4.1 Introdution
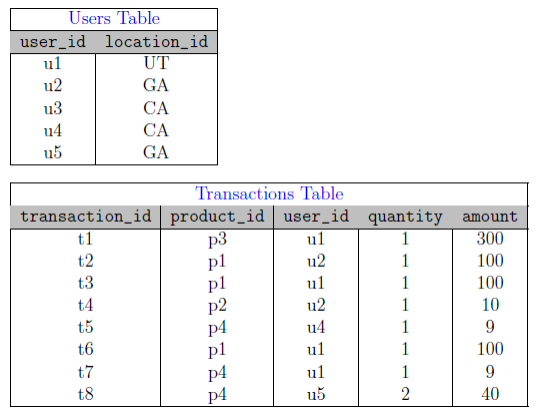
Consider a company such as Amazon, which has over 200 millions of users and possibly can do hundreds of millions of transactions per day. To show the concept of Left Outer Join, assume we have two types of data: users and transations: where users‘ data has user‘s "location" (saylocation_id) information and transactions has "user" (say user_id) information, but transactions do not have direct information about user‘s locations. Given users and transactions:
users(user_id, location_id)
transactions(transaction_id, product_id, user_id, quantity, amount)
Consider the following values for our users and transactions (note that these values are just examples to demonstrate the concept of Left Outer Join in MapReduce environment):
Here are some SQL queries to answer our questions:
- Q1:find all products (and associated location) sold
mysql> SELECT product_id, location_id -> FROM transactions LEFT OUTER JOIN users -> ON transaction.user_id = user_id;
- Q2:find all products (and associated location counts) sold
mysql> SELECT product_id, count(location_id) -> FROM transactions LEFT OUTER JOIN users -> ON transaction.user_id = user_id -> group by product_id;
- Q3:find all products (and unique location counts) sold
mysql> SELECT product_id, count(distinct location_id) -> FROM transactions LEFT OUTER JOIN users -> ON transaction.user_id = user_id -> group by product_id;
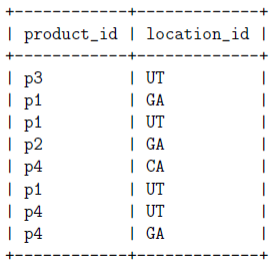


左外连接的概念在学数据库的时候有涉及到,大概就是有两张表,分别称为左表和右表,按照某些属性值相等连接起来,左外连接就是左表的全部记录都会在,要是右表中没有对应的就填NULL。引用了书上假设的实际应用,给出了SQL的相应的解决语句,这章主要介绍如何在MApReduce环境中实现左外连接的问题。
4.2 Implementation of Left Outer join in MapReduce
The desired output we are looking is provided by SQL Query-3, which finds all number of distinct (unique) locations in which each product has been sold for given all transactions. We present solution for Left Outer Join in two steps:
- MapReduce Phase-1: find all products (and associated locations) sold. The answer to Phase-1 is using SQL Query-1.
- MapReduce Phase-2: find all products (and associated unique location counts) sold. The answer to Phase-2 is using SQL Query-3.
我们想要的输出就像上面引用的Q3的那样,即找出产品被卖出的地点的总数。为此,我们分成两个阶段,先找出产品被卖出的地点,然后计算各总数。
4.2.1 MapReduce Phase-1
This phase will perform "left outer join" operation with a MapReduce job, which will utilize two mappers (one for users and the other one for transactions) and reducer will emit (Key,Value) with Key = product_id, and Value = location_id. Using multiple mappers is enabled by the MultipleInputs class (note that if we had a single mapper, then we would have used *Job.setMapper *Class()):

