rank函数问题:
表:employee
找出表中不同departmenid里salary最高的人员信息,筛选结果如下
解法:
select name,salary,departmentid from (
select
rank() over(partition by departmentid order by salary desc) as rank ,
name,
salary,
departmentid
from employee )
where rank = 1;
首先使用rank()函数进行排名
RANK() OVER (PARTITION BY <Colum Name> ORDER BY <Colum Name> ASC/DESC)
1、此函数根据分区和排序子句计算数据集的排名。
2、当我们必须从源集中的多个记录或前N个或后N个记录中选择最新记录时,这将非常有用。
SAP HANA从初始版本支持RANK功能 - 如果我们要使用它作为SQL脚本的一部分
但是从SAP HANA SP9版本,我们在创建图形计算视图时将此功能作为一个附加节点。
以下使用举例及使用场景介绍
原文转载:https://blog.csdn.net/sapmatinal/article/details/54910541
rank在sqlscript中使用场景
这里的情况是,我们有销售订单数据,其中,对于现有销售订单的每次更改,表中都将有一个新记录。
当我们在此表上构建报表时,我们必须选择最近的销售订单,即根据订购时间最近更改的销售订单。
1、首先创建表
CREATE COLUMN TABLE SAP_STUDENT.ORDERS_DATA_RANK
(ORDER_NO INTEGER,
CUST_NO NVARCHAR(10),
PROD_NO NVARCHAR(10),
QUANTITY INTEGER,
PRICE INTEGER,
ORDERED_TIME SECONDDATE)
2、然后给表里添加数据
INSERT INTO SAP_STUDENT.ORDERS_DATA_RANK VALUES(1234,’C01′,’P012′,10,5,’2015-09-10 08:03:12′);
INSERT INTO SAP_STUDENT.ORDERS_DATA_RANK VALUES(1235,’C02′,’P023′,100,10,’2015-09-10 14:45:36′);
INSERT INTO SAP_STUDENT.ORDERS_DATA_RANK VALUES(1236,’C03′,’P067′,80,20,’2015-09-15 21:23:56′);
INSERT INTO SAP_STUDENT.ORDERS_DATA_RANK VALUES(1234,’C01′,’P012′,30,5,’2015-09-10 11:03:12′);
INSERT INTO SAP_STUDENT.ORDERS_DATA_RANK VALUES(1234,’C01′,’P012′,50,5,’2015-09-12 08:03:12′);
INSERT INTO SAP_STUDENT.ORDERS_DATA_RANK VALUES(1236,’C03′,’P067′,120,20,’2015-09-17 11:23:12′);
运行上述insert语句后,请运行以下select语句,以确保数据以正确的方式插入,如下所示。
rank在sqlscript中使用场景
基于我们的场景,我们必须通过ORDER_NO分区我们的数据集,然后基于ORDERED_TIME列以降序排列,以获得排在最近更改的销售订单的top(first)。
我们可以通过编写以下SQL语句来实现这一点,SQL语句根据PARTITION和ORDER BY子句计算RANK,并将秩分配为1,2,3等。
一旦我们在RANK函数的帮助下排列数据集,我们可以将RANK值过滤为“1”,以将最近的记录获取到输出。
RANK()使用图形计算视图
现在让我们看看如何在创建图形计算视图时使用rank节点实现同样的事情。
注意:此节点仅在SAP HANA SP9版本的图形计算视图中可用。
请按照以下步骤使用计算视图构建排名功能。
第一步:
确保我们在SAP HANA系统中创建了上述表并提供了数据。
注意:个人也可以使用自己的数据集来检查功能。
第二步:
让我们继续创建一个类型为’graphical’的新计算视图,并指定技术名称和标签等细节,如下所示。
请参阅“SAP HANA中的图形计算视图”获取计算视图的完整信息。
第三步:
我们可以在屏幕的左侧看到“Rank”节点。 单击该节点,再次在设计区域上单击,以将节点添加到我们的设计区域,如下所示。
第四步:
一旦节点添加到设计区域,让我们将所需的表添加到节点,并查看可用于排名节点的设置。
可用的设置有:
1、SORT DIRECTION
2、THRESHOLD
3、ORDER BY
4、PARTITION
5、Dynamic Partition Elements
6、Generate Rank Column
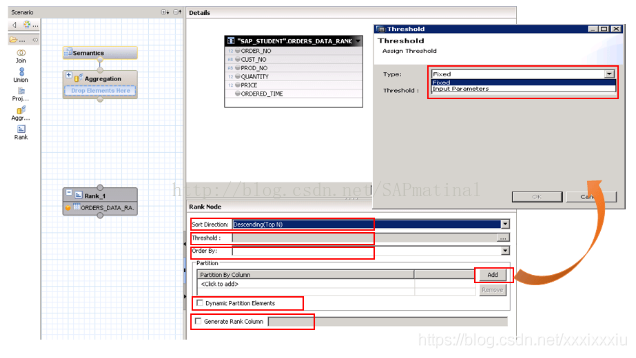
Sort Direction:
此选项用于根据我们定义的阈值获取顶部记录或底部记录。
我们在这里有两个选择,他们是
降序(前N):这从源集合中检索前N个记录,其中N是我们定义的阈值。
升序(底部N):这从源数据中检索底部N个记录,其中N是我们定义的阈值。
在我们需要最近更改的记录的情况下,我们将选择“降序(前N个)”选项。
Threshold:
该值由系统用于在计算RANK之后过滤结果数据集。 如果我们将它定义为“1”,系统只给出基于分区和顺序的第一个记录。
该阈值可以是“固定”值或用户输入参数。 在我们的例子中,我们将这个定义为“fixed”并赋值5。
ORDER BY:
此列用于在系统执行分区子句后执行Order By。
在我们的示例中,我们需要根据ORDERED_TIME列以降序排列销售订单,因此我们将在Order By列中添加ORDERED_TIME。
Partition:
此列用于根据我们定义的列对源数据集进行分区。
这与我们在SQL脚本中编写RANK函数相同。 对于我们的场景,分区列将是“ORDER_NO”。
我们可以添加分区列与右侧的“添加”按钮的帮助。
Dynamic Partition Elements:
如果要在此模型上运行查询时,基于我们选择的列执行分区操作,则需要选中此选项。
Generate Rank Column:
如果我们需要在输出中将rank作为附加列,那么应该选择此选项。

转自: