准备:
<dependency> <groupId>us.codecraft</groupId> <artifactId>webmagic-core</artifactId> <version>0.7.3</version> </dependency> <dependency> <groupId>us.codecraft</groupId> <artifactId>webmagic-extension</artifactId> <version>0.7.3</version> </dependency>
● PageProcessor
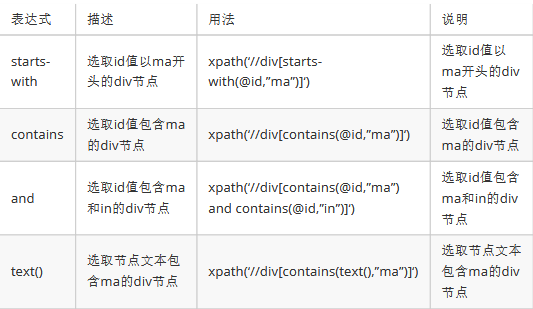
1.例:爬取id为nav的节点下的div节点下的div节点下的ul下的第5个li节点下的a节点
package com.tenpower.demo; import us.codecraft.webmagic.Page; import us.codecraft.webmagic.Site; import us.codecraft.webmagic.Spider; import us.codecraft.webmagic.pipeline.ConsolePipeline; import us.codecraft.webmagic.pipeline.FilePipeline; import us.codecraft.webmagic.pipeline.JsonFilePipeline; import us.codecraft.webmagic.processor.PageProcessor; import us.codecraft.webmagic.scheduler.FileCacheQueueScheduler; import us.codecraft.webmagic.scheduler.QueueScheduler; import us.codecraft.webmagic.scheduler.RedisScheduler; /** * 爬取类 */ public class MyProcessor implements PageProcessor { public void process(Page page) { System.out.println( page.getHtml().xpath("//*[@id="nav"]/div/div/ul/li[5]/a" ).toString() ); } public Site getSite() { return null; } public static void main(String[] args) { } }
输出结果:
<a href="/nav/ai">人工智能</a>
2.添加目标地址,将当前页面里的所有链接都添加到目标页面中,从种子页面爬取到更多页面
page.addTargetRequests( page.getHtml().links().all() );
3.目标地址正则匹配。例:只爬博客的文章详细页内容,并提取标题
page.addTargetRequests( page.getHtml().links().regex("https://blog.csdn.net/[a-z 0-9 -]+/article/details/[0-9]{8}").all());
System.out.println(page.getHtml().xpath("//*[@id="mainBox"]/main/div[1]/div/div/div[1]/h1"));
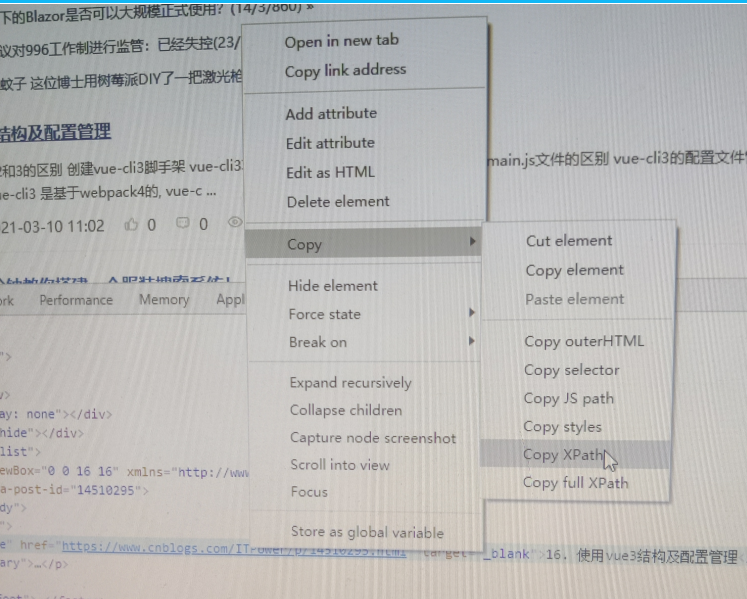
复制XPath方法:
1)浏览器F12选中某个节点

