AP聚类算法是目前十分火的一种聚类算法,它解决了传统的聚类算法的很多问题。不仅简单,而且聚类效果还不错。这里,把前两天学习的AP算法在R语言上面的模拟,将个人笔记拿出来与大家分享一下,不谈AP算法的原理,只初步的讲一下应用,更多请关注下期。
APClusting in R
相似矩阵的计算
negDistMat(x, sel=NA, r=1, method="euclidean", p=2)
expSimMat(x, sel=NA, r=2, w=1, method="euclidean", p=2)
相似度公式:s=exp(-(d/w)^r)
linSimMat(x, sel=NA, w=1, method="euclidean", p=2)
相似度公式:s=max(0,1-d/w)
corSimMat(x, sel=NA, r=1, signed=TRUE, method="pearson")
相似度公式:s=(x^T y)/(|x| |y|)
linKernel(x, sel=NA, normalize=FALSE)
x若是向量,则取其所有值进行矩阵求取。若是矩阵和数据框,则取行作为sample。
如:

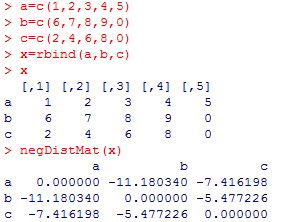
向量 矩阵
AP聚类函数
①Apcluster()进行Ap过程
apcluster(x,p)
x是相似矩阵
p是指定簇时候的界定值
②同时求相似矩阵和执行Ap
apcluster(s, x)
s是相似矩阵的求取函数

其中,negDistMat()可以指定参数,如negDistMat(r=2)
聚类返回结果APResult
我们作一个二维的数据集的聚类

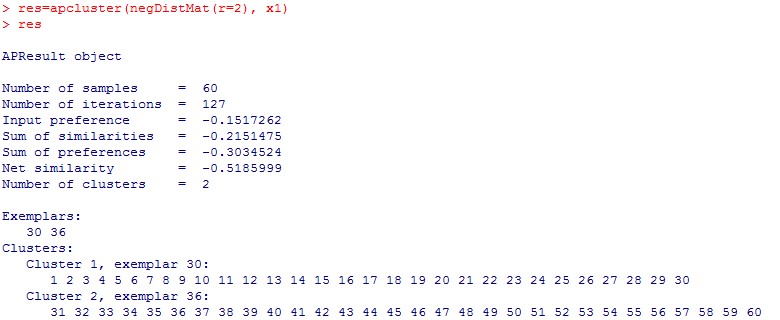
从图中我们可以看到
a.样本个数
b.迭代次数 res@it
c.簇的个数以及簇的成员
d.簇的界定值 Input preference大于它就被选为簇中心
e.簇中心 Exemplar
等;
res@sim 相似矩阵
对结果进行绘图
plot函数
apcluster包里面对plot函数进行了重写,plot(x,y)
x是聚类结果,y是数据集
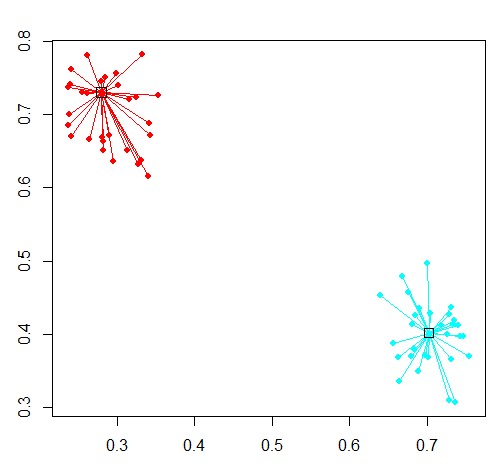
由上图我们也可以看到,两个簇中心是30[0.2796125 0.7300467]、36[0.7023239 0.4018984]
heatmap函数
a.
heatmap(x)
x是聚类结果
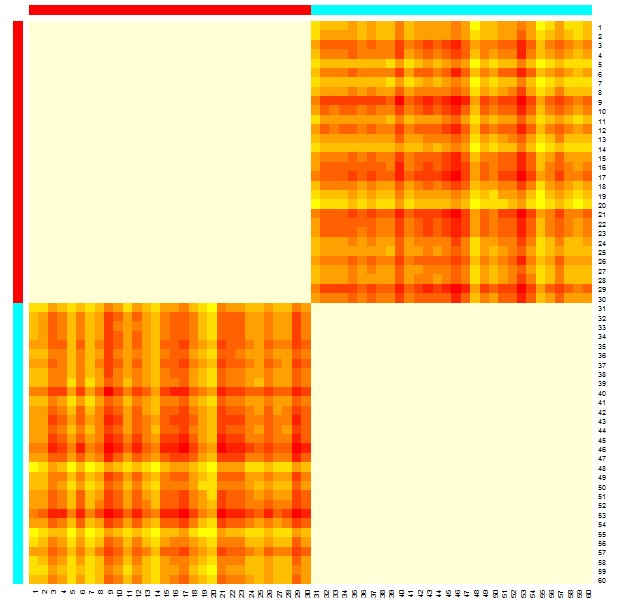
由上图可以看出各点之间的相似度
b.
heatmap(sim),画相似矩阵的热点图,如图
heatmap(res@sim[1:10,1:10])
由于数据较多,我们只取前10行以及前10列进行绘图
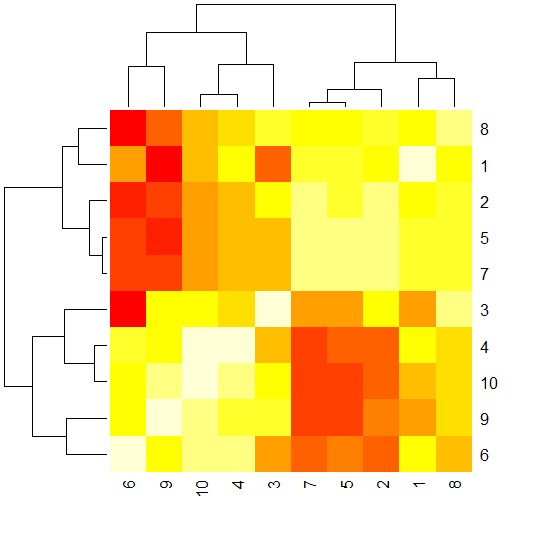
由上图可以看出各点之间的相似对,以及他们之间的层次关系.