http://www.cnblogs.com/zjfstudio/p/3877094.html#undefined
Hadoop学习笔记(6)
——重新认识Hadoop
之前,我们把hadoop从下载包部署到编写了helloworld,看到了结果。现是得开始稍微更深入地了解hadoop了。
Hadoop包含了两大功能DFS和MapReduce, DFS可以理解为一个分布式文件系统,存储而已,所以这里暂时就不深入研究了,等后面读了其源码后,再来深入分析。 所以这里主要来研究一下MapReduce。
这样,我们先来看一下MapReduce的思想来源:
alert("I'd like some Spaghetti!");
alert("I'd like some ChocolateMousse!");
看到这代码,感觉不顺眼,改之:
function SwedishChef(food)
{
alert("I'd like some " + food + " !");
}
SwedishChef("Spaghetti");
SwedishChef("Chocolate Mousse");
这类用函数取代重复代码的重构方式好处很多,优点很多,就不多说了!
再看这段:
alert("get the lobster");
PutInPot("lobster");
PutInPot("water");
alert("get the chicken");
BoomBoom("chicken");
BoomBoom("coconut");
看起来这段代码好像也有点重复的味道在里面,改之:
function Cook(i1,i2,f)
{
alert("get the " + i1);
f(i1);
f(i2);
}
Cook("lobster","water",PutInPot);
Cook("chicken","coconut",BoomBoom);
OK,这里面把一个函数当成了一个参数传来传去的。而且可以再省略点,把函数定义直接放入到函数调用者的地方:
Cook("lobster","water",
Function(x) { alert("pot " + x); } );
Cook("chicken","coconut",
Function(x) { alert("boom" + x); } );
嘿嘿,方便多了吧,这就是现在比较流程的匿名函数。
一旦你开始意识到可以将匿名函数作为参数,你就会发现有更多的应用了,来看:
var a=[1,2,3];
for(i = 0; I < a.length; i++)
{
a[i] = a[i] * 2;
}
for(i = 0; I < a.length; i++)
{
alert(a[i]);
}
遍历数组元素是一种很觉的操作,那好,既然很常用,我们提取出来写成一个函数得了:
function map(fn,a)
{
for(i = 0; i < a.length; i++)
{
a[i] = fn(a[i]);
}
}
有了这个map函数后,上面的程序我们就可来调用咯:
map(function (x) {return x*2; } , a);
map(alert, a);
除了遍历,一般我们还会有一些常用的语句,如:
function sum(a)
{
var s = 0;
for( i = 0; i < a.length ;i ++)
s += a[i];
return s;
}
function join(a)
{
var s = "";
for( i = 0; i < a.length ;i ++)
s += a[i];
return s;
}
alert(sum([1,2,3]);
alert(join(["a","b","c"]);
似乎sum和join这两个函数看起来很象,能否再抽象呢:
function reduce(fn, a, init)
{
var s = init;
for (i= 0;i < a.length; i++)
s = fn(s, a[i]);
return s;
}
function sum(a)
{
return reduce( function(a,b){return a+b;}, a, 0);
}
Function join(a)
{
return reduce( function(a,b){return a+b;}, a, "");
}
OK,这个函数都提取好了,那么,一个这么微小的函数,只能对数组中的元素进行遍历,到底能给你带来多大好处呢?
