMMENT '广告曝光UV', `imp_login_uv` bigint COMMENT '广告曝光会员数', `vis_req_uv` bigint COMMENT '广告可见请求UV', `vis_imp_uv` bigint COMMENT '广告可见曝光UV', `vis_imp_login_uv` bigint COMMENT '广告可见曝光会员数', `lands_uv` bigint COMMENT '广告线索UV', `click_uv` bigint COMMENT '广告点击UV', `lands_login_uv` bigint COMMENT '广告线索会员数') PARTITIONED BY ( `dt` string) ROW FORMAT SERDE 'org.apache.hadoop.hive.ql.io.orc.OrcSerde' WITH SERDEPROPERTIES ( 'colelction.delim'=',', 'field.delim'=' ', 'line.delim'=' ', 'mapkey.delim'=':', 'serialization.format'=' ') STORED AS INPUTFORMAT 'org.apache.hadoop.hive.ql.io.orc.OrcInputFormat' OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.orc.OrcOutputFormat' LOCATION 'viewfs://AutoLfCluster/team/ad/pre/adwise_ad_order' TBLPROPERTIES ( 'transient_lastDdlTime'='1512551282')
1.1、saveAsTable导致所有分区被覆盖
于是查了下API,发现partitionBy和saveAsTable是可以组合的,于是无脑将代码改成:
df.write.mode("override").partitionBy(['dt', 'hour']).saveAsTable("XXXXX")
因为没有拿临时表做测试,自以为跑的没问题了,结果结果第二天发现,表的分区被覆盖了
ps.这里提供个脚本,可以吧被覆盖掉的分区文件挂回来
#! /bin/bash #倒序按天遍历日期 #传入遍历的开始时间和结束时间 startdate="$1" enddate="$2" echo 'startdate: '$startdate echo 'enddate: '$enddate echo "-----------------------------------" #序列1-300,表示遍历300次,因为有结束时间的限制,所以实际上不会循环300次 for i in `seq 1 300`; do #当开始时间小于结束时间时,直接结束脚本 if [[ $startdate -lt $enddate ]]; then break fi echo $startdate #执行hiveSQL脚本,我是需要按日期执行hiveSQL,这里可以无视 hive -e "alter table ad.clues_unable_distribute add partition(dt='$startdate');" #每次执行后,使开始日期减一天,如果要正序,将下面-1换成+1即可,当然开始时间和结束时间也要换一下 startdate=$(date -d "$startdate -1 day" +%Y%m%d) done
1.2、saveAsTable导致元数据不一致问题
上面把表的分区覆盖,通过脚本挂回分区,回滚代码、切换回1.6版本后,我们的业务同事在其中一个表上添加了一个字段,暂且认为,在tableA上添加一个column1;
业务人员精心写的SQL,在hive的客户端是跑是完全没问题的,于是提交代码,上线...
然后这个任务就不断的报错,报错的内容就是,新添加的这个column1在tableA这个表中找不到这列;
然后在zeppline上执行业务SQL,发现依然是找不到这个column1这个列。这说明spark的meta和hive的meta不一致了!