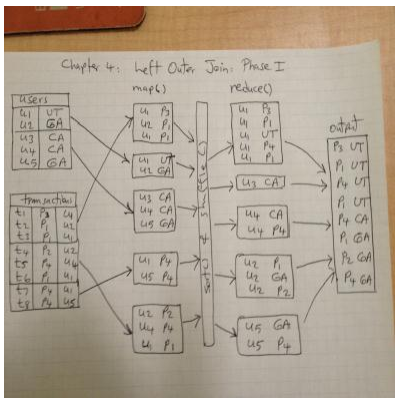
MapReduce解决这个问题的阶段一需要用到两个mapper,一个处理users数据,一个处理transactions数据。user mapper读入数据,输出键值对(user_id, location_id)。transcation mapper读入数据,输出键值对(user_id, product_id)。最后还有个reducer,接收前面二者的输出,然后自己输出键值对(product_id, location_id)。看起来好像很简单,但是实际上,这个是办不到的。因为reducer接收的键值对除了按键排序之外,其它并没有任何内在联系,你没办法从这样的数据中找到产品的销售地。所以书上把这称为[VERSION-1],也就有了下面改进的[VERSION-2](那何必讲[VERSION-1]呢)。
4.2.1.1 Transaction Mapper [VERSION-2]
the transaction map() reads (transaction_id, product_id, user_id, quantity, amount) and emits (key=Pair(user_id, 2), value=Pair("P", product_id).

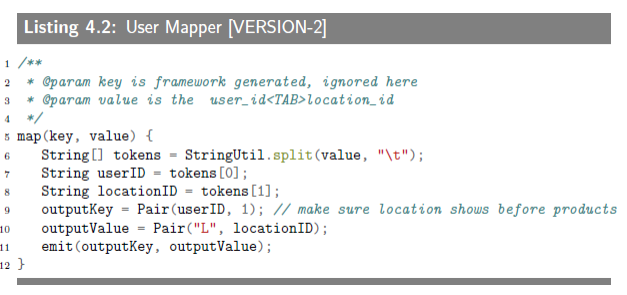
4.2.1.2 User Mapper [VERSION-2]
the user map() reads (user_id, location_id) and emits (key=Pair(user_id, 1), value=Pair("L", location_id)).
4.2.1.3 The reduce of Phase-1 [VERSION-2]
gets both Pair(“L”, location_id) and Pair("P",product_id) and emits (key=product_id, value=location_id).

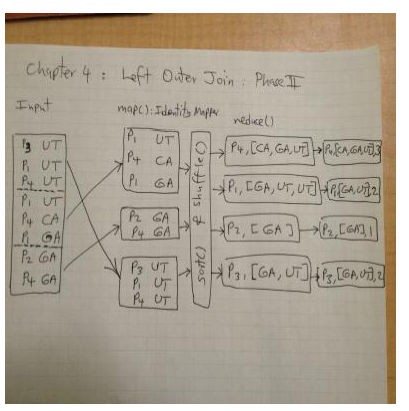
[VERSION-2]两个mapper输出的键值对比较复杂,也比较奇怪,user mapper输出(key=Pair(user_id, 1), value=Pair("L", location_id)),transaction mapper输出(key=Pair(user_id, 2), value=Pair("P", product_id)。为了理解算法思路,先要清楚两点:一是reducer收到的键值对是按键排序的,即user_id;二是一个user_id对应的location_id只有一个。其中的“L”和“P”用于鉴别到底是什么的id。上面输出键值对中的数字1和2,是用来二次排序用的,希望在按键排序的基础上,每个user_id后面的value的第一个会是location_id。这样,在碰到下一个user_id的location_id之间的value则都是在该地卖出去的货物id。如此一来,上面引用的reducer的代码也就可以理解了(难得看懂一次)。不过,这也是特殊,并不通用,万一location不唯一呢,还是我理解错了。上面书上手绘的那张数据流图,每个user_id后面的location_id也并没有在第一条,不过还是觉得我的理解挺合理的。
4.2.2 MapReduce Phase-2:Counting Unique Locations
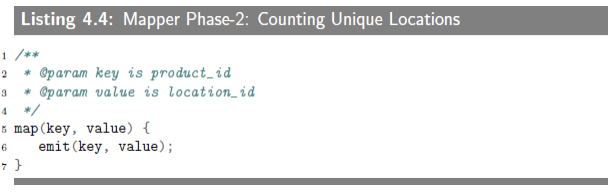
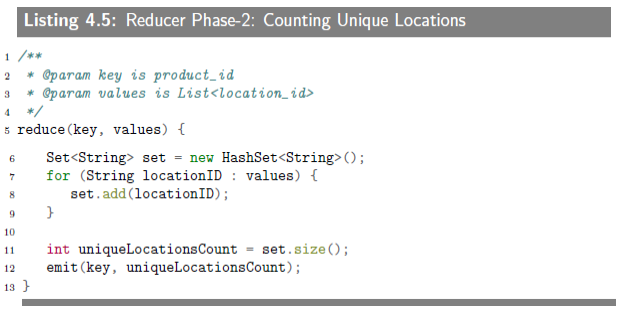
This phase will use output of Phase-1 (which is a sequence of pairs of (product_id, location_id) and generates pairs of (product_id, number_of_unique_locations). The mapper for this phase is an identity mapper and the reducer will count the number of unique locations (by using a Set data structure) per product.
4.2.2.1 Mapper Phase-2:Counting Unique Locations
4.2.2.2 Reduce Phase-2:Counting Unique Locations
4.2.3 Implementation Classes in Hadoop

