测试前提
我们在进行测试时,都会分清楚:
- 测试对象:要区分硬盘、SSD、RAID、SAN、云硬盘等,因为它们有不同的特点
- 测试指标:IOPS和MBPS(吞吐率),下面会具体阐述
- 测试工具:Linux下常用Fio、dd工具, Windows下常用IOMeter,
- 测试参数: IO大小,寻址空间,队列深度,读写模式,随机/顺序模式
- 测试方法:也就是测试步骤。
测试是为了对比,所以需要定性和定量。在宣布自己的测试结果时,需要说明这次测试的工具、参数、方法,以便于比较。
存储系统模型
为了更好的测试,我们需要先了解存储系统,块存储系统本质是一个排队模型,我们可以拿银行作为比喻。还记得你去银行办事时的流程吗?
- 去前台取单号
- 等待排在你之前的人办完业务
- 轮到你去某个柜台
- 柜台职员帮你办完手续1
- 柜台职员帮你办完手续2
- 柜台职员帮你办完手续3
- 办完业务,从柜台离开
如何评估银行的效率呢:
- 服务时间 = 手续1 + 手续2 + 手续3
- 响应时间 = 服务时间 + 等待时间
- 性能 = 单位时间内处理业务数量
那银行如何提高效率呢:
- 增加柜台数
- 降低服务时间
因此,排队系统或存储系统的优化方法是
- 增加并行度
- 降低服务时间
硬盘测试
硬盘原理
我们应该如何测试SATA/SAS硬盘呢?首先需要了解磁盘的构造,并了解磁盘的工作方式:

每个硬盘都有一个磁头(相当于银行的柜台),硬盘的工作方式是:
- 收到IO请求,得到地址和数据大小
- 移动磁头(寻址)
- 找到相应的磁道(寻址)
- 读取数据
- 传输数据
则磁盘的随机IO服务时间:
服务时间 = 寻道时间 + 旋转时间 + 传输时间
对于10000转速的SATA硬盘来说,一般寻道时间是7 ms,旋转时间是3 ms, 64KB的传输时间是 0.8 ms, 则SATA硬盘每秒可以进行随机IO操作是 1000/(7 + 3 + 0.8) = 93,所以我们估算SATA硬盘64KB随机写的IOPS是93。一般的硬盘厂商都会标明顺序读写的MBPS。
我们在列出IOPS时,需要说明IO大小,寻址空间,读写模式,顺序/随机,队列深度。我们一般常用的IO大小是4KB,这是因为文件系统常用的块大小是4KB。
使用dd测试硬盘
虽然硬盘的性能是可以估算出来的,但是怎么才能让应用获得这些性能呢?对于测试工具来说,就是如何得到IOPS和MBPS峰值。我们先用dd测试一下SATA硬盘的MBPS(吞吐量)。
#dd if=/dev/zero of=/dev/sdd bs=4k count=300000 oflag=direct
记录了300000+0 的读入 记录了300000+0 的写出 1228800000字节(1.2 GB)已复制,17.958 秒,68.4 MB/秒
#iostat -x sdd 5 10
...
Device: rrqm/s wrqm/s r/s w/s rsec/s wsec/s avgrq-sz avgqu-sz await svctm %util
sdd 0.00 0.00 0.00 16794.80 0.00 134358.40 8.00 0.79 0.05 0.05 78.82
...