让 我们回头再来看map函数,当你需要对数组中每一个元素为依次进行处理时,那么实际情况很可能是,到底按照哪一种次序进行遍历是无关紧要的,你可以从头至 尾,也可以从尾到头遍历,都会得到相同的结果。事实上,如果你有两个CPU可以用,也许你可以写一些代码,使得每个CPU来处理一半的元素,于是一瞬间这 个map函数的运行速度就快了一倍。
进一步设想,你有几十万台服务器,分布在世界各地的机房中,然后你有一个超级庞大的数组,比如互联网的N多个网页信息,于是你让这些服务器来运行你的map函数,要快N多吧,每台机器实际上只处理很小的一部份运算。
OK, 运算提高了不少,有了这个,你就敢去想互联网的搜索是怎么来的了。但是机器好像也是有极限的,不可能有这么多资源让你无限量的扩展,那咋办,没关系,你可 以找一个超级天才,让他写出能够在全世界庞大的服务器阵列上分布式运行的map函数和reduce函数。
简单的函数提出来了,加上函数指定的涉入,那这个高效的函数,可以让我们在各个地方去用,然后让我们不同的程序都能在阵列上运行,甚至可以不用告诉这位天才你真正在实现啥功能,只要让他做出这个map函数来。
这是函数式编程里的理念,如是不知道的函数式编程自然也就想不出mapReduce,正是这种算法使得Google的可扩展性达到如此巨大的规模。其中术语Map(映射)和Reduce(化简)分别来自Lisp语言和函数式编程。
再来看看Hadoop中的mapRecude。
Hadoop就是由天才想出来的,能够在N多庞大服务器群上运行你的map和reduce函数的框架。有了这个平台,我们须要做的,仅仅要我们实现传入的map和reduce中的处理函数而已。
MapReudue 采用"分而治之"的思想,把对大规模数据集的操作,分发给一个主节点管理下的各分节点共同完成,然后通过整合各分节点中间结果,得到最终的结果。简单地 说,MapRedue就是"任务的分解与结果的汇总"。上述处理过程被高度的抽象为两个函数:mapper和reducer,mapper负责把任务分解 成多个任务,reducer负责把分解后多任务处理的结果汇总起来。至于在并行编程中的其他种种复杂问题,如分式。。。。 工作调度、负载均衡、容错处理、网络通讯等,均由MapReduce框架负责处理。

在 Mapper阶段,框架将任务的输入数据分割成固定大小的片段(split),随后将每个split进一步分解成一批键值对<K1,V1>。 Hadoop为每一个split创建一个Map任务用于执行用户自定义的map函数,并将对应的split中的<K1,V1>对作为输入,得 到计算的中间结果<K2,V2>。接着将中间结果按照K2进行排序,并将key值相同的value放在一起形成一个新的列表,开 成<K2,list(V2)>元组。最后再根据key值的范围将这些元组进行分组,对应不同的Reduce任务。
在Reducre阶段,Reducer把从不同Mapper接收来的数据整合在一起并进行排序,然后调用用户自定义的reduce函数,对输入的<K2,list(V2)>对进行相应的处理,得到健值对<K3,V3>并输出到HD
框架为每个split创建一个Mapper,那么谁来确定Reducers的数量呢? 是配置文件,在mapred-site.xml中,有配置Reducers的数量,默认是1。一般要设置多少为宜呢?等后面更深入了再找答案吧。
看看Hello World程序
看了前面的概念有点抽象,所以我们还是来看点实际的,看看我们之前写的helloword程序。
我们第一个helloworld程序是WordCount,——单词计数程序。这个程序的输入输出如下:
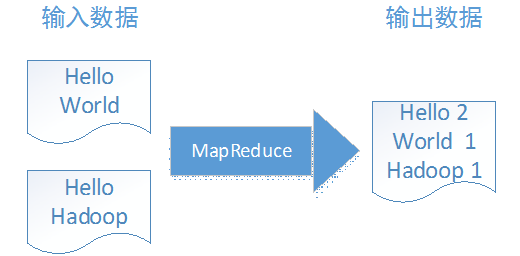
这是一个怎样的过程呢?我们一步步分解,WordCount程序经过了以下过程:
-
将文件拆分成splits,由于测试文件较小,所以一个文件即为一个split,并将文件按行分割成<key,value>对,这一步由MapReduce框架自动完成,其中key值存的是偏移量。
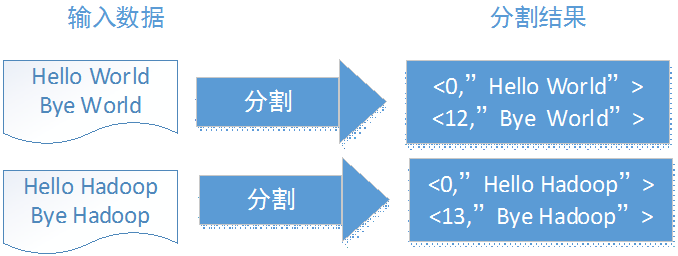
为了好解释,我们将输入数据中各增加了一行 bye world 和bye hadoop
-
将分割好的<key,value>交给用户定义的map方法进行处理,生成新的<key,value>对,这段代码,正是我们所编写过的:
public static class TokenizerMapper
extends Mapper<Object, Text, Text, IntWritable>{
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
public void map(Object key, Text value, Context context
