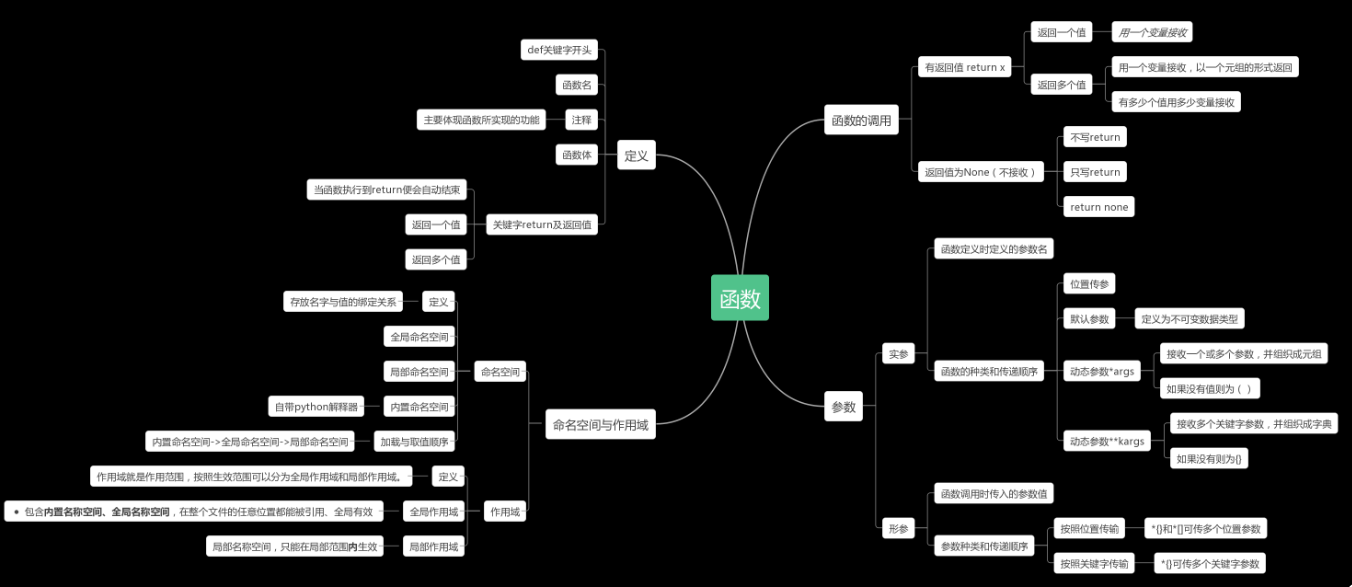
1.什么是函数?
将实现某个功能的语句块或者段包裹起来可以使代码可以重复使用的一种写法,return返回值默认为None
为什么要使用函数?一是为了避免代码重用,二是为了提高代码的可读性。
函数应该遵循先定义后使用的原则。
2.基本格式
def 函数名():
#函数体
return #返回值
函数名命名符合变量命的命名规则。
3.返回值
1)不写return默认返回None
2)return包括两种作用一者标志返回值,二者终止函数体。
3)多返回值中间以逗号隔开。
return的作用:结束一个函数的执行
首先返回值可以是任意的数据类型。
函数可以有返回值:如果有返回值,必须要用变量接收才有效果
也可以没有返回值:
没有返回值的时候分三种情况:
1.当不写return的时候,函数的返回值为None
2.当只写一个return的时候,函数的返回值为None
3.return None的时候,函数的返回值为None(几乎不用)
4.return返回一个值(一个变量)
5.return返回多个值(多个变量):多个值之间用逗号隔开,以元组的形式返回。
接收:可以用一个变量接收,也可以用多个变量接收,返回几个就用几个变量去接收
示例
1.函数有一个或多个返回值
def func():
a=111
b=[1,2,3]
c={'a':15,'b':6}
#return a#返回一个值
#return a,b,c#返回多个值,变量之间按逗号隔开,以元组的形式返回
print(func())
2.函数没有返回值
1.不写return时返回None
def func():
a=111
b=[1,2,3]
ret=func()
print(ret)
2.只写一个return时返回None
def func():
a=111
b=[1,2,3]
return
ret=func()
print(ret)
3.return None的时候返回None
def func():
a=111
b=[1,2,3]
return None
ret=func()
print(ret)
4.参数
1)形参
(1)完整结构如下
def 形参构成(位置参数, *args , 关键字参数='', **kwargs):
(2)形参如同函数的内建变量,和实参属于映射关系。
(3)位置参数的传参优先级最高
(4)args传入为元祖的形式
(5)kwargs传入为字典的形式
(6)数字、字符串、列表、字典、元祖、函数名都可以作为参数
2)实参:
(1)实参传入如下:
形参构成(位置参数, 关键字参数='')
(2)位置参数必须严格对应
(3)关键字参数在对应位置会被覆盖
(4)可以使用如下方式分散传参:
分散参数(*args,**kwargs)
