一,环境选择
Hadoop需要运行在linux系统之下,所以有以下两种选择:1,安装双系统,缺点:此方式比较麻烦而且并不适合初学者,因为之后的安装以及配置过程可能会遇到许多问题,这需要我们上网去搜索、去解决,但是linux系统并不方便。优点:对于笔记本的配置要求不高,顺便可以学习转系统。2,安装虚拟机,如果你的本本配置较高,那么非常适合这种方式去学习Hadoop技术。
二,虚拟机和镜像文件的选择
本次教程采用的是VMware workstation,它是一款功能强大的桌面虚拟计算机软件,提供用户可在单一的桌面上同时运行不同的操作系统,和进行开发、测试 、部署新的应用程序的最佳解决方案。VMware Workstation可在一部实体机器上模拟完整的网络环境,以及可便于携带的虚拟机器,其更好的灵活性与先进的技术胜过了市面上其他的虚拟计算机软件。对于企业的 IT开发人员和系统管理员而言, VMware在虚拟网路,实时快照,拖曳共享文件夹,支持 PXE 等方面的特点使它成为必不可少的工具。
常见的linux系统有两种,Ubuntu和CentOS,Ubuntu是在一个虚拟化项目中接触的,适合个人用户桌面使用,有人玩得比较炫酷,Red Hat发布的开源版本CentOS被我们越来越多的应用,性能不错,相对也稳定,免费但没有什么官方支持。本次教程采用的是Ubuntu镜像文件运行在VMware workstations下。
以上的VMware workstation虚拟机和Ubuntu镜像文件在网上可以找到,下载和安装和简单,此处不作说明。
三,安装ubuntu系统
1,Ubuntu下载地址:我的下载地址:http://releases.ubuntu.com/14.04/ubuntu-14.04.5-desktop-amd64.iso
更多下载地址:https://blog.csdn.net/llCnll/article/details/78717903
2,安装Ubuntu:
