0.背景
使用 scrapy_redis 爬虫, 忘记或错误设置 request.priority(Rule 也可以通过参数 process_request 设置 request.priority),导致提取 item 的 request 排在有序集 xxx:requests 的队尾,持续占用内存。
1.代码实现
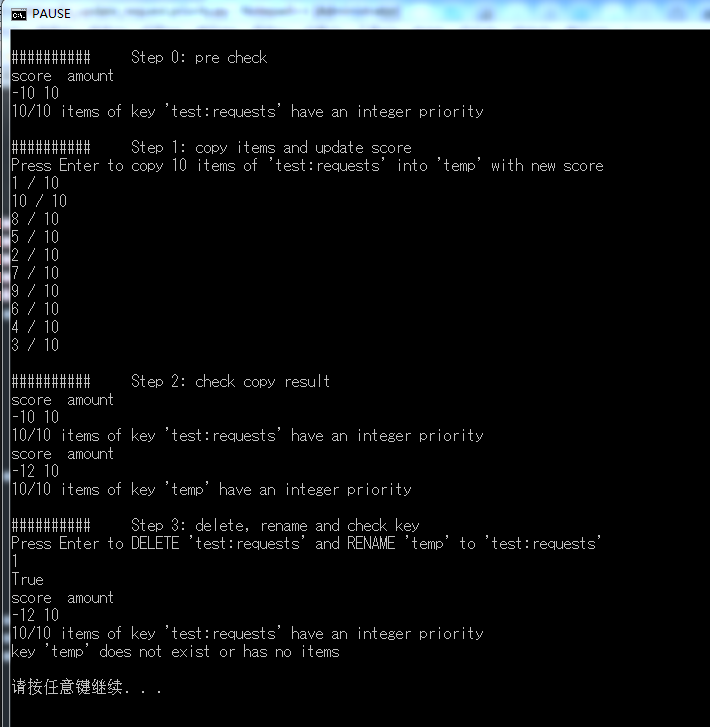
遍历 SortedSet 的所有 item 并根据预定义字典对 data 中的 url 进行正则匹配,更新 score 并复制到临时 newkey,最后执行 rename
# -*- coding: UTF-8 -* import sys import re from multiprocessing.dummy import Pool as ThreadPool from functools import partial try: input = raw_input #For py2 except NameError: pass import redis def print_line(string): print(' {symbol}{space}{string}'.format(symbol='#'*10, space=' '*5, string=string)) def check_key_scores(key): try: total = redis_server.zcard(key) except redis.exceptions.ResponseError: print("The value of '{key}' is not a SortedSet".format(key=key)) sys.exit() except Exception as err: print(err) sys.exit() if total == 0: print("key '{key}' does not exist or has no items".format(key=key)) sys.exit() __, min_score = redis_server.zrange(key, 0, 0, withscores=True)[0] __, max_score = redis_server.zrange(key, -1, -1, withscores=True)[0] print('score amount') total_ = 0 # Asuming that score/request.priority is an integer, rather than float number like 1.1 for score in range(int(min_score), int(max_score)+1): count = redis_server.zcount(key, score, score) print(score, count) total_ += count print("{total_}/{total} items of key '{key}' have an integer priority".format( total_=total_, total=total_, key=key)) def zadd_with_new_score(startstop, total_items): data, ori_score = redis_server.zrange(key, startstop, startstop, withscores=True)[0] for pattern, score in pattern_score: # data eg: b'\x80\x02}q\x00(X\x03\x00\x00\x00urlq\x01X\x13\x00\x00\x00http://httpbin.org/q\x02X\x08\x00\x00\x00callbackq\x03X\x # See /site-packages/scrapy_redis/queue.py # We don't use zadd method as the order of arguments change depending on # whether the class is Redis or StrictRedis, and the option of using # kwargs only accepts strings, not bytes. m = pattern.search(data.decode('utf-8', 'replace')) if m: redis_server.execute_command('ZADD', newkey, score, data) break else: redis_server.execute_command('ZADD', newkey, ori_score, data) print('{startstop} / {total_items}'.format( startstop=startstop+1, total_items=total_items)) if __name__ == '__main__': password = 'password' host = '127.0.0.1' port = '6379' database_num = 0 key = 'test:requests' newkey = 'temp' # Request whose url matching any key of keyword_score would be updated with the corresponding value as its score # Smaller value/score means higher request.priority keyword_score = {'httpbin': -12, 'apps/details': 1} pattern_score = [(re.compile(r'url.*?%s.*?callback'%k), v)for (k, v) in keyword_score.items()] threads_amount = 10 redis_server = redis.StrictRedis.from_url('redis://:{password}@{host}:{port}/{database_num}'.format( password=password, host=host, port=port, database_num=database_num)) print_line('Step 0: pre check') check_key_scores(key) print_line('Step 1: copy items and update score') # total_items = redis_server.zlexcount(key, '-', '+') total_items = redis_server.zcard(key) input("Press Enter to copy {total_items} items of '{key}' into '{newkey}' with new score".format( total_items=total_items, key=key, newkey=newkey)) p = ThreadPool(threads_amount) p.map(partial(zadd_with_new_score, total_items=total_items), range(total_items)) p.close() #Prevents any more tasks from being submitted to the pool. Once all the tasks have been completed the worker processes will exit. p.join() #Wait for the worker processes to exit. One must call close() or terminate() before using join(). # For py3 # https://stackoverflow.com/questions/5442910/python-multiprocessing-pool-map-for-multiple-arguments # with ThreadPool(threads_amount) as pool: # pool.map(partial(zadd_with_new_score, total_items=total_items), range(total_items)) # print('zadd_with_new_score done') print_line('Step 2: check copy result') check_key_scores(key) check_key_scores(newkey) print_line('Step 3: delete, rename and check key') input("Press Enter to DELETE '{key}' and RENAME '{newkey}' to '{key}'".format( key=key, newkey=newkey)) print(redis_server.delete(key)) print(redis_server.rename(newkey, key)) check_key_scores(key) check_key_scores(newkey)
2.运行结果