awk :解释
当调用awk时,awk会对输入进行逐行处理,所有的输出都会发送到stdout。
{print}代码块,在awk中,花括号用于将几块代码组合到一起

- BEGIN和END模块
- BEGIN:对于输入的每一行,awk都会执行BEGIN和END代码块一次。在很多情况中,可能需要awk在开始处理输入文件中的文本时,提前执行初始化。对于这种情况,awk使用BEGIN模块。

- END:在awk处理所有文件中的行之后,执行END代码块,END块用于执行最终计算或打印应该出现在输出流结尾的摘要信息。
- BEGIN:对于输入的每一行,awk都会执行BEGIN和END代码块一次。在很多情况中,可能需要awk在开始处理输入文件中的文本时,提前执行初始化。对于这种情况,awk使用BEGIN模块。
- awk 运算
- 赋值运算:a+5 等价于:a=a+5;

- 关系运算:

- 正则运算:

- 逻辑运算:

- ?: 三目运算:

- 赋值运算:a+5 等价于:a=a+5;
- 常用内置变量
-
变量名 含义 $0 当前记录 $1~$n 当前记录的第n个字段 FS 分隔符,默认分隔符是空格 RS 输入记录分隔符,默认是换行符 NF 当前行的列数 NR 已读取的记录数,就是行号。从1开始 OFS 输出字段分隔符 默认是空格 ORS 输出字段的换行符 默认是换行符
-
-
awk数组
对于awk '!a[$3]++',需要了解3个知识点
1、awk数组知识,不说了
2、awk的基本命令格式 awk 'pattern{action}' 省略action时,默认action是{print},如awk '1'就是awk '1{print}'
3、var++的形式:先读取var变量值,再对var值+1
通过awk去除重复行
以数据
1 2 3
1 2 3
1 2 4
1 2 5
为例,对于awk '!a[$3]++'
在awk中,对于未初始化的数组变量,在进行数值运算的时候,会赋予初值0,因此a[$3]=0,++运算符的特性是先取值,后加1
awk处理第一行时: 先读取a[$3]值再自增,a[$3]即a[3]值为空(0),即为awk '!0',即为awk '1',即为awk '1{print}'
awk处理第二行时: 先读取a[$3]值再自增,a[$3]即a[3]值为1,即为awk '!1',即为awk '0',即为awk '0{print}'
.............
最后实现的效果就是对于$3是第一次出现的行进行打印,也就是去除$3重复的行
a[$NF]+=$6是什么意思呢?
相当于a[$NF]=a[$NF]+$6
当a[$NF]从未出现时,a[$NF]=0,即a[$NF]=0+$6,即a[$NF]=$6
当a[$NF]出现过时,a[$NF]将被覆盖
[root@localhost scripts]# cat test.txt
0 1
1 0
2 3a
3 0
2 3b
[root@localhost scripts]# awk 'a[$1]+=$2{print $0}' test.txt
0 1
2 3a
2 3b -
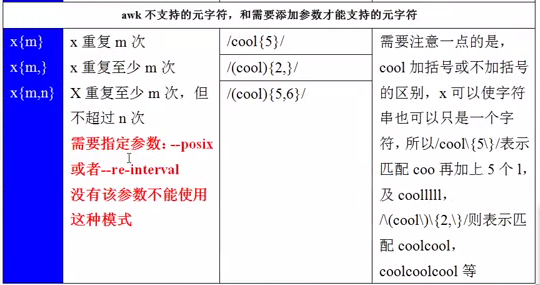
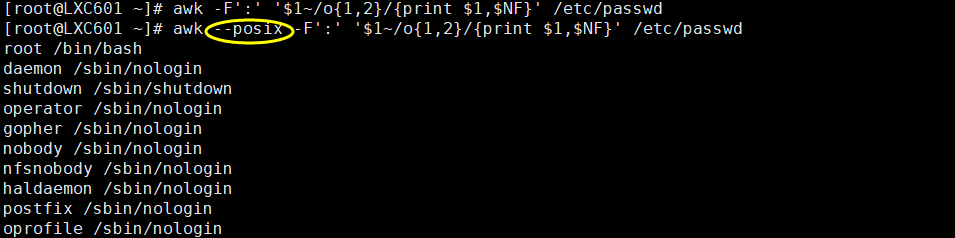
注意问题:awk不支持元字符 需要添加 --posix