然后在jira上说,在你数据插入完成后(insertInto),你应该刷新一下表;
API是:
spark.catalog.refreshTable()
排列是这样的:
1 df.write.option("nullValue", "").mode("overwrite").insertInto("%s.%s",True) 2 spark.catalog.refreshTable()
然后发现不管用;
依次尝试了
1 df.write.option("nullValue", "").mode("overwrite").insertInto("%s.%s",True) 2 spark.sql("alter table xxx add if not exists partition(a=b,c=d)")
以上均是不可以的,最后发现,是saveAsTable把之前的删除掉,覆盖了。导致这个表很特殊,无法同步hive的meta信息
于是表drop掉,重新创建外部表,在把分区重新挂回来,这样新添加的字段就出来了,注意:以上问题就是因为saveAsTable覆盖表造成的
1.3、InsertInto(db.table , false)导致的数据倾斜
以上方案行不通之后,我把插入语句改成了:
InsertInto(db.table , false)
第二个参数是false,意思是不覆盖;然后发现数据分区的确不会被覆盖了,但是会出现数据全都跑到一个分区里面了。而且是追加模式,导致数据倾斜
1.4、最终解决
最终搞定的方式代码直接发出来,核心就是:
spark.sql.sources.partitionOverwriteMode
最终插入代码:
#!/usr/bin/python # -*- coding:utf-8 -*- # describe: local csv to hive orc # create:%s import os os.environ['SPARK_HOME']="/data/sysdir/servers/spark-2.4.6-bin-2.7.2-scala2.11" from pyspark.sql import SparkSession from pyspark.sql.functions import * from pyspark.sql import HiveContext import sys reload(sys) sys.setdefaultencoding( "utf-8" ) spark = SparkSession.builder.appName("%s").config("spark.sql.sources.partitionOverwriteMode","dynamic").enableHiveSupport().getOrCreate() hiveContext = HiveContext(spark) hiveContext.sql("SET