跳过“4.3 Sample Run”。
4.4 Spark Implementation
Since Spark provids a higher-level Java API than MapReduce/Hadoop API, we will present the whole solution in a single Java class (called LeftOuterJoin), which will include a series of map(),groupBy(), and reduce() functions.
This is how the algorithm works: for users and transactions data we generate (here T2 refers to Tuple2):
users => (userID, T2("L", location))
transactions => (userID, T2("P", product))
Next, we create a union of these data:
all= transactions.union(users);
= { (userID1, T2("L", location)),
(userID1, T2("P", P11),
(userID1, T2("P", P12),
...
(userID1, T2("P", P1n),
...
}
where Pi is a productIDThe next step is to group data by userID. This will generate:
{
(userID1, List<T2("L", L1), T2("P", P11), T2("P", P12), ...>),
(userID2, List<T2("L", L2), T2("P", P21), T2("P", P22), ...>),
...
}
where
Li is a locationID,
Pij is a productID.
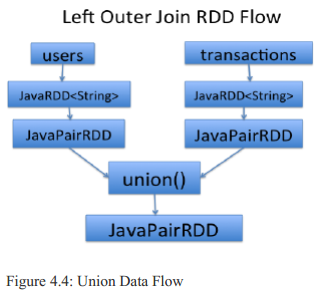
Spark有更高级的Java API,可以只用一个类就实现先前的算法。Spark为mappers和reducers提供了更丰富的API,不用特别的插入类,你就可以有多种不同的类型的mapper,而且我们将会使用JavaRDD.union()函数来返会两个JavaRDDs(user RDD and transaction RDD)的合并(合并的二者得是同一类型)。
4.4.1 Spark Program
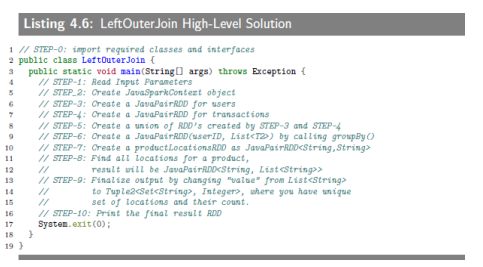
下面照例蛮把代码贴上来。
4.4.2 SEPT-0:Import Required Classes

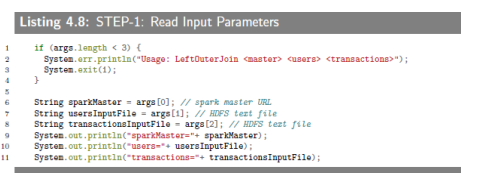
4.4.3 SEPT-1:Read Input Parameters
4.4.4 SEPT-2:Create JavaSparkContext Object
A JavaSparkContext object is created by using spark master URL. This object is used to create first RDD.