5.命名空间与作用域
1)内置命名空间:python启动器启动之后就可使用的名字
2)全局命名空间:写在函数外面的变量
3)局部命名空间:函数中的命名空间
4)全局作用域:内置命名空间和全局命名空间中的名字
5)局部作用域:局部命名空间中的名字
6)局部命名空间可以调用它所从属的所有上层空间的名字,反之不行
7)globals()显示全局作用域的名字,locals()显示当前的作用域中的名字。
8)不是同层不能改变变量名的所指向的内存地址
9)global可以声明改变某变量的地址,同时添加它到全局作用域
10)nonlocal使用基本同global,但只可以作用与局部作用域。
11)nonlocal是py3新增加的关键字
6.闭包与装饰器
装饰器:
装饰器本质上是一个Python函数,它可以让其他函数在不需要做任何代码变动的前提下增加额外功能,装饰器的返回值也是一个函数对象。它经常用于有切面需求的场景,比如:插入日志、性能测试、事务处理、缓存、权限校验等场景。装饰器是解决这类问题的绝佳设计,有了装饰器,我们就可以抽离出大量与函数功能本身无关的雷同代码并继续重用。概括的讲,装饰器的作用就是为已经存在的对象添加额外的功能。
闭包:
在一个外函数中定义了一个内函数,内函数里运用了外函数的临时变量,并且外函数的返回值是内函数的引用。这样就构成了一个闭包。
一般情况下,在我们认知当中,如果一个函数结束,函数的内部所有东西都会释放掉,还给内存,局部变量都会消失。但是闭包是一种特殊情况,如果外函数在结束的时候
发现有自己的临时变量将来会在内部函数中用到,就把这个临时变量绑定给了内部函数,然后自己再结束。
1)闭包是通过函数引用外层变量来形成的。形如:
def fan():
a = 1
def fanc():
return a
return fanc
2)通过内层函数对外层函数的形成了对外层变量的保留和引用,是一种面向函数编程的重要思想。
3)装饰器是一种十分常用和实用的闭包实例。其基本形式形如:
def dect(key):
def inter(*args, **kwargs):
#运行前装饰
re = key(*args, **kwargs)
# 运行后装饰
return re
return inter
@dect
def aa():
4)装饰器可以在调用不可知的情况下对函数进行功能扩展。
7.迭代器与生成器
1)含有’__iter__‘方法的的对象就是可迭代对象,可以使用这个方法生成迭代器
2)含有’__iter__’和’__next__’方法的对象就是迭代器,迭代器可以使用next()方法依次返回值。迭代器可有效节省内存。
3)生成器是可以返回自建的可迭代对象的函数,其形如:
def dec():
n = 0
while True:
yield n
