Text Clustering in R
建立词-文档矩阵
l 获取数据源
由于要分的词语里面有较多时属于人名,我们引入搜狗细胞库的人名词库。
installDict("E:\明星【官方推荐】.scel",dictname="starsName")
引入要聚类的文本
> df=read.table("F:/testString.txt")#以数据框的形式保存
> edit(data)

有这些文本,是从网上随机摘取的。
分词
我们直接将分词的结果也保留到数据框里面
> df$seg=segmentCN(gsub(" ","",df[1:length(df[,1]),]))
> df$seg=as.character(df$seg)#转化为文本
创建语料库
> corpus=Corpus(DataframeSource(df)) #以数据框作为源
我们看看语料库有些什么,
> inspect(corpus)
可以看到,分词的结果也是以向量的形式保存下来的。

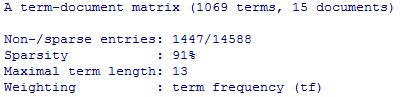
l 建立词-文档矩阵
> tdm=TermDocumentMatrix(corpus)
> tdm
由于是由向量表示的,在聚类时候应转为矩阵形式。
> tdMatrix=as.matrix(tdm)
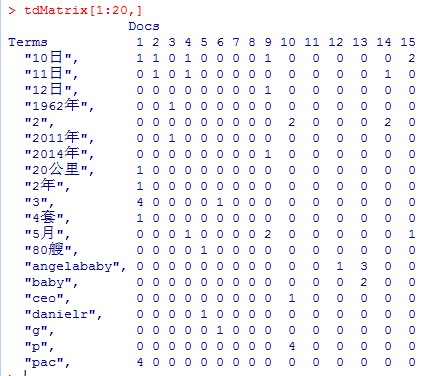
聚类
l 聚类的方法有很多了,我们先用k-means试下
>kmeans <- kmeans(t(tdMatrix),3)

聚类结果可以看到簇的分布情况
|
1 |
据日本新闻网10日报道,日本政府为了强化首都的防卫,决定在防卫省所在地建立一个反导防御基地 |
3 |
|
2 |
据新加坡联合早报11日报道,在泰国,数万名支持政府的红衫军昨天(10日)在曼谷西郊举行大规模集会,声言反抗反政府力量 |
2 |
|
3 |
美国拥有世界上规模最大、力量最强的反恐部队,包括陆军特种部队“绿色贝雷帽”、海豹突击队及三角洲特种部队等。海豹突击队 |
2 |
|
4 |
人民网5月11日讯伊朗军方宣布,已经在霍尔木兹海峡海峡附近建了多个无人机基地,伊朗无人机要不间断地在该海峡和波斯湾北部 |
2 |
|
5 |
美国负责东亚和太平洋事务的助理国务卿拉塞尔(DanielR.Russel)周四在河内表示,美国对中国与越南之间的紧张局势升级感到非常 |
2 |
|
6 |
何为颠覆?百度一下,这个词的定义是指对某项事物造成强烈冲击改变,使事物本质发生变化。事实上,从PC互联网时代到移动互联网时代 |
3 |
|
7 |
昨日,工业和信息化部、国家发展改革委《关于电信业务资费实行市场调节价的通告》(以下简称《通告》),宣告电信业务资费正式 |
2 |
|
8 |
今天,我们正处于决策成本产生巨变的爆发点,过去那些想尽办法都无法获取的数据,在今天唾手可得,而当有些表面上完全不相关的行业 |
3 |
|
9 |
首届清华五道口全球金融论坛,于2014年5月10日——5月12日在清华大学举办。论坛由清华大学主办,清华大学五道口金融学院和清华 |
3 |
|
10 |
投资理财服务,其实是非常低频次高客单价的服务,它的规模经济非常明显,P2P平台需要在互联网上寻找这样的客户。”有利网CEO刘雁南说这番话 |
2 |
|
11 |
今晚东方卫视播出的大型喜剧真人秀《笑傲江湖》,相声名家马三立孙子马小川(见左图,图TP)带着爷爷的经典相声亮相现场,却遭遇冷场尴尬 |
1 |
|
12 |
昨晚,第21届北京大学生电影节在国家奥林匹克体育中心闭幕。最终,汤唯凭借《北京遇上西雅图》摘下影后桂冠;杨颖 |
3 |
|
13 |
据香港媒体报道,刘嘉玲、Angelababy、林志玲、高圆圆等前晚在上海出席时装品牌活动,场内美女如云,众人更大斗性感。 |
2 |
|
14 |
5月11日母亲节期间,《舌尖上的中国2》导演邓洁发出长微博,针对此前《家常》节目播出后,遭受质疑的“子钰母女事件”作出回应 |
3 |
|
15 |
新浪娱乐讯5月10日晚,由共青团中央、中国残疾人联合会、中国青年志愿者协会、北京大学等共同主办的“心手相牵,共享阳光——中 |
3 |
l 奇异值分解
对于大的文本,我们不得不对其进行降维,然后再聚类
为方便在图中显示,我们取nv=2,即文档由一组二维变量衡量
> svdMatrix=svd(tdMatrix,nv=2)
> svdMatrix$v