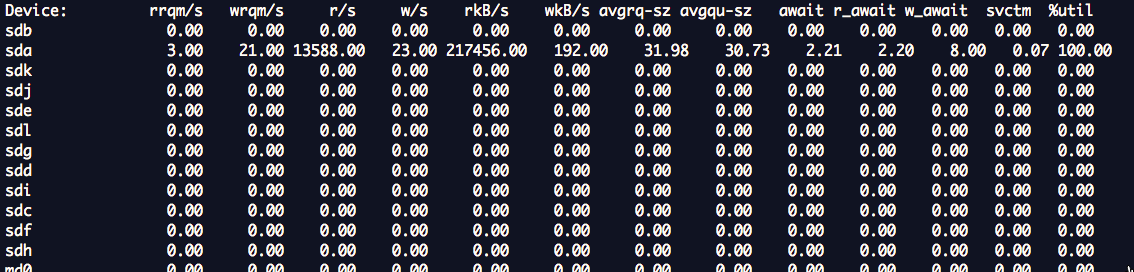
为什么这块硬盘的MBPS只有68MB/s? 这是因为磁盘利用率是78%,没有到达95%以上,还有部分时间是空闲的。当dd在前一个IO响应之后,在准备发起下一个IO时,SATA硬盘是空闲的。那么如何才能提高利用率,让磁盘不空闲呢?只有一个办法,那就是增加硬盘的队列深度。相对于CPU来说,硬盘属于慢速设备,所有操作系统会有给每个硬盘分配一个专门的队列用于缓冲IO请求。
队列深度
什么是磁盘的队列深度?
在某个时刻,有N个inflight的IO请求,包括在队列中的IO请求、磁盘正在处理的IO请求。N就是队列深度。
加大硬盘队列深度就是让硬盘不断工作,减少硬盘的空闲时间。
加大队列深度 -> 提高利用率 -> 获得IOPS和MBPS峰值 -> 注意响应时间在可接受的范围内
增加队列深度的办法有很多
使用异步IO,同时发起多个IO请求,相当于队列中有多个IO请求
多线程发起同步IO请求,相当于队列中有多个IO请求
增大应用IO大小,到达底层之后,会变成多个IO请求,相当于队列中有多个IO请求 队列深度增加了。
队列深度增加了,IO在队列的等待时间也会增加,导致IO响应时间变大,这需要权衡。让我们通过增加IO大小来增加dd的队列深度,看有没有效果:
dd if=/dev/zero of=/dev/sdd bs=2M count=1000 oflag=direct
记录了1000+0 的读入 记录了1000+0 的写出 2097152000字节(2.1 GB)已复制,10.6663 秒,197 MB/秒
Device: rrqm/s wrqm/s r/s w/s rsec/s wsec/s avgrq-sz avgqu-sz await svctm %util
sdd 0.00 0.00 0.00 380.60 0.00 389734.40 1024.00 2.39 6.28 2.56 97.42
可以看到2MB的IO到达底层之后,会变成多个512KB的IO,平均队列长度为2.39,这个硬盘的利用率是97%,MBPS达到了197MB/s。(为什么会变成512KB的IO,你可以去使用Google去查一下内核参数 max_sectors_kb的意义和使用方法 )
