回应大家的要求,特地整理了一开始自己整合的代码,这样最简单,最直接的可以分析流程,至于文章里面提供的程序界面更多,需要大家自己开发。
服务器在抓取和处理同时进行,所以访问速度慢是有些的,特别是搜索速度通过SQL的like来查询慢,正在通过分词改进中。。
DHT抓取程序开源地址:https://github.com/h31h31/H31DHTDEMO
数据处理程序开源地址:https://github.com/h31h31/H31DHTMgr
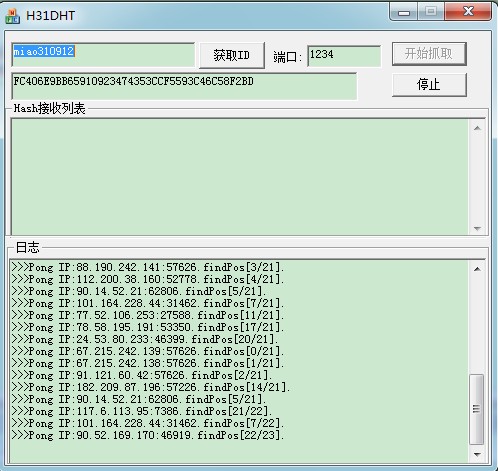
通过调试程序大家可以初步分析DHT网络是如何加入的,等大家自己分析会了单一线程的方法,后面如何组织多线程应该没有问题。
接着 [搜片神器]之DHT网络爬虫的代码实现方法 这篇文章接着说明如何进入DHT网络的原理。
1.DHT必须把自己电脑当服务器,别人才能够知道自己是谁,所以需要通过UDP绑定端口。
2.DHT需要生成一个自己的20位ID号,当然可以通过随机一个数值,然后通过SHA1来生成20位的ID号;
3.初始化他人服务器的IP信息,这样我们就可以从他们那里查询我们要的信息;
4.对服务器进行PING操作,服务器就会回应PONG操作,这样就表明服务器活动正常.大家可以看VS调试窗口的输出信息就可以分析出一些流程方面的工作。
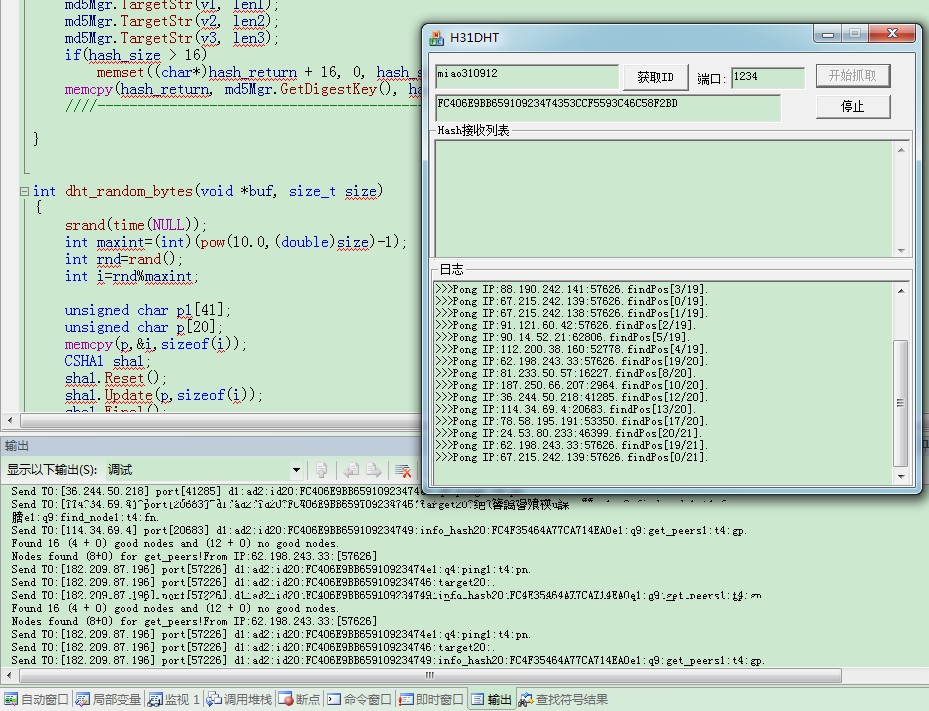
对应的协议说明:http://www.bittorrent.org/beps/bep_0005.html
5.收到信息后,通过回调函数进行相关的保存操作就可以了。
6.DHT网络一般PING操作都会有PONG回应,但发送FINDNODE回应的不会是全部有的。
7.由于自己只是伪装正常的BT步骤,并没有真正的提供种子下载操作,所以我们只会发get_peers操作,不会发送annouce_peer操作,等待别人给我们回应annouce_peer操作。
8.请求发送速度不能过快,这样的话自己的带宽也需要不少,需要考虑每个IP过一会儿再请求操作,以免进对方的黑名单。
在调试了解如何一步步进行DHT网络操作后,annouce_peer过来的HASH就是真正活跃的种子文件,我们对此保存就可以了。
其它不明白的地方,大家需要自行进行调试解决,分析代码是最好的老师,dht.c dht.h文件可能被我注释了一些地方,大家自己进行对比,尽量使用原代码。
至于如何从DHT网络直接下载种子文件,需要分析BT种子协议,但经过测试,发现比直接从HTTP网站下载来得慢,直接HTTP下载快很多。
从DHT网络直接下载种子文件对应的协议说明:
http://www.bittorrent.org/beps/bep_0009.html
http://www.bittorrent.org/beps/bep_0010.html
希望大家多多推荐哦...