Amazon Simple Storage Service,简称 S3 服务,是 AWS 2006 年推出的第一个服务,用于提供对象存储服务。其在可拓展性,数据可用性,安全性和性能都有着非常不错的体验,而且宣称可以存储无限的数据。
块存储,对象存储,文件存储
在介绍 S3 前,我们还是先来看下什么是对象存储服务,以及和文件存储,块存储有什么区别。
块存储:
块存储直接提供最原始的磁盘空间给主机使用,主机在使用前需要对申请到的磁盘空间,进行逻辑划分,比如 LVM 操作,划分出 N 个逻辑硬盘,然后再利用系统对其进行格式化,生成文件系统,比如像 ext4,ntfs 等等。
优点:
- 写入数据时,由于主机挂载的逻辑硬盘实际上分布在很多的物理机上,可以实现并行写入,提高读写效率。
- 可以将多块廉价的硬盘组装成一个打的逻辑硬盘,提供容量和速度。
缺点:
- 主机无法直接访问块存储的内容,需要购买光纤交换机
- 主机无法共享数据,由于其文件系统都在主机上,不同的主机可能有不同的文件系统,所以文件分享可能有存在问题。
文件存储:
理解了块存储,文件存储就很好理解了,可以将其认为是在块存储上加上了一层文件系统,而不同主机可以直接共享这个文件系统。比如常见的 SMB,FTP,NFS 文件服务器。文件存储一般都拥有目录,子目录等树状的文件结构,我们通过路径来查找文件。比如我们之间可以使用自己的笔记本,搭建一个 FTP 的服务器用于共享文件。
优点:
- 使用方便,不同主机间容易共享数据
- 便宜,访问文件存储,正常的 Internet 就可以了,不需要购买额外的光纤交换机
缺点:
- 传输速度慢,因为走以太网。
对象存储服务:
对象存储常见于各大云存储业务的提供商,比如 AWS 的 S3, 百度网盘,阿里云盘等。
对象存储整合了块存储,传输速度快。文件存储,易于共享的两大好处。
对象存储不同于块存储和文件存储,是二层一种扁平化的文件结构。当把一个文件存入时,会写入三部分的信息:
- key:唯一标识该文件的名称
- raw data:文件内容本身
- metadata:用于描述文件的一些必要信息,比如存在那几个服务上,创建时间,索引类型等等任意大小的数据。
在具体存储时,对象存储不同文件存储,将 metadata 单独写入控制节点的数据服务器,其余的服务器存储真正的文件本身。
比如我们有四台数据服务器 A,B,C,D,A 为控制节点存储 metadata ,BCD 为数据节点(称为 OSD). 这时我们写入一个文件 test.log 文件。
则该文件会被打散存入 B,C,D。而 metadata 包含该文件存储在 B,C,D 等路径信息会存放在 A 服务器上。
这样在读取时,就可以实现并发读取的效果,实现了块存储的功能。
由于对象存储会有专门的对象存储软件管理,其本身又有文件系统,自然文件也非常容易共享了。
下图参照 b 站上一个非常好的对比架构图,链接在参照中:
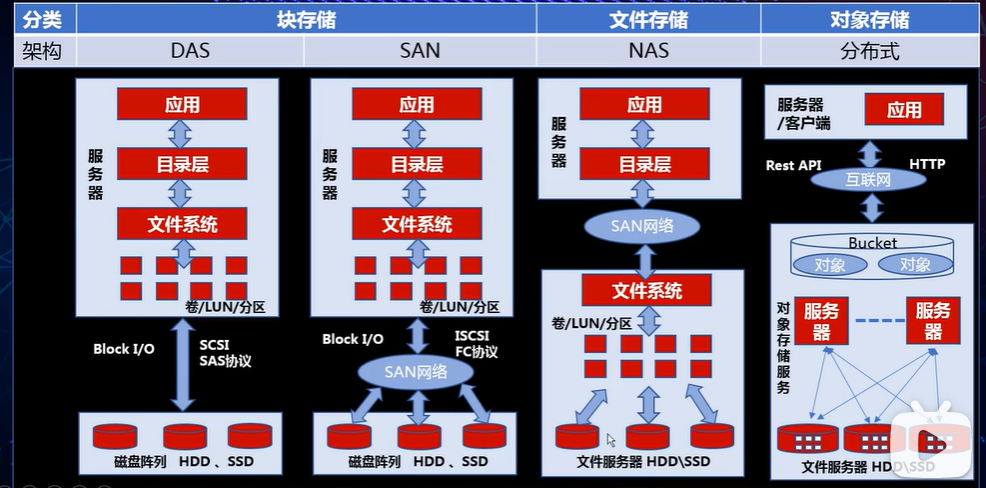
这张图很好的描述了三者之间实现的不同。
S3 介绍
在 S3 中存储中,我们将存储数据的地方叫桶,存入任意类型的数据叫对象。
在上面的介绍中,我们知道,对象存储很重要的一个概念就是 key,这里对应 S3 中桶的名字。
由于 S3 是全球跨区域的服务,所以桶的名字在全球内必须唯一,但桶的实际的存储位置只会在某一个区域。
在 S3 中,对于对象来说,通过对象的 key 和版本 ID 唯一标识一个对象。
其中 key 可以是一个完整的路径,由前缀 + 对象名称组成。
4my-organization
my.great_photos-2014/jan/myvacation.jpg
videos/2014/birthday/video1.wmv
我们可以通过 URL 来唯一访问一个 S3 保存的对象:
https://DOC-EXAMPLE-BUCKET.s3.us-west-2.amazonaws.com/photos/puppy.jpg, DOC-EXAMPLE-BUCKET
其中 DOC-EXAMPLE-BUCKET 为桶名,photos/puppy.jpg 为 key 名
S3 中的对象常由如下内容组成:
- Metadata: 元数据
- key/value: 唯一名字和对应的数据
- Tags:AWS 对许多资源都可以打 tag,方便管理
- Version ID,用于启用版本控制。
S3 权限
在 AWS 中,安全是非常重要的一部分,而访问权限是重中之重。在 aws 中,有两种访问的策略,一种是基于身份的访问。一种是基于资源策略的访问。
对于基于身份的策略,会将允许访问哪些资源的操作附加到 AWS 账户中的,用户,组和角色中。
比如在 IAM,创建了一个用户,并对这个用户授予完全访问 S3 的权限:

对于基于资源的策略,会对资源直接进行控制,允许哪类委托人进行访问。但不是所有的服务有能有基于资源的访问策略。
这部分会在下面详细说明。
在具体访问时,如果 IAM 委托人满足如下条件,才能去访问对应的资源:
- 该委托人具有 IAM 上身份的权限允许或者对应资源行有允许该委托人访问的权限。
- 同时其基于资源的策略或者基于资源的策略,没有明确的显示拒绝。
Principal - 委托人,指对 AWS 资源执行操作的人员或者应用程序。
S3 策略实践 - 为 bucket 中的对象设置公共访问
在 S3 中,基于资源的访问方式一共有两种:
- 基于 ACL 的方式进行管理,默认已经关闭,不推荐
- 基于存储桶的方式进行管理。
接下来会依次对这两种方式进行演示。在开始之前,默认已经创建了好了一个 bucket,并在里面上传了一个图片。


新建一个 bucket 后,可以看到其状态为:存储桶和对象不是公有的。这时访问 bucket 里面的对象会提示 access denied.

在 AWS 中默认是禁用公共访问的,所以在使用两种方式打开前,需要将阻止所有公开访问功能关闭。
点击创建的存储桶,选择权限。


此时该 bucket 的状态变为:对象可以是公有的。

通过 ACL 设置公共访问
ACL 的方式, AWS 默认已经关闭,原因在于 AWS 不推荐 ACL 的方式管理 bucket,而更加推荐 bucket 策略的方式。
如果需要使用 ACL,需要手动开启。

接着为想要公开的访问的对象设置公开 acl.