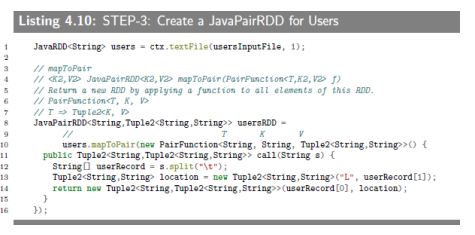
4.4.5 SEPT-3:Create a JavaPairRDD for Users
First, we create a users
JavaRDD<String>, where RDD element is a single record of text file (representing userID and locationID). Next, we useJavaRDD<String> .mapToPair()function to create a newJavaPairRDD<String,Tuple2<String,String>>where key is a userID and value is a Tuple2("L", location).
4.4.6 SEPT-4:Create a JavaPairRDD for Transactions
First, we create a transactions
JavaRDD<String>, where RDD element is a single record of text file (representing transaction record). Next, we useJavaRDD<String> .mapToPair()function to create a newJavaPairRDD<String,Tuple2<String,String>>where key is a userID and value is a Tuple2("P", product).

4.4.7 SEPT-5:Create a union of RDD's created by SEPT-3 and SEPT-4
This step creates union of two
JavaPairRDD<String,Tuple2<String,String>>s. the JavaPairRDD.union() requires that both RDD’s to have the same exact types.


4.4.8 SEPT-6:Create a JavaPairRDD(userID, List(T2)) by calling groupBy()
Next, we group data (created in STEP-5) by userID. This step is accomplished by JavaPairRDD.groupByKey().
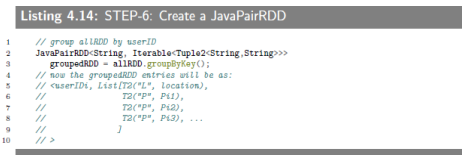
这里键值对的顺序就符合我的理解,同一用户中,地点放在第一位。
4.4.9 SEPT-7:Create a productLocationsRDD as JavaPairRDD(Sting, String)
This step is accomplished by JavaPairRDD.flatMapToPair() function, which we implement a PairFlatMapFunction.call() method. The PairFlatMapFunction workd as:
PairFlatMapFunction<T, K, V>
T => Iterable<Tuple2<K, V>>
where in our example: T is an input and we create (K, V) pairs as output:
t = Tuple2<String, Iterable<Tuple2<String, String>>>
K = String
V = String

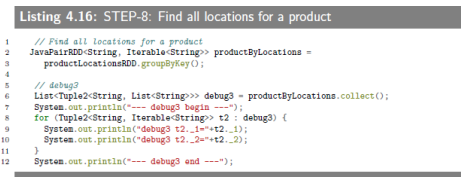
4.4.10 SEPT-8:Find all locations for a product
This step groups RDD pairs of (product, location) by grouping of products. We use JavaPairRDD.groupByKey() to accomplish this step. This step does some basic debugging too by calling JavaPairRDD.collect() function.
4.4.11 SEPT-9:Finalize output by changing "value"
STEP-8 produced a
JavaPairRDD<String, List<String>>object, where key is product (as a String) and value is aList<String>, which a list of locations (but might have duplicates). To removeduplicate elements from a vlue, we use a JavaPairRDD.mapValues() function. We implement this function by converting aList<String>to aSet<String>. Note that the keys are not altered. Mapping values are implemented by a Function(T, R).call(), where T is an input (asList<String>) and R is an output (asTuple2<Set<String>, Integer>).

4.4.12 SEPT-10:Print the final result RDD
The final step emits the results by using JavaPairRDD.collect() method.

跳过“4.4.13 Running Spark Solution”以及“4.5 Running Spark on YARN”。
4.6 Left Outer join by Spark's leftOuterjoin()
This section solves the left outer join by using Spark’s built
in JavaPairRDD.leftOuterJoin() method.Using Sparks’s JavaPairRDD.leftOuterJoin() method enable us:
- To avoid the costly JavaPairRDD.union() operation between users and transactions.
- To avoid introducing custom flags such as ‖L‖ for location and "P" for products.
- To avoid extra RDD transformations to separate custom flags from each other.
Using JavaPairRDD.leftOuterJoin() method enable us to produce the result efficiently. The transactionsRDD is the left table and usersRDD is the right table.
使用Spark内置的JavaPairRDD.leftOuterJoin()方法来解决这个问题,更加方便高效。不过左外连接之后还包含users_id,要记得去掉。然后依旧蛮把代码贴上来。
4.6.1 High-Level Steps

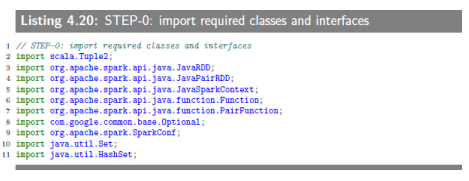
4.6.2 SEPT-0:import required classes and interfaces
4.6.3 SEPT-1:read input parameters

4.6.4 SEPT-2:create Spark's context object

4.6.5 SEPT-3:create RDD for user's data
This step creates usersRDD, which is a set of (userID, location) pairs. The usersRDD represents the "right" table for the left outer join operation.