也就是说增加队列深度,是可以测试出硬盘的峰值的。
使用fio测试硬盘
现在,我们来测试下SATA硬盘的4KB随机写的IOPS。
$fio -ioengine=libaio -bs=4k -direct=1 -thread -rw=randwrite -size=1000G -filename=/dev/vdb
-name="EBS 4K randwrite test" -iodepth=64 -runtime=60
简单介绍fio的参数
ioengine: 负载引擎,我们一般使用libaio,发起异步IO请求。
bs: IO大小
direct: 直写,绕过操作系统Cache。因为我们测试的是硬盘,而不是操作系统的Cache,所以设置为1。
rw: 读写模式,有顺序写write、顺序读read、随机写randwrite、随机读randread等。
size: 寻址空间,IO会落在 [0, size)这个区间的硬盘空间上。这是一个可以影响IOPS的参数。一般设置为硬盘的大小。
filename: 测试对象
iodepth: 队列深度,只有使用libaio时才有意义。这是一个可以影响IOPS的参数。
runtime: 测试时长
下面我们做两次测试,分别 iodepth = 1和iodepth = 4的情况。下面是iodepth = 1的测试结果。
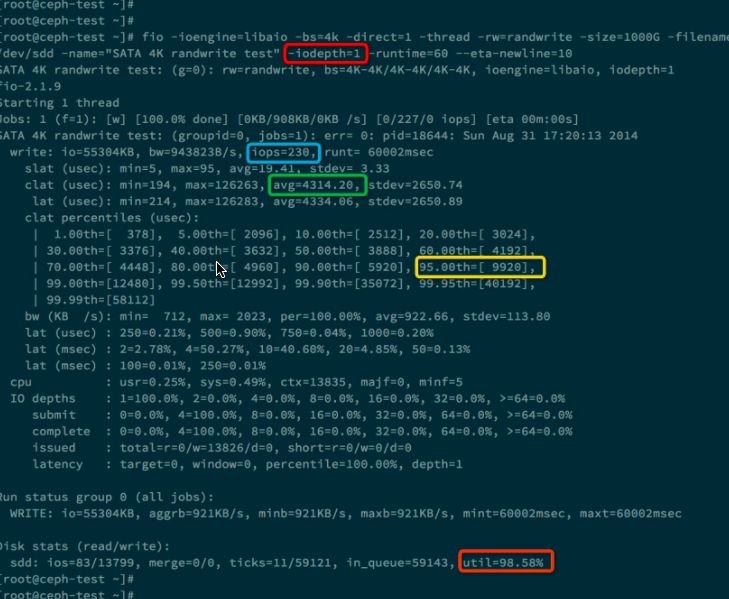
上图中蓝色方框里面的是测出的IOPS 230, 绿色方框里面是每个IO请求的平均响应时间,大约是4.3ms。黄色方框表示95%的IO请求的响应时间是小于等于 9.920 ms。橙色方框表示该硬盘的利用率已经达到了98.58%。
下面是 iodepth = 4 的测试:
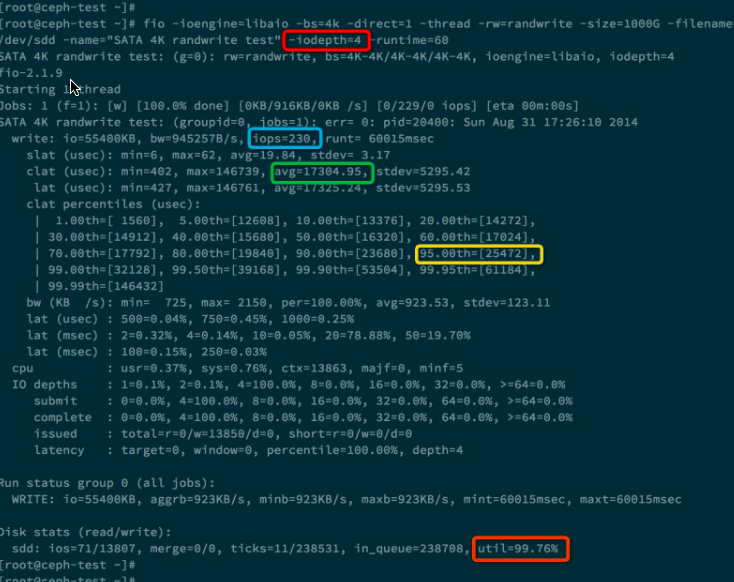
我们发现这次测试的IOPS没有提高,反而IO平均响应时间变大了,是17ms。
为什么这里提高队列深度没有作用呢,原因当队列深度为1时,硬盘的利用率已经达到了98%,说明硬盘已经没有多少空闲时间可以压榨了。而且响应时间为 4ms。 对于SATA硬盘,当增加队列深度时,并不会增加IOPS,只会增加响应时间。这是因为硬盘只有一个磁头,并行度是1, 所以当IO请求队列变长时,每个IO请求的等待时间都会变长,导致响应时间也变长。