此时对象已经可以正常访问了。
通过存储桶策略设置公有
点击创建的存储桶,找到存储桶策略,点击编辑。

这时就可以通过 json 的方式管理存储桶了。
至于在编写策略时可以通过参考策略示例和策略生成器两种编写策略,这里以策略生成器为例,自动生成一个读取对象的策略。
其中 Principal 等编写方式,可以参考这篇文档

然后将生成的策略,粘贴:

version 表示 api 版本
此时改存储桶的状态变为公开,自然改对象也可以正常访问了。

S3 版本控制
S3 支持为桶中的文件开启版本控制,但需要在桶级别开启。开启版本控制后:
- 可以保护意外删除的对象
- 回滚到之前的版本
点击所在桶的属性,打开版本控制。再次上传一个同名的文件,点击显示版本后,可以查看上传的同名文件。

这里有一点需要注意,就是当显示版本处于 disable 状态时,删除对象,并不会真正的删除,只是标记了删除。
这种标记删除的方式,由于依然占用存储空间,所以是继续收费的。
这里我们将文件删除后,发现在显示版本 disable 的情况下,是无法看到文件的,只有将显示版本打开后,删除才能真正删除。

将删除标记删除后,就可恢复之前的文件版本。同理选择三个文本,删除后就是永久删除。
S3 跨域
CORS(跨资源共享)是一种基于 HTTP 头的机制,让浏览器去访问除了自己本身这台服务器以外其他服务器的资源。
处于安全性的考虑,浏览器仅允许同源资源的访问,当请求资源的 origin(域名,协议或者端口)三者中只有出现一个不同,浏览器会出现跨域报错问题。
但在一些场景下,必须要加载其他服务器上的资源,比如需要一些字体,一些图片等等需求。比如在如下场景中,一个站点需要加载 domain-a,domain-b 两个站点的资源。

解决跨域问题有两种方式:
- 对于简单请求,通过在服务器上增加
Access-Control-Allow-Originheader 来允许访问 - 对于一些除简单请求外的请求,需要先通过预检请求,以获知服务器是否允许该请求。
对于简单请求和其他请求可以查看这篇文档
下面描述了非简单流程跨域的过程:

由于 S3 还有托管静态网站的功能,数据都存储在不同的 bucket,也就意味着想访问资源时 domain 不同,存在跨域问题。
这时就通过编辑 bucket 的 CORS 打开相应功能:

S3 加密
在谈到 S3 加密时,一般会从两个纬度谈论数据保护:
- 数据传输:比如在上传或者下载,或者在多个 S3 bucket 间复制数据时,这时我们就需使用 SSL/TLS 加密或者在客户端上传时加密
- 静态:存储在 S3 服务的硬盘上,以加密的形式保存。
- 在 S3 服务端,可以通过如下三种方式
- SSE-S3:使用具有 Aws S3 托管密匙的服务器端加密
- SSE-KMS:在 Key Management Service 中存储客户主密匙的服务器端加密
- SSE-C:使用用户自己的提供的密匙进行加密
- 在客户端:
- 客户上传加密后的内容
- 在 S3 服务端,可以通过如下三种方式
S3 日志
有时出于一些审计的需要,需要记录所有对 S3 的操作。
这时可以将 S3 的日志功能打开,然后将访问的操作,记录在另一个 Bucket 中。
需要注意的是,不用把日志存在自己的 bucket 中,这样会导致递归 Bucket 快速增大。
具体操作可以查看这篇文档
S3 复制
有时为了保证数据的可用性,会开启 S3 复制的功能,将一个桶中的数据,拷贝到另一个桶中。
在复制前,需要在两个桶都开启版本控制,并设置合适的 IAM 权限,而且桶可以属于不同的 aws 账号。
复制共有两种方式:
- 跨区域复制,CRR:一般用于合规,低延迟访问,跨账号复制等
- 同区域复制,SRR:日志聚合,在生成和测试账号间复制
S3 存储类别
处于不同的使用目的以及价格,S3 存储类别可分为:
- S3 Intelligent-Tiering,可自动为具有未知或不断变化的访问模式的数据节省成本;
- S3 Standard,适用于频繁访问的数据;
- S3 Standard-Infrequent Access (S3 Standard-IA) :适用于访问频率较低的数据;
- S3 Glacier Instant Retrieval,适用于需要即时访问的归档数据;
- S3 Glacier Flexible Retrieval(前称为 S3 Glacier),适用于很少访问且不需要即时访问的长期数据;
- Amazon S3 Glacier Deep Archive (S3 Glacier Deep Archive),适用于以最低的云存储成本进行长期归档和数字保存。