4.6.6 SEPT-4:Create usersRDD:The "right" Table
This step create the right table represented as usersRDD, which contain (K=userID,V=location) pairs from users input data.

4.6.7 SEPT-5:create transactionRDD for transaction's data
This step creates transactionRDD, which is a set of (userID, product) pairs. The transactionRDD represents the "left" table for the left outer join operation.

4.6.8 SEPT-6:Create transactionsRDD:The Left Table
This step create the left table represented as transactionsRDD, which contain (K=userID,V=product) pairs from transactions input data.

4.6.9 SEPT-7:use Spark's bulit-in JavaPairRDD.leftOutputJoin() method
This is core step for performing the left outer join operation by using Spark’s JavaPairRDD.leftOuterJoin() method.

4.6.10 SEPT-8:create (product, location)pairs
This step builds another JavaPairRDD, which contains (K=product, V=location) pairs. Note that we completely ignored the userIDs, since we are only interested in products and their unique user’s locations.

4.6.11 SEPT-9:group (k=product, V=location) pairs by K
This step groups (K=product, V=location) pairs by K. The result will be (K, V2) where V2 is a list of locations (will have duplicate locations).

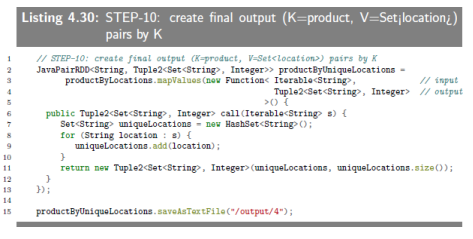
4.6.12 SEPT-10:create final output (K=product, V=Set(location))
This final step removes duplicate locations and creates (K,V2), where V2 is a
Tuple2<Set<location>,size>.
跳过“4.6.13 Sample Run by YARN”。
最后再来稍微总结一下,同样因为蛮贴了实现代码,博文看起来很长,实际上没什么内容。这章讨论的左外连接问题,在数据库课上多少有涉及到一点,理解起来并没有什么问题。不同的是,这次的数据是大数据,SQL并不适合,讨论的是如何用Hadoop和Spark来解决左外连接问题。书上一共介绍了三种方法来解决示例,但是感觉前面两种并不是通用的方法。示例是说有两张表,一张记录着用户ID和地点ID,另一张记录着用户ID,产品ID以及其他一些业务信息,问题是找出产品被卖到哪些地点,即输出键值对(product_id, location_id)。解决的思路,肯定大数据首先要分块,交给很多的mapper来执行,从不同的数据中提取出我们需要的信息,即从用户表输出(user_id, location_id),从业务表输出(user_id, product_id)。这两个输出都传到reducer,按照user_id左外连接起来,最后输出结果。不过,没有经过处理的两个输出,最后reducer收到的键值对之间没有任何内在联系,我们没办法区分user_id后面是地点信息还是产品信息。所以前面两种方法的mapper的输出实际上没有这么简单,添加了一些东西,用来二次排序以及区分地点和产品。使得最后到达redecer的键值对不仅按user_id排序,并且每个user_id后面的第一个信息是地点,这样在遇到下一个user_id之前的信息都是销售到该地的产品,输出结果就变得很容易了。之所以说不是通用方法,因为这里user_id只对应着一个地点,要是不止一个地点呢。最后的方法用到了Spark里的leftOuterjoin()方法,我们只要去掉连接后的user_id,再稍微按product_id整理一下就可以输出了。因为左外连接直接用方法实现,而不像前面两种有针对性地特别写,感觉是通用的方法。至于具体的实现代码,依然蛮贴蛮看,虽然打不出来。运行示例运行出来肯定都是对的,感觉没什么必要贴上来。以上。