在图中表示
> plot(svdMatrix$v)
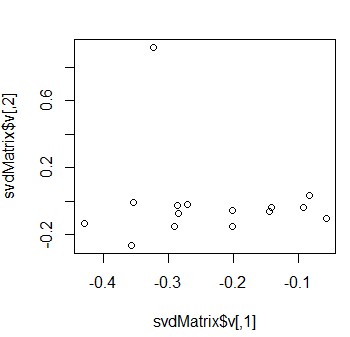
对分解后的矩阵进行聚类
> svdkmeans=kmeans(as.matrix(svdMatrix$v),3)
> svdkmeans

与上图的簇分布情况对照:

可以看到,经过奇异值分解之后的簇分布大致与直接聚类的分布相似。但奇异值分解却将原来的158维降到了2维,若是有大量长文本,经过奇异值分解后效率可以提高很多。
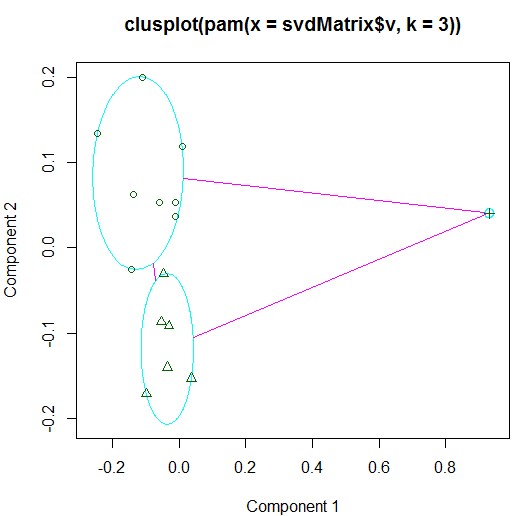
l 其他聚类结果
> clara(svdMatrix$v,3)
1 2 2 2 2 1 2 1 1 2 3 1 2 1 1
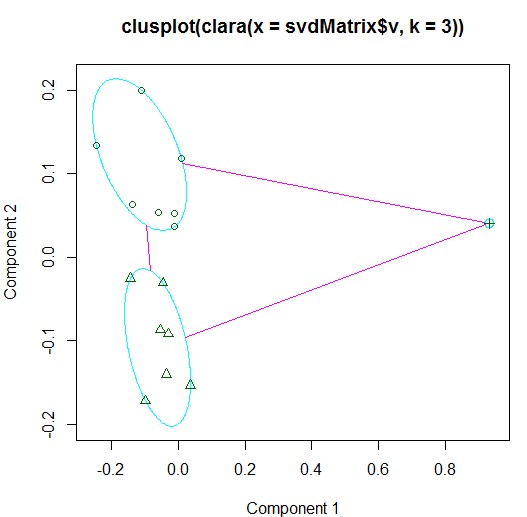
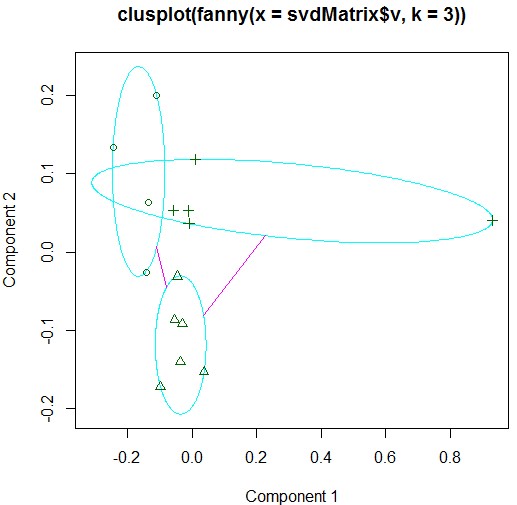
> fanClus=fanny(svdMatrix$v,3)
1 2 2 2 1 3 2 3 3 2 3 3 2 1 1
> clusplot(fanClus)
> pamClus=pam(svdMatrix$v,3)
1 2 2 2 1 1 2 1 1 2 3 1 2 1 1