) throws IOException, InterruptedException {
System.out.println("key=" +key.toString());
System.out.println("Value=" + value.toString());
StringTokenizer itr = new StringTokenizer(value.toString());
while (itr.hasMoreTokens()) {
word.set(itr.nextToken());
context.write(word, one);
}
}
}
这 段代码中,为了方便调试,每调用我们的map函数,都会输入key和value值。所以在执行结果中,我们可以看到程序的确有2次输入,与上面的值一至。 StringTokenizer是一个单词切词的类,将字符串中的单词一个个切出来,然后while循环,往context中输出key-value,分 为为切出来的单词,value为固定值1。
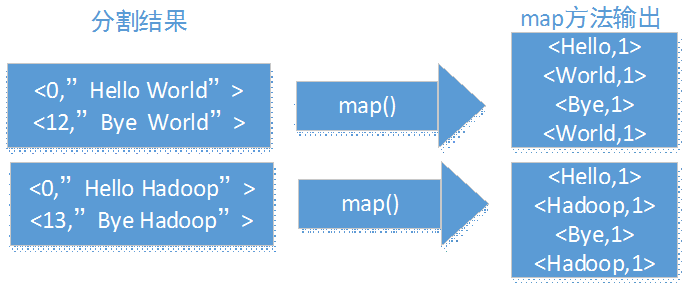
-
得到map方法输入的<key,value>对后,Mapper会将它们按照key值进行排序,并执行Combine过程,将key值相同的value值累加,得到Mapper的最终输出结果
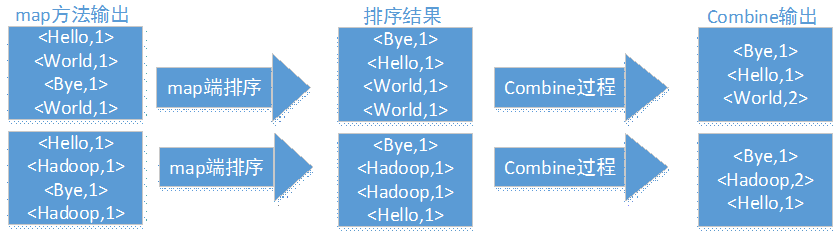
-
Reducer先对从Mapper接收的数据进行排序,再交由用户自定义的reduce方法进行处理,得到新的<key,value>对,并作为wordCount的输出结果。
public static class IntSumReducer
extends Reducer<Text,IntWritable,Text,IntWritable> {
private IntWritable result = new IntWritable();
public void reduce(Text key, Iterable<IntWritable> values,
Context context
) throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
result.set(sum);
context.write(key, result);
}}
这段代码将收到的key和values值,将values进行累加,然后key不变输出到key-value里面,最终得到结果:

好了,这个Hello World就程序整个过程就这样。写了map和recude类,如何让它关联执行呢? 所以回到示例程序的main函数:
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
System.out.println("url:" + conf.get("fs.default.name"));
String[] otherArgs = new GenericOptionsParser(conf, args).getRemainingArgs();
if (otherArgs.length != 2) {
System.err.println("Usage: wordcount <in> <out>");
System.exit(2);
}
Job job = new Job(conf, "word count");
job.setJarByClass(WordCount.class);
job.setMapperClass(TokenizerMapper.class);
job.setCombinerClass(IntSumReducer.class);
job.setReducerClass(IntSumReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.addInputPath(job, new Path(otherArgs[0]));
FileOutputFormat.setOutputPath(job, new Path(otherArgs[1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
这里,我们定义了一个Job类,然后把TokenizerMapper和IntSumReducer类指派给job,然后一切就交给job. waitForCompletion去执行,并等待其完成结果了。
OK了, 这个Hello World也总算是读懂了,不过。。。 还是有好多疑问,中间那么多过程,能不有个性化呢?如:输入能不能从数据库?输出能不能到Excel?等等,好了,后面再来分析吧。
本文参考:
《软件随想录》Joel Spolsky著
《实践Hadoop》刘鹏著