hive.exec.dynamic.partition = true") hiveContext.sql("SET hive.exec.dynamic.partition.mode = nonstrict") sink = hiveContext.table("%s.%s") df = hiveContext.read.format("com.autohome.databricks.spark.csv")%s.option("treatEmptyValuesAsNulls", "true").option("header","false").option('delimiter', '\t').load("file://%s", schema=sink.schema).repartition(1) #增加分区的值 此前为空 for i in zip([%s],[%s]): df = df.withColumn(i[0], when(df[i[0]] != i[1], i[1]).otherwise(i[1])) df.write.option("nullValue", "").mode("overwrite").insertInto("%s.%s",True) spark.sparkContext.stop() ''' % (date, db+'.'+table+'.'+date,db, table,nullDealingStr,datafilepath,partitions, pvalues, db, table)
insertInto和saveAsTable区别
这里简单说明下两种API的区别:
首先看下API的源码介绍:
1):insertInto
insertInto的官方声明
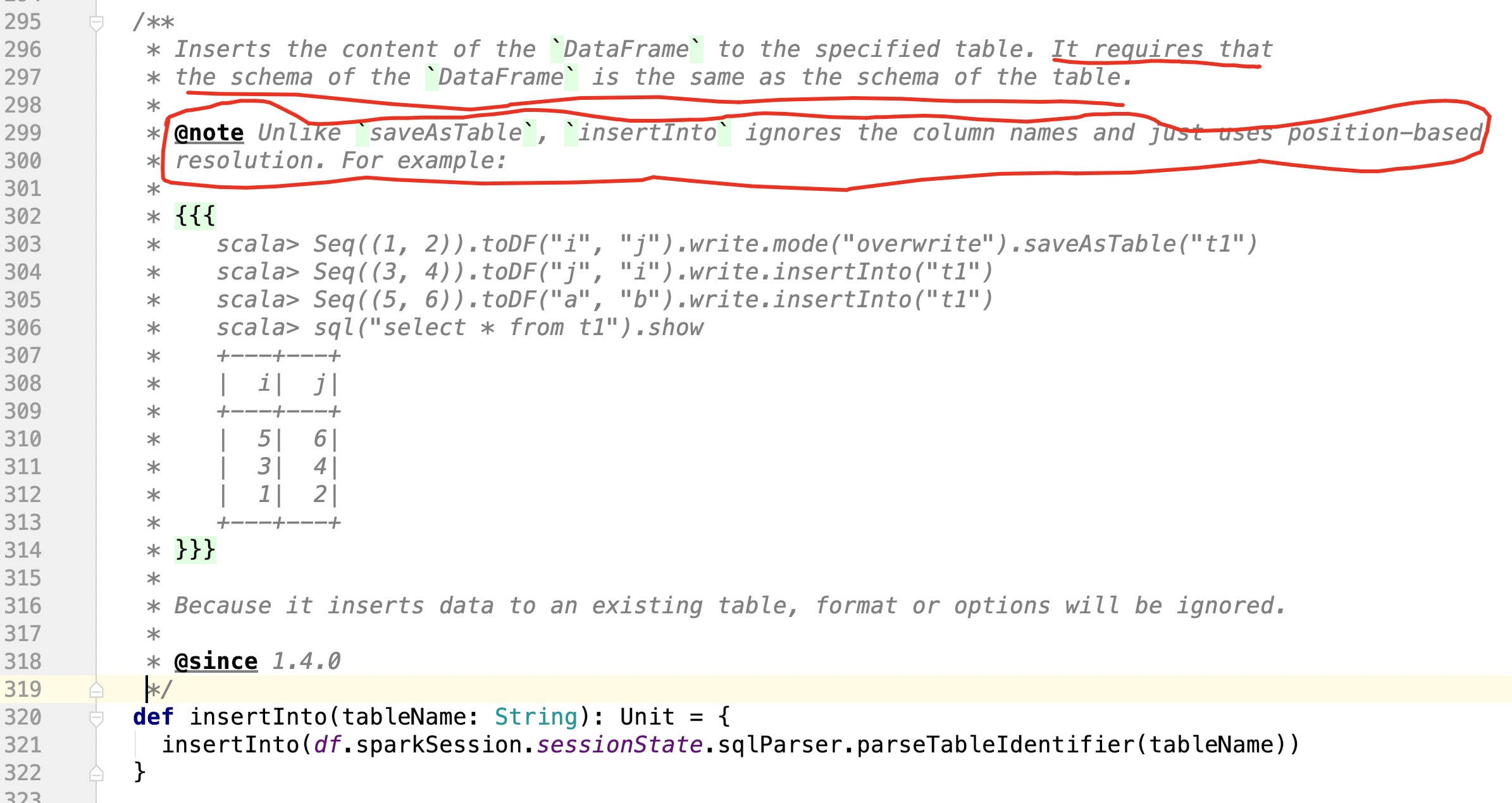
上面声明了2点信息:
1、spark-sql插入数据的时候,使用的是DataFrame,那么这个DataFrame的chema必须要和目标表(要插入的表)的schema信息一致
2、insertInto和saveAsTable不一样,insertInto是通过适应位置来进行数据插入的
上面两点声明很让人懵逼,因为感觉是矛盾的;但是只要记住一点,就能理解上面说的问题了:
insertInto使用的前提是这个表是存在的,它是在这个表的基础上进行插入的
saveAsTable是不依赖于这个表是否存在的,并且saveAsTable在写表的数据时候,是按照字段名称进行匹配插入的
2、spark2.0以后不支持pyspark提交脚本问题
有很多作业是使用pyspark进行提交的。但是在需要注意,2.0以后,spark不支持使用pyspark来 提交脚本了,所以要把pyspark统一改成spark-submit来提交脚本
3、phoenix版本不兼容问题
重新编译即可,百度搜索一大段
4、csv文件不支持Map问题
