一、前言
由于线下测试的需要,需要在公司线下(测试)环境搭建大数据集群。
那么CDH是什么?
hadoop是一个开源项目,所以很多公司再这个基础上进行商业化,不收费的hadoop版本主要有三个,分别是:
(1)Apache,最原始的版本,所有发行版均基于这个版本进行改进
缺点:版本部署混乱,部署过程繁杂,升级过程繁杂,兼容性差,安全性差
(2)CDH版本,在Apache基础上,进行了封装,处理了不同版本的兼容问题。有用户管理界面
(3)Hotnowork版本。
由于公司测试环境的内存有限(8G),cloudera manager需要大量的内存运行服务,所以这里我们选择cdh的tar包安装的方式
二、集群准备
至少三台linux机器,我的配置是:
Linux软件版本:Red Hat Enterprise Linux Server release 6.8 (Santiago)
硬件配置:8核 8G内存120G磁盘空间
一下操作三台机器都需要
(1)所有的安装包都在普通用户下安装,所以要新增一个用户:
useradd hadoop
passwd hadoop
(2)设置普通用户hadoop的sudo权限(root用户)
chmod u+w /etc/sudoers
vi /etc/sudoers
(在首行加入)
hadoop ALL=(root)NOPASSWD:ALL
chmod u-w /etc/sudoers
(3)修改主机名(切换到普通hadoop用户)
sudo vi /etc/sysconfig/netword
(修改:)
HOSTNAME=hadoop001
(其他两台机器修改为hadoop002,hadoop003)
(4)Ip与主机名的映射
sudo vi /etc/hosts
(最末尾加入)
hadoop001 10.7.131.1
hadoop002 10.7.131.2
hadoop003 10.7.131.3
(5)关闭防火墙
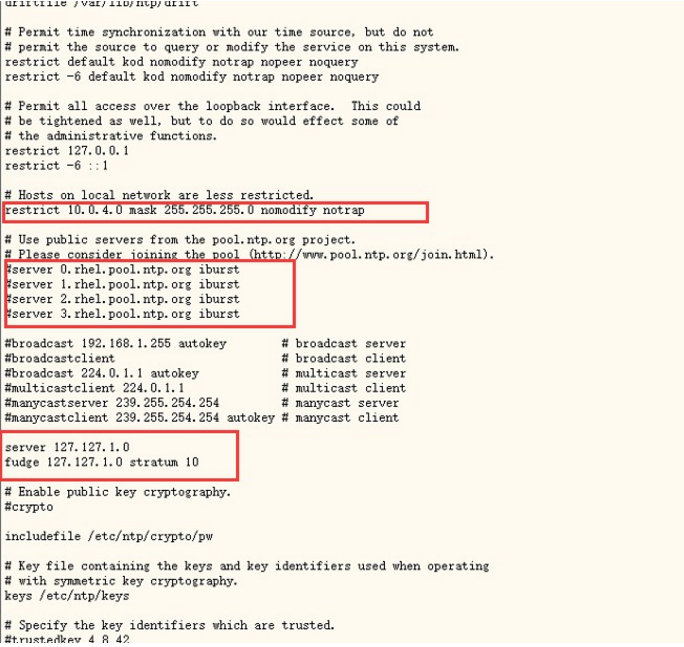
第一个红框处:
restrict 后面的变成机器的网段,比如目前的机器ip是10.7.131.1,那么就填入10.7.131.0
第二个红框处:
注释掉原来的
第三个红框处:
去掉两行注释
sudo vi /etc/sysconfig/ntpd
(首行加入)
SYNC_HWCLOCK=yes
启动ntpd服务
sudo service ntpd status
sudo service ntpd start
sudo chkconfig ntpd on
让hadoop001时间和国家授时中心保持同步(root用户)
三、安装hadoop
1.目录准备
在hadoop用户目录下,规划好目录
app 应用软件安装的地方
software 应用软件包
shell 运行的脚本
data 所有的数据
1.下载hadoop 安装包
http://archive.cloudera.com/cdh5/cdh/5/
所有大数据组件都可以从这里下载到
打开,找到hadoop-2.6.0-cdh5.11.1.tar.gz,下载到本地,并上传到服务器上/home/hadoop/software下
2.解压
tar -zxvf /home/hadoop/software/hadoop-2.6.0-cdh5.11.1.tar.gz -C /home/hadoop/app/
mv /home/hadoop/software/hadoop-2.6.0-cdh5.11.1.tar.gz hadoop
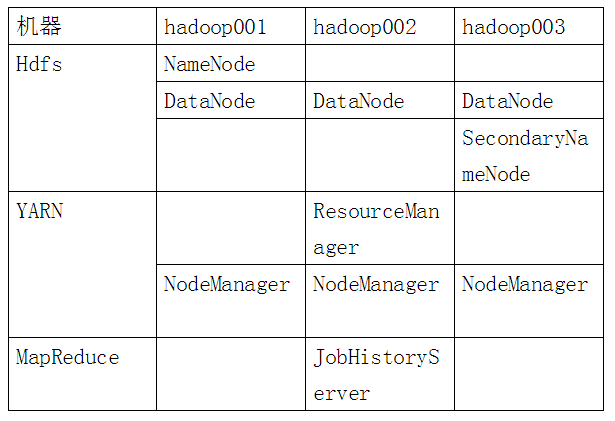
3.hadoop各组件规划
4.配置
1.创建hadoop临时目录
mkdir -p /home/hadoop/app/hadoop/tmp
2.修改hadoop-env.sh
export JAVA_HOME=/home/hadoop/app/jdk
3.修改core-site.xml(/home/hadoop/app/hadoop/etc/hadoop)
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop001:8020</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/home/hadoop/app/hadoop/tmp</value>
</property>
<property>
<name>fs.trash.interval</name>
<value>4320</value>
</property>
<property>
<name>hadoop.proxyuser.hue.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.hue.groups</name>
<value>*</value>
</property>
</configuration>
3.修改hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>hadoop002:50090</value>
</property>
</configuration>
4.修改mapred-env.sh
同样是修改jdk
export JAVA_HOME=/home/hadoop/app/jdk
5.修改mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>hadoop002:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>hadoop002:19888</value>
</property>
</configuration>
6.修改yarn-env.sh
if [ "$JAVA_HOME" != "" ]; then
#echo "run java in $JAVA_HOME"
JAVA_HOME=/home/hadoop/app/jdk
fi
7.修改yarn-site.xml
<configuration>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop002</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>4096</value>
</property>
<property>
<name>yarn.nodemanager.resource.cpu-vcores</name>
<value>4</value>
</property>
<!--下面两个配置使日志聚集功能,使日志上传到hdfs上-->
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>640800</value>
</property>
</configuration>
8.格式化hdfs文件系统
bin/hdfs namenode -format
9.启动hdfs
sbin/start-dfs.sh
10.验证
jps
11.启动yarn
sbin/start-yarn.sh
12.启动jobhistoryserver,运行oozie任务的时候,需要
sbin/mr-jobhistory-daemon.sh start historyserver
12.hdfs web界面访问
hadoop001:50070
13.yarn web界面访问
hadoop002:8088