一 、scrapy整体框架
1.1 scrapy框架图
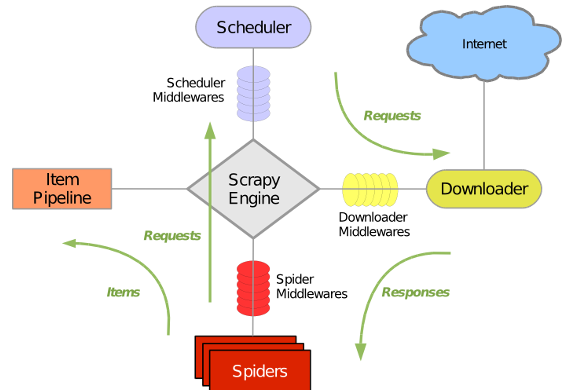
1.2 scrapy框架各结构解析
item:保存抓取的内容
spider:定义抓取内容的规则,也是我们主要编辑的文件
pipelines:管道作用,用来定义如何过滤、存储等功能(比如导出到csv或者mysql等功能)
settings:配置例如ITEM_PIPELINES 、图片存储位置等等功能
middlewares:下载器中间件是在引擎及下载器之间的特定钩子(specific hook),处理Downloader传递给引擎的response
1.3 数据流过程
从start_urls 开始,Scheduler 会将其交给 Downloader 进行下载,下载之后会交给 Spider 进行分析,Spider 分析出来的结果有两种:一种是需要进一步抓取的链接,例如之前分析的“下一页”的链接,这些东西会被传回 Scheduler ;另一种是需要保存的数据,它们则被送到 Item Pipeline 那里,那是对数据进行后期处理(详细分析、过滤、存储等)的地方。另外,在数据流动的通道里还可以安装各种中间件,进行必要的处理。
二、 爬取图片过程
2.1 整体介绍
2.1.1 环境
Anocondas+python3.6
2.1.2 创建工程
1、创建hupu这个工程
E:pgtool>scrapy startproject hupu
2、创建相应的spiders
E:pgtool>cd hupu##必须是进入到创建的项目中去建spiders
E:pgtoolhupu>scrapy genspider hp hupu.com ##hp=>生成hp.py ,爬虫名称为hp.py,允许访问的域名为hupu.com
通过爬取http://photo.hupu.com/nba/p35923-1.html网页中一个系列的图片
2.2 配置各组件
2.2.1 item.py
import scrapy class HupuItem(scrapy.Item): # define the fields for your item here like: hupu_pic = scrapy.Field() # images = scrapy.Field() image_paths = scrapy.Field()
2.2.2 settings.py
BOT_NAME = 'hupu'
SPIDER_MODULES = ['hupu.spiders']
NEWSPIDER_MODULE = 'hupu.spiders'
# Obey robots.txt rules
ROBOTSTXT_OBEY = False
ITEM_PIPELINES = {
'hupu.pipelines.HupuImgDownloadPipeline': 300,
}
IMAGES_URLS_FIELD = "hupu_pic" # 对应item里面设定的字段,取到图片的url
#IMAGES_RESULT_FIELD = "image_path"
IMAGES_STORE = 'E:/hupu'
2.2.3 hp.py
1 # -*- coding: utf-8 -*- 2 import scrapy 3 from scrapy import Request 4 from urllib.parse import urljoin 5 from hupu.items import HupuItem 6 class HpSpider(scrapy.Spider): 7 name = 'hp' 8 allowed_domains = ['hupu.com'] 9 start_urls = ['http://photo.hupu.com/nba/p35923-1.html'] 10 11 def parse(self, response): 12 item=HupuItem() 13 url=response.xpath('//div[@id="picccc"]/img[@id="bigpicpic"]/@src').extract() 14 15 reurl="http:"+url[0] 16 print ('links is :--',' ',reurl) 17 list1=[] 18 list1.append(reurl) 19 item['hupu_pic']=list1 20 yield item 21 ifnext=response.xpath('//span[@class="nomp"]/a[2]/text()').extract()[0] 22 if "下一张" in ifnext: 23 next_url=response.xpath('//span[@class="nomp"]/a[2]/@href').extract()[0] 24 yield Request(('http://photo.hupu.com/nba/'+next_url),callback=self.parse)
2.2.4 pipelines.py
1 from scrapy.pipelines.images import ImagesPipeline 2 from scrapy import Request 3 class HupuPipeline(object): 4 def process_item(self, item, spider): 5 return item 6 class HupuImgDownloadPipeline(ImagesPipeline): 7 8 def get_media_requests(self, item, info): 9 for image_url in item['hupu_pic']: 10 yield Request(image_url)
三、 爬虫执行与结果
3.1 执行过程
进入到工程路径下 scrapy crawl hp
(base) E:pgtoolFileshupu>scrapy crawl hp
3.2 获得结果
四、遇到的问题与分析解决
4.1 问题出现
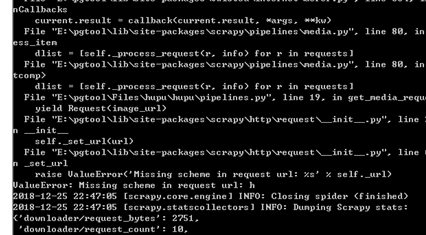
最开始遇到ValueError: Missing scheme in request url: h 这种报错,如下图
4.2 问题解析
如果单纯获取文本,那么只需start_urls是一个list;而如果获取图片,则必须start_urls与item中存储图片路径字段这两者必须都是 list。
4.3 解决方案
未修改前的spiders:
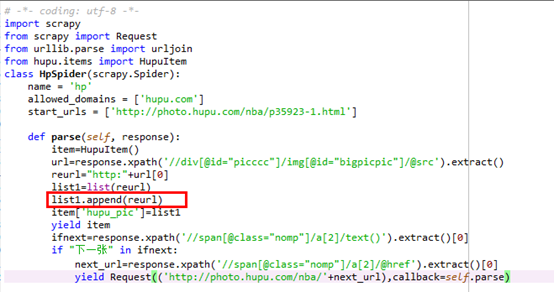
修改后spiders

五、总结
scrapy框架简单容易理解,而且支持异步多线程,是一个比较上手的爬虫框架。本次爬虫犯了一个低级错误,在于直接将图片链接转换为list而不经意间将链接拆分为一个一个的元素,如下示例:
str1='baidu.com'
list1=list(str1)
list1的结果实际为['b','a','i','d','u','.','c','o','m'],这也就是为什么一直报错Missing scheme in request url: h(翻译为:请求URL中的丢失整体链接:在h开始的位置)所以需要我们将整个链接放在只有一个元素的list中,使用修改后list.append()将一个链接完整的放置在list[0]中。
有问题的小伙伴们可以留言讨论交流,转载请注明出处,谢谢。