n += 1
8.递归函数与可迭代对象
递归函数:
递归(recursion)就是子程序(或函数)直接调用自己或通过一系列调用语句间接调用自己,是一种描述问题和解决问题的基本方法。
递归通常用来解决结构自相似的问题。所谓结构自相似,是指构成原问题的子问题与原问题在结构上相似,可以用类似的方法解决。具体地,整个问题的解决,可以分为两部分:第一部分是一些特殊情况,有直接的解法;第二部分与原问题相似,但比原问题的规模小。实际上,递归是把一个不能或不好解决的大问题转化为一个或几个小问题,再把这些小问题进一步分解成更小的问题,直至每个小问题都可以直接解决。因此,递归有两个基本要素:
(1)边界条件:确定递归到何时终止,也称为递归出口。
(2)递归模式:大问题是如何分解为小问题的,也称为递归体。递归函数只有具备了这两个要素,才能在有限次计算后得出结果
在递归函数中,调用函数和被调用函数是同一个函数,需要注意的是递归函数的调用层次,如果把调用递归函数的主函数称为第0层,进入函数后,首次递归调用自身称为第1层调用;从第i层递归调用自身称为第i+1层。反之,退出第i+1层调用应该返回第i层
递归函数的内部执行过程
一个递归函数的调用过程类似于多个函数的嵌套的调用,只不过调用函数和被调用函数是同一个函数。为了保证递归函数的正确执行,系统需设立一个工作栈。具体地说,递归调用的内部执行过程如下:
(1)运动开始时,首先为递归调用建立一个工作栈,其结构包括值参、局部变量和返回地址;
(2)每次执行递归调用之前,把递归函数的值参和局部变量的当前值以及调用后的返回地址压栈;
(3)每次递归调用结束后,将栈顶元素出栈,使相应的值参和局部变量恢复为调用前的值,然后转向返回地址指定的位置继续执行。
递归函数特性:
- 必须有一个明确的结束条件;
- 每次进入更深一层递归时,问题规模相比上次递归都应有所减少
- 相邻两次重复之间有紧密的联系,前一次要为后一次做准备(通常前一次的输出就作为后一次的输入)。
- 递归效率不高,递归层次过多会导致栈溢出(在计算机中,函数调用是通过栈(stack)这种数据结构实现的,每当进入一个函数调用,栈就会加一层栈帧,每当函数返回,栈就会减一层栈帧。由于栈的大小不是无限的,所以,递归调用的次数过多,会导致栈溢出)
-
使用递归函数的优点是逻辑简单清晰,缺点是过深的调用会导致栈溢出。
-
针对尾递归优化的语言可以通过尾递归防止栈溢出。尾递归事实上和循环是等价的,没有循环语句的编程语言只能通过尾递归实现循环。Python标准的解释器没有针对尾递归做优化,任何递归函数都存在栈溢出的问题。
附图
图1
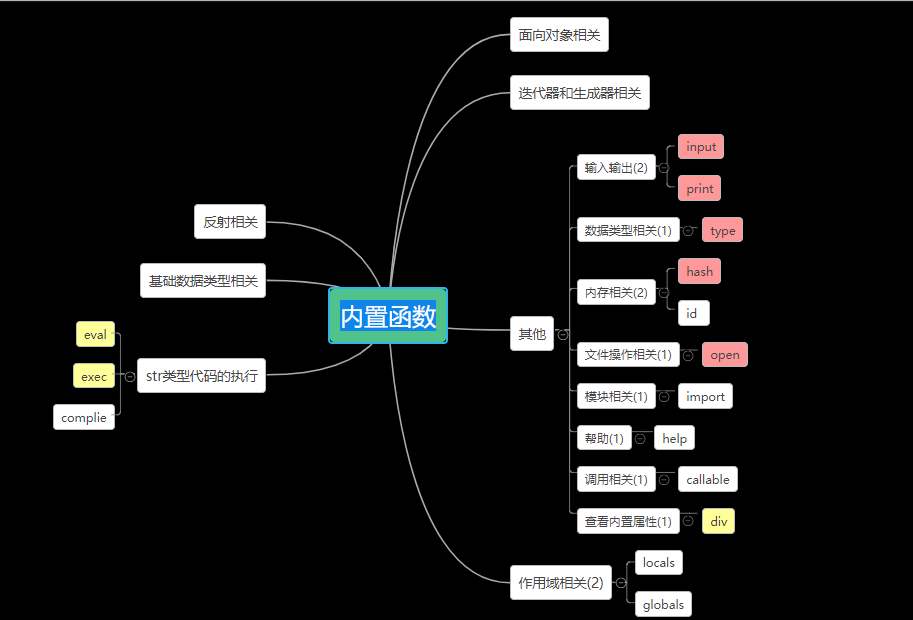
图2
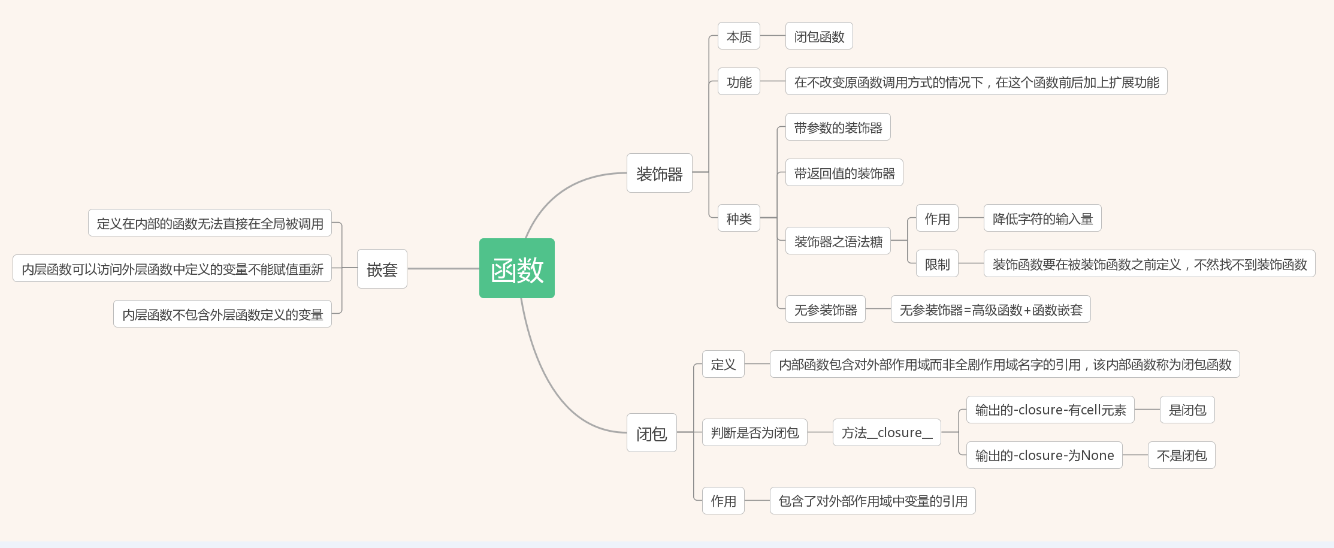
图3