常见测试方法
#顺序读
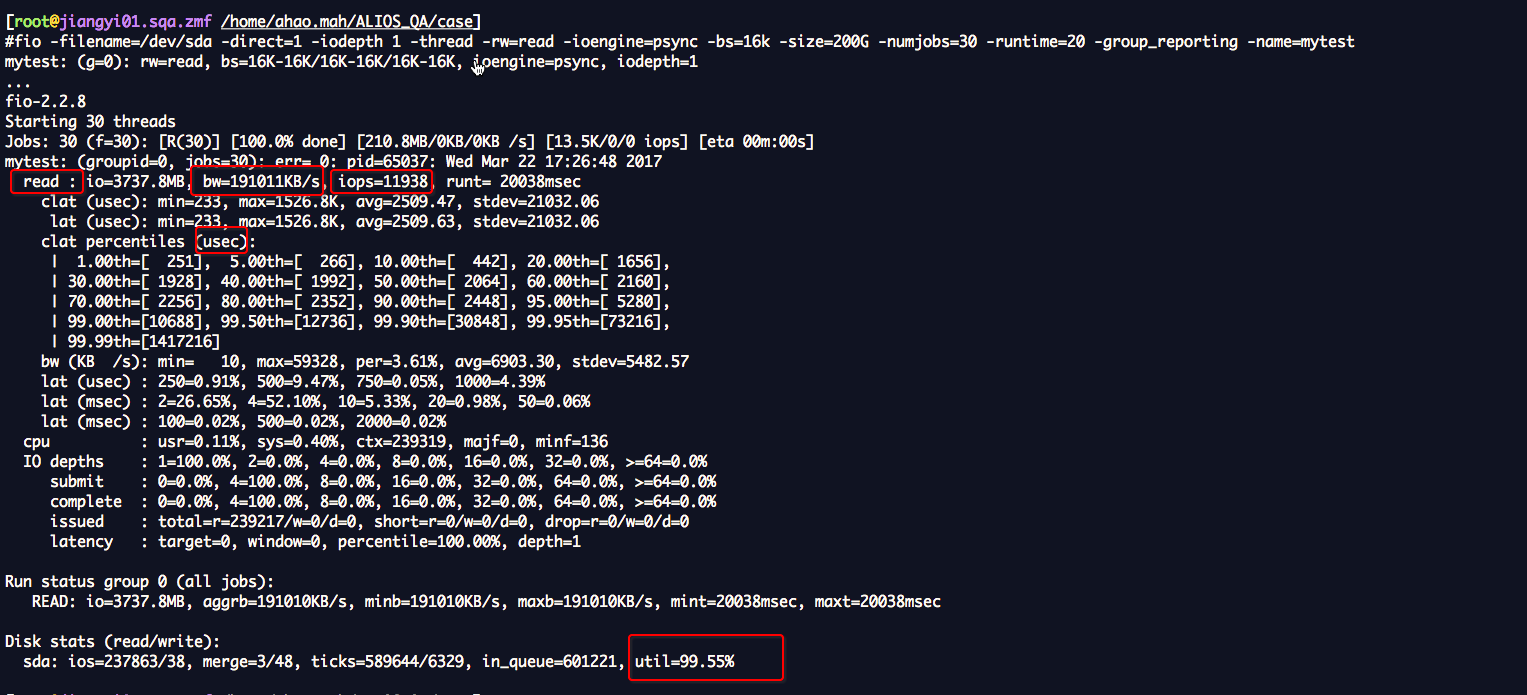
fio -filename=/dev/sda -direct=1 -iodepth 1 -thread -rw=read -ioengine=psync -bs=16k -size=200G -numjobs=30 -runtime=1000 -group_reporting -name=mytest
#顺序写
fio -filename=/dev/sda -direct=1 -iodepth 1 -thread -rw=write -ioengine=psync -bs=16k -size=200G -numjobs=30 -runtime=1000 -group_reporting -name=mytest
#随机读
fio -filename=/dev/sda -direct=1 -iodepth 1 -thread -rw=randread -ioengine=psync -bs=16k -size=200G -numjobs=30 -runtime=1000 -group_reporting -name=mytest
#随机写
fio -filename=/dev/sda -direct=1 -iodepth 1 -thread -rw=randwrite -ioengine=psync -bs=16k -size=200G -numjobs=30 -runtime=1000 -group_reporting -name=mytest
#混合随机读写
fio -filename=/dev/sda -direct=1 -iodepth 1 -thread -rw=randrw -rwmixread=70 -ioengine=psync -bs=16k -size=200G -numjobs=30 -runtime=100 -group_reporting -name=mytest -ioscheduler=noop
结果分析