2)右键复制XPath
4.忽略html标签只提取文本
String nickname=page.getHtml().xpath("//*[@id="uid"]/text()").get();
5.只提取图片地址
String image=page.getHtml().xpath("//*[@id="asideProfile"]/div[1]/div[1]/a").css("img","src").toString();
● Pipeline
1.FilePipeline文件方式保存
public static void main(String[] args) { Spider.create( new MyProcessor() ) .addUrl("https://blog.csdn.net/") .addPipeline(new ConsolePipeline()) .addPipeline(new FilePipeline("e:/data")) .run(); }
2.自定义Pipeline
package com.tenpower.demo; import us.codecraft.webmagic.ResultItems; import us.codecraft.webmagic.Task; import us.codecraft.webmagic.pipeline.Pipeline; public class MyPipeline implements Pipeline { public void process(ResultItems resultItems, Task task) { String title = resultItems.get("title"); System.out.println("定制 title:"+title); } }
main方法添加Pipeline
public static void main(String[] args) { Spider.create( new MyProcessor() ) .addUrl("https://blog.csdn.net/") .addPipeline(new FilePipeline("e:/data")) .addPipeline(new MyPipeline()) .run(); }
● Scheduler
1.内存队列
public static void main(String[] args) { Spider.create( new MyProcessor() ) .addUrl("https://blog.csdn.net/") .setScheduler(new QueueScheduler()) .run(); }
2.文件队列。可以在关闭程序并下次启动时,从之前抓取到的URL继续抓取
public static void main(String[] args) { Spider.create( new MyProcessor() ) .addUrl("https://blog.csdn.net/") .setScheduler(new FileCacheQueueScheduler("E:\scheduler")) .run(); }
3.redis队列。可进行多台机器同时抓取
public static void main(String[] args) { Spider.create( new MyProcessor() ) .addUrl("https://blog.csdn.net/") .setScheduler(new RedisScheduler("127.0.0.1")) .run(); }
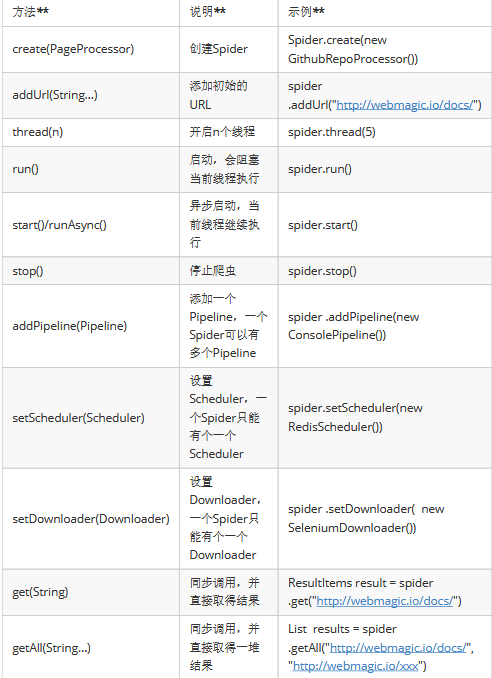
附1:Spider常用API
附2:Page常用API

附3:XPath语法
1.选取节点

2.谓语。查找某个特定的节点或者包含某个特定值的节点(须嵌套在方括号中)

3.通配符。选取未知的XML元素,通配指定节点
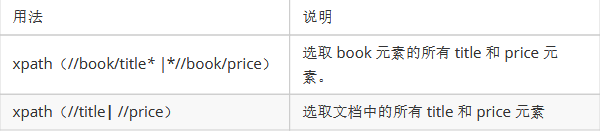
4.多路径选择
5.XPath轴。定义相对于当前节点的节点集
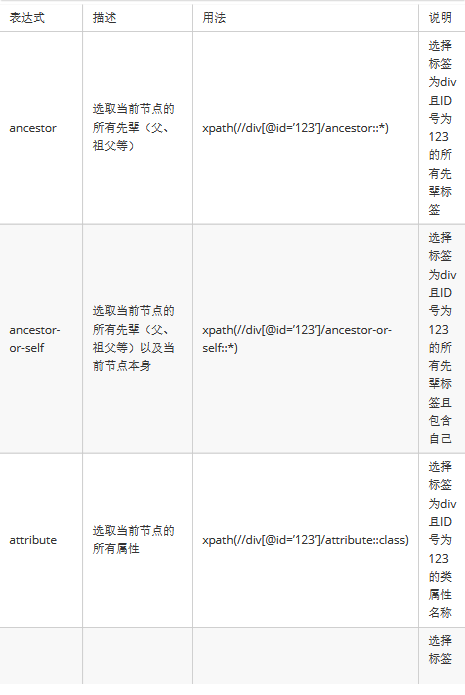

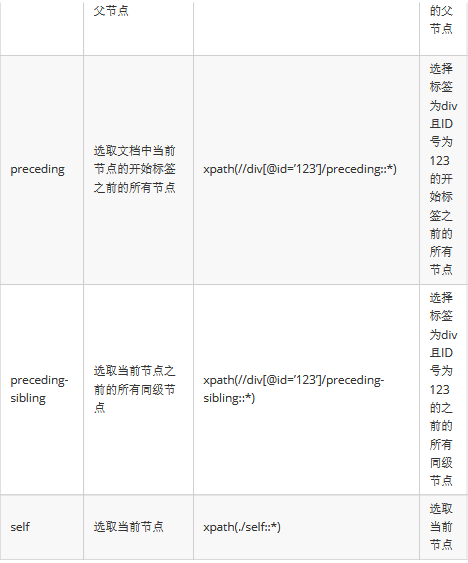
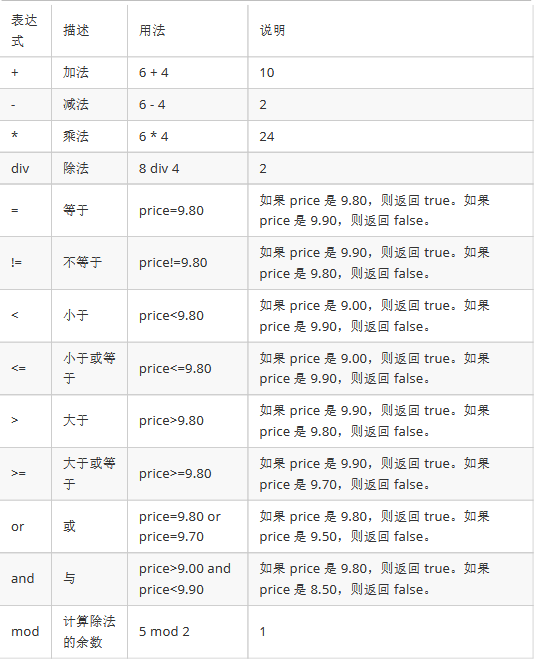
6.XPath运算符
7.常用功能函数。更好的进行模糊搜索