1.打开VMware,选择创建新的虚拟机->典型(推荐)->下一步
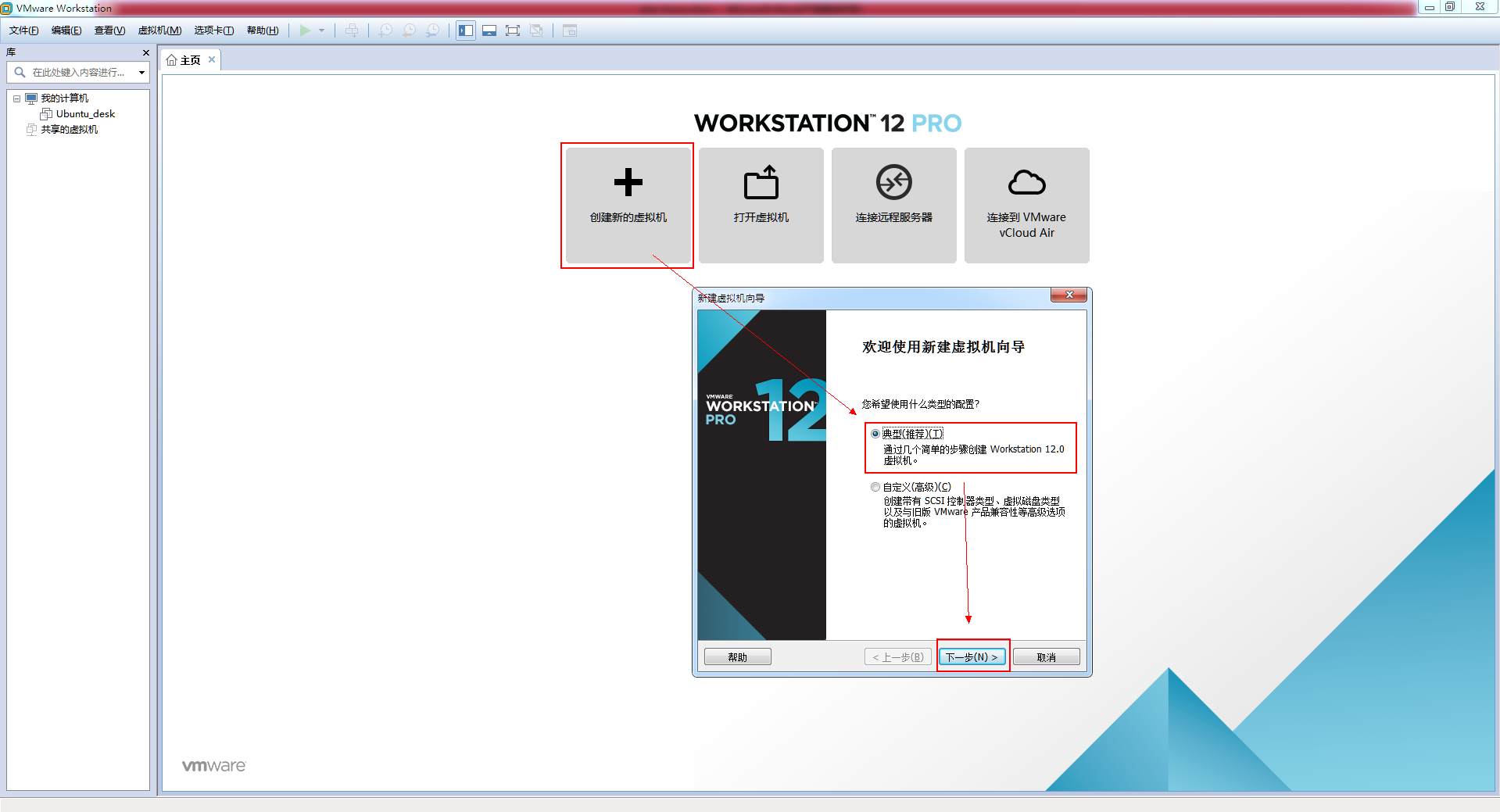
2.找到下载的镜像文件
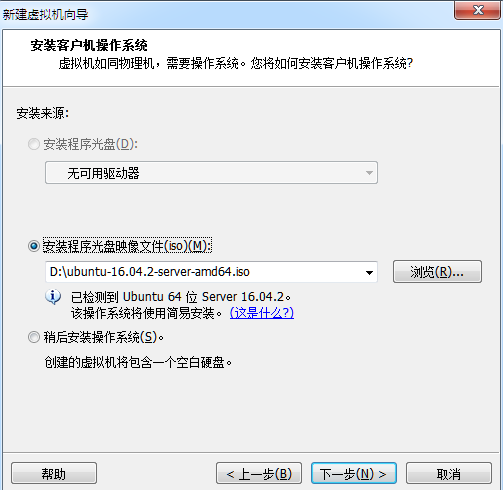
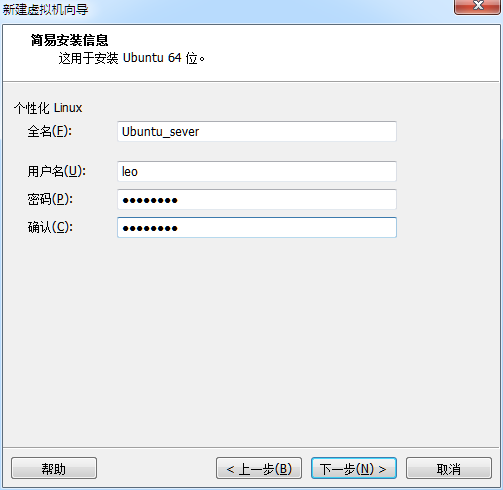
3.设置全名、用户名和密码(注意要记住用户名和密码,之后会用到)
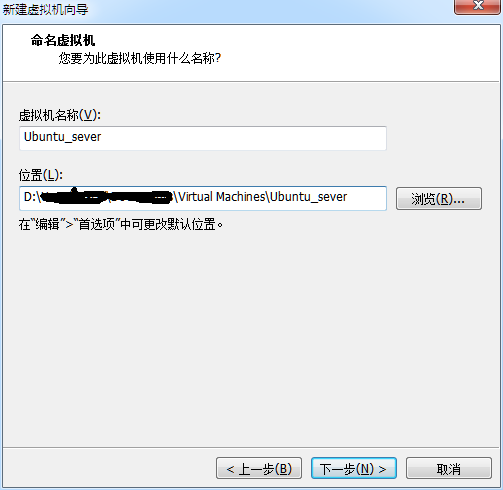
4.选择虚拟机存放位置(别放C盘就行,尽量路径不含中文)
5.默认是20个g,初学者建议20g足够了。如果要在Ubuntu上开发,需要分配至少1.5个g的运行内存

6.按照默认,完成

7.设置完毕后它会自动运行虚拟机。此时会报错,不用管,之后会解决
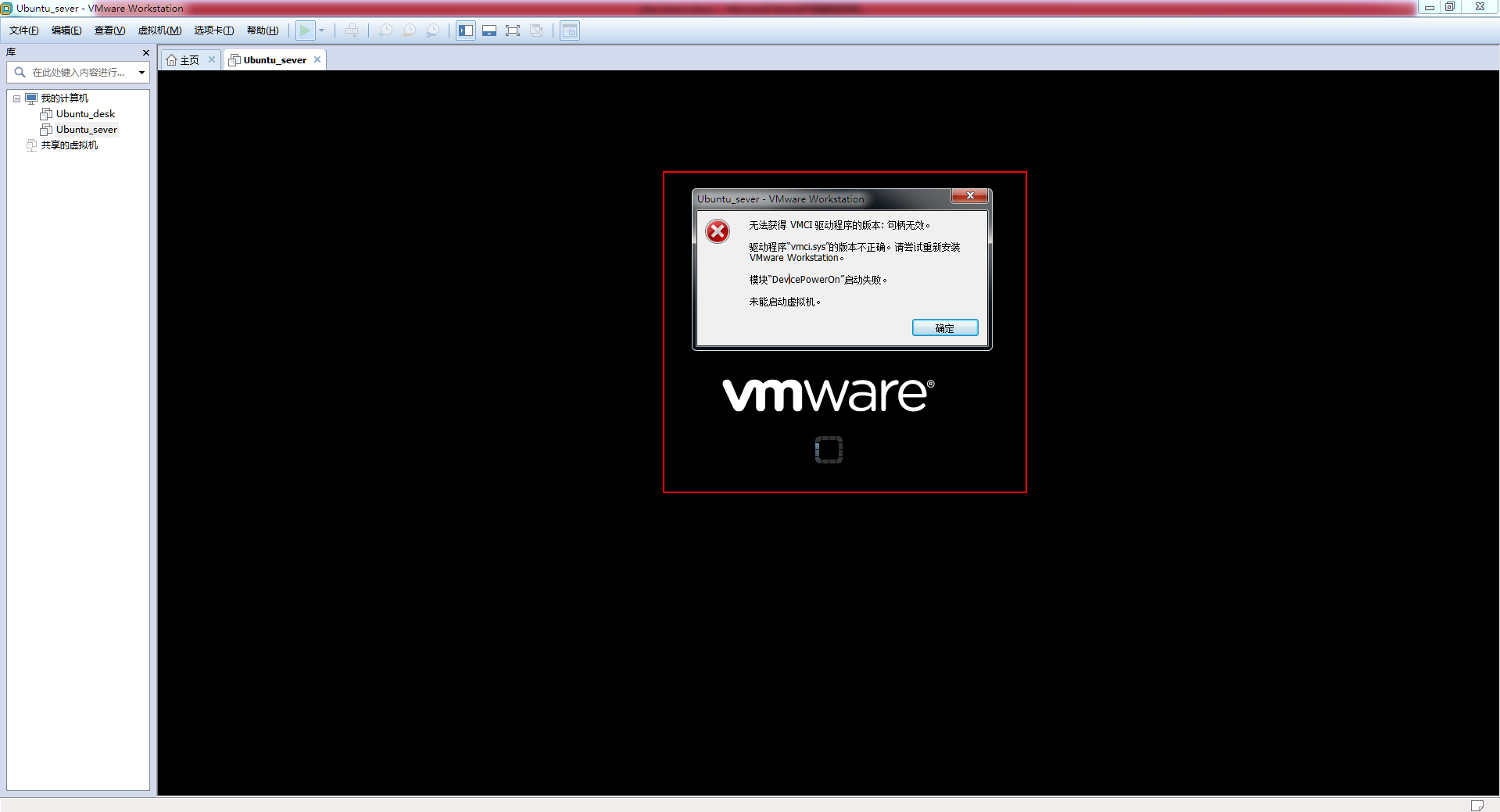
8.找到虚拟机对应路径的文件夹,路径在下方红框内

9.找到一个.vmx的文件,右键,用文本形式打开
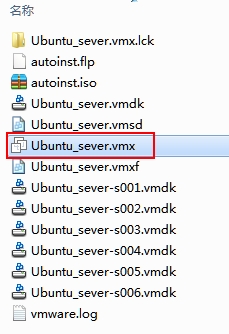
10.找到【vmci0.present = "TRUE"】,修改成FALSE。关闭文件。再次运行虚拟机,就可以了。
11.接下来就是自动安装阶段了。等待大约半个小时,系统就自动安装完毕啦~
参考:https://www.cnblogs.com/6luv-ml/p/6510736.html
注:记住自己设置的用户名和密码,之后需要登录使用。
四,Hadoop的安装和配置
1,创建hadoop用户
如果你安装 Ubuntu 的时候不是用的 “hadoop” 用户,那么需要增加一个名为 hadoop 的用户。
首先按 ctrl+alt+t 打开终端窗口,输入如下命令创建新用户 :
sudo useradd -m hadoop -s /bin/bash 这条命令创建了可以登陆的 hadoop 用户,并使用 /bin/bash 作为 shell。