解决连接: https://www.cnblogs.com/niutao/p/13674489.html
git代码地址:https://github.com/niutaofan/pareCSV.git
5、处理CSV的时候,关于双引号" 导致格式无法识别问题
跟处理“csv文件不支持Map问题”的解决方式一样,出现的问题是spark处理csv的代码,主要是:commons-csv代码。
那么在通过自定义数据源的时候,spark会对csv文件进行扫描,代码:
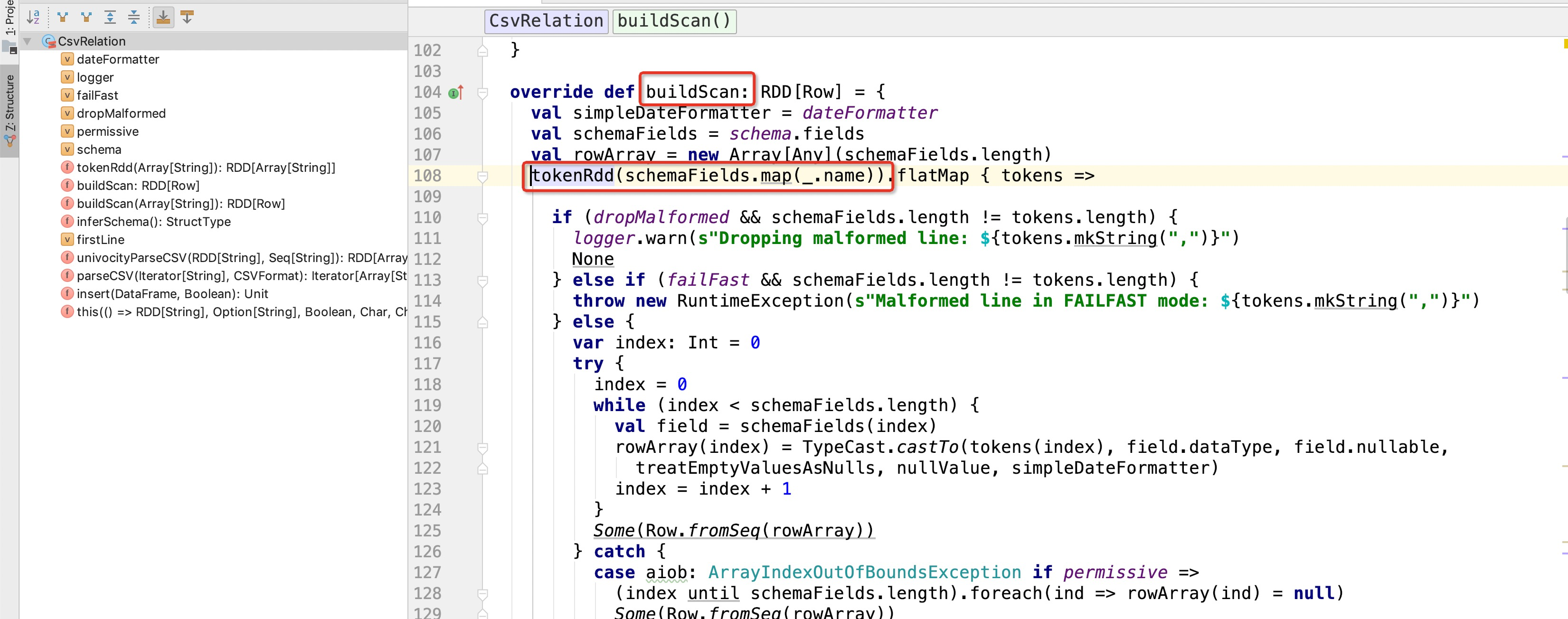
通过tokenRdd来扫描每一行数据,生成rdd,问题就出现在这个方法里面:
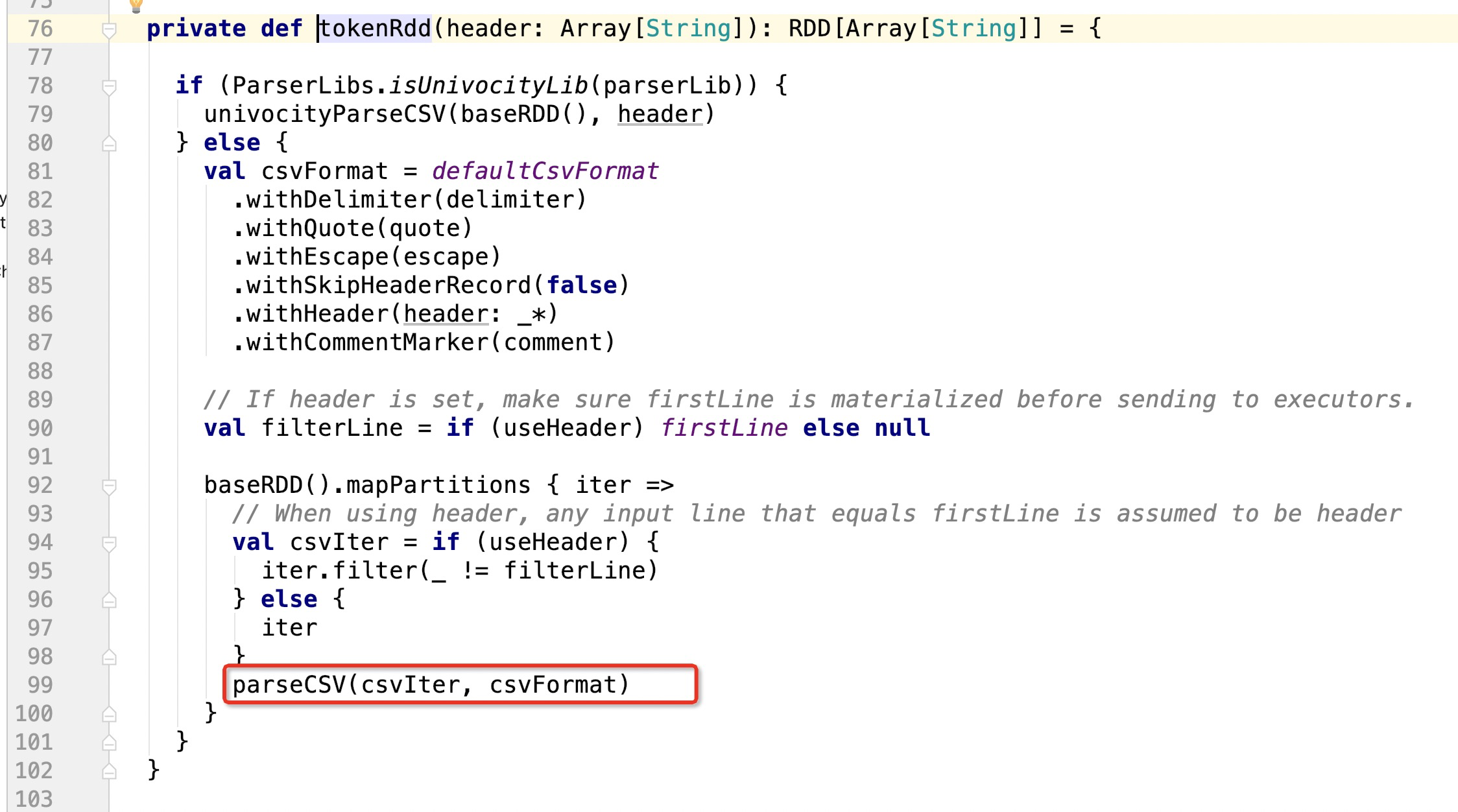
上面parseCSV就对每一行csv数据做解析,然后返回RDD
无法解析特殊字符的报错,就是这个方法里面:
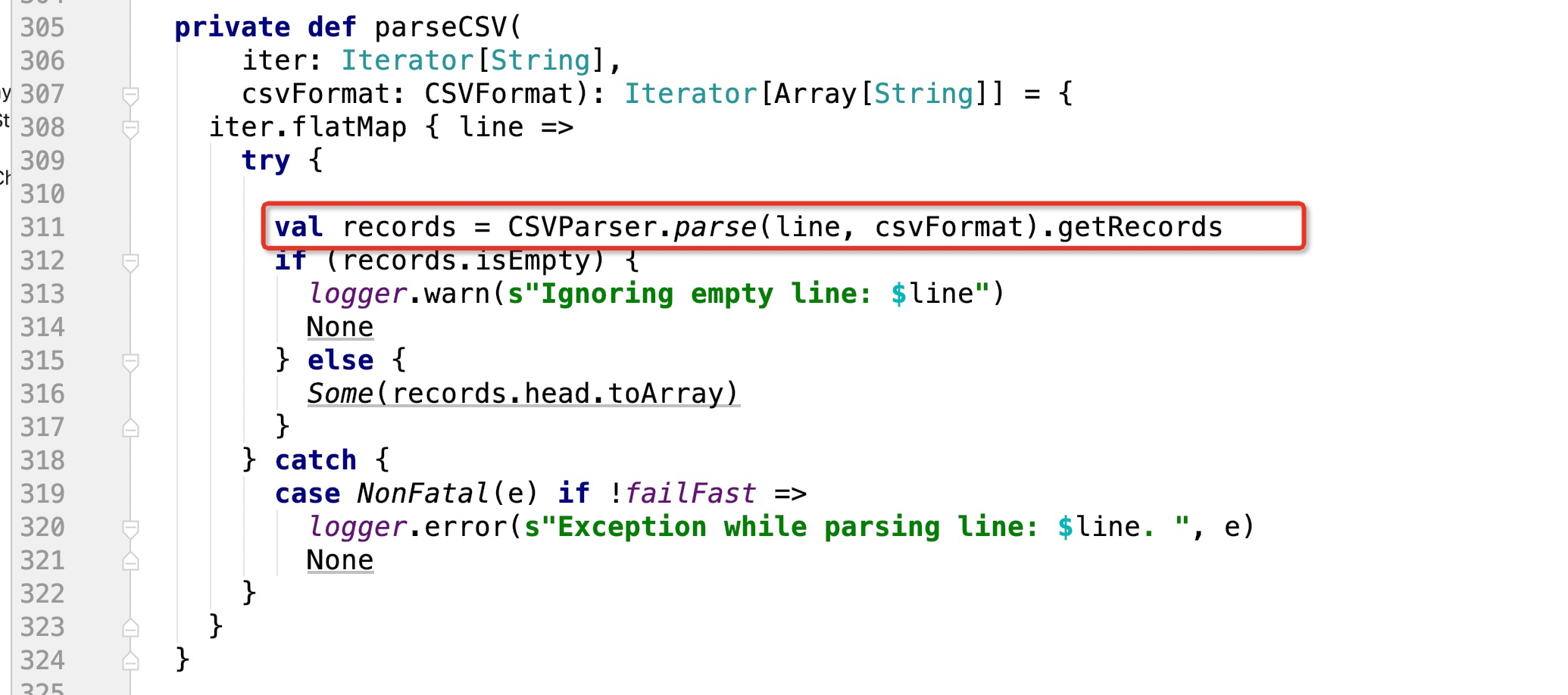
可以看到311行代码,CSVParser.parse(line, csvFormat).getRecords ,这里面的line就是每一行数据
因为我这边报错是类似一行csv数据中有一些非法的字符,比如字符串:

所以,简单对这一行代码做修改处理即可,比如:
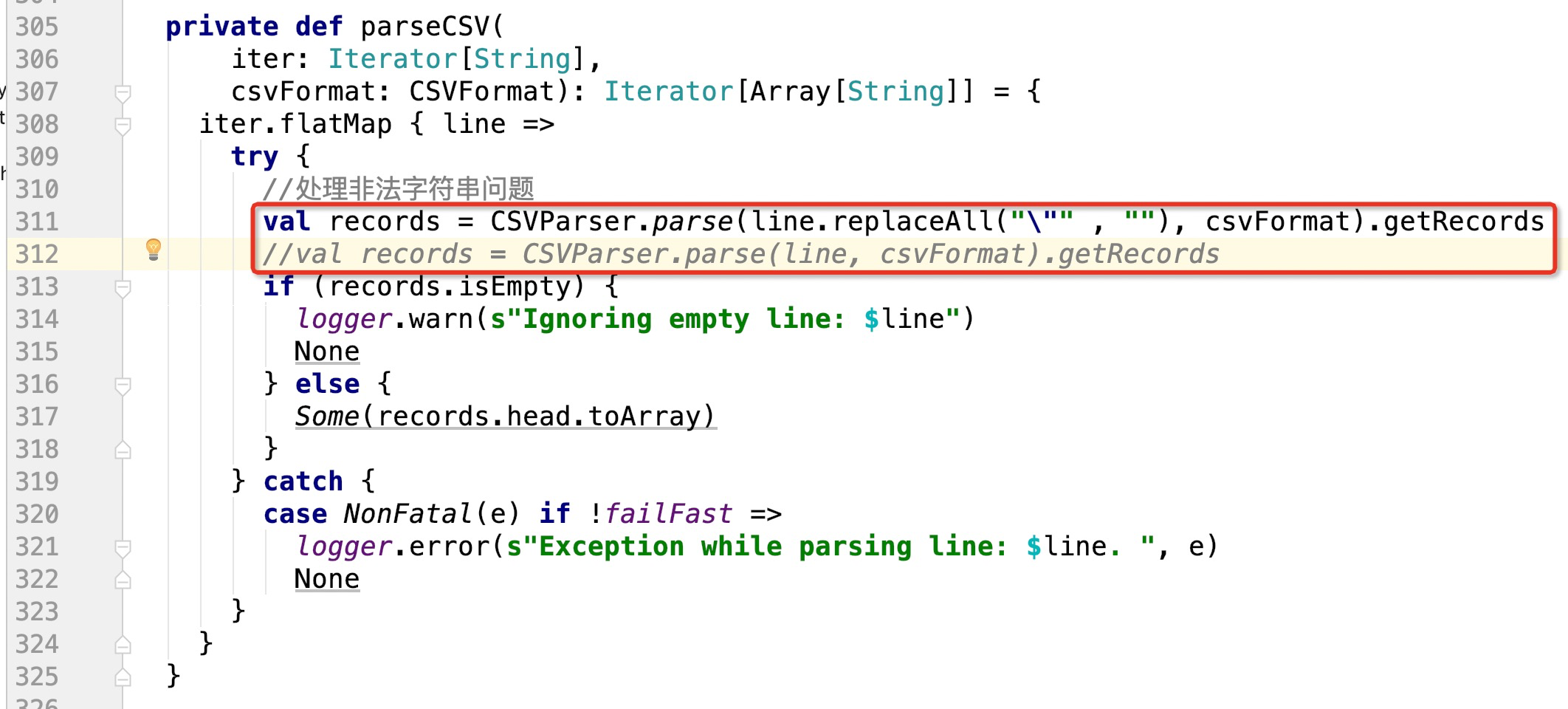
这样就可以解决csv每一行中非法的双引号问题了!