接着设置密码,密码输入两次:sudo passwd hadoop
为 hadoop 用户增加管理员权限,方便部署,避免一些对新手来说比较棘手的权限问题:sudo adduser hadoop sudo
最后注销,用新用户重新登录。
2,更新apt
用 hadoop 用户登录后,我们先更新一下 apt,后续我们使用 apt 安装软件,如果没更新可能有一些软件安装不了。按 ctrl+alt+t 打开终端窗口,执行如下命令:sudo apt-get update
后续需要更改一些配置文件,建议安装一下vim(如果你实在还不会用 vi/vim 的,请将后面用到 vim 的地方改为 gedit,这样可以使用文本编辑器进行修改,并且每次文件更改完成后请关闭整个 gedit 程序,否则会占用终端):sudo apt-get install vim

3,安装SSH、配置SSH无密码登录(以后在登录本机或是开启结点时,需要每次都输入密码,这样显得比较麻烦,因此配置无密码登录)
详细请参考此博客的其他随笔(安装SSH、配置SSH无密码登录)
4,安装Hadoop
Hadoop 2 可以通过 http://mirror.bit.edu.cn/apache/hadoop/common/ 或者http://mirrors.cnnic.cn/apache/hadoop/common/ 下载,一般选择下载最新的稳定版本,即下载 “stable” 下的 hadoop-2.x.y.tar.gz 这个格式的文件,这是编译好的,另一个包含 src 的则是 Hadoop 源代码,需要进行编译才可使用。
下载时强烈建议也下载 hadoop-2.x.y.tar.gz.mds 这个文件,该文件包含了检验值可用于检查 hadoop-2.x.y.tar.gz 的完整性,否则若文件发生了损坏或下载不完整,Hadoop 将无法正常运行。
本文涉及的文件均通过浏览器下载,默认保存在 “下载” 目录中(若不是请自行更改 tar 命令的相应目录)。另外,本教程选择的是 2.6.0 版本,如果你用的不是 2.6.0 版本,则将所有命令中出现的 2.6.0 更改为你所使用的版本。
- cat ~/下载/hadoop-2.6.0.tar.gz.mds | grep 'MD5' # 列出md5检验值
- # head -n 6 ~/下载/hadoop-2.7.1.tar.gz.mds # 2.7.1版本格式变了,可以用这种方式输出
- md5sum ~/下载/hadoop-2.6.0.tar.gz | tr "a-z" "A-Z" # 计算md5值,并转化为大写,方便比较
若文件不完整则这两个值一般差别很大,可以简单对比下前几个字符跟后几个字符是否相等即可,如下图所示,如果两个值不一样,请务必重新下载。
检验文件完整性,我们选择将 Hadoop 安装至 /usr/local/ 中:
- sudo tar -zxf ~/下载/hadoop-2.6.0.tar.gz -C /usr/local # 解压到/usr/local中
- cd /usr/local/
- sudo mv ./hadoop-2.6.0/ ./hadoop # 将文件夹名改为hadoop
- sudo chown -R hadoop ./hadoop # 修改文件权限
Hadoop 解压后即可使用。输入如下命令来检查 Hadoop 是否可用,成功则会显示 Hadoop 版本信息:
- cd /usr/local/hadoop
- ./bin/hadoop version
参考:https://www.cnblogs.com/shijiaoyun/p/5796819.html和林子雨《大数据原理与应用》
tip:在实现hadoop的配置时,若出现no file or directory,一般是文件路径的问题,在编写linux命令的时候,在前面加上cd /usr/local/hadoop(此参考教程省去了),经过长时间找到错误,以提醒大家少走弯路。