补充:
在文件开头声明一个空字典,然后在每个函数前加上装饰器,完成自动添加到字典的操作
func_dic={} def make_dic(key): def deco(func): func_dic[key] = func def wrapper(*args, **kwargs): res = func(*args, **kwargs) return res return wrapper return deco @make_dic('index') # @deco #f1=deco(f1) def f1(): print('from f1') @make_dic('home') def f2(): print('from f2') @make_dic('auth') def f3(): print('from f3') print(func_dic) while True: cmd = input('>>: ').strip() if cmd in func_dic: func_dic[cmd]() 结果: >>: index from f1 >>: home from f2 >>: auth from f3
列表解析
先来两个栗子:
s = 'hello' l = [] for i in s: res = i.upper() l.append(res) print(l) 结果: ['H', 'E', 'L', 'L', 'O']
l = [1, 2, 3, 4] l_new = [] for i in l: res = i**2 l_new.append(res) print(l_new) 结果: [1, 4, 9, 16]
接下来就是我们的列表解析:
s = 'hello' res = [i.upper() for i in s] print(res) 结果: ['H', 'E', 'L', 'L', 'O']
l = [1, 31, 73, 84, 57, 22] res = [i for i in l if i > 50] print(res) 结果: [73, 84, 57]
列表解析的形式:
for i in obj1: if 条件1: for i in obj2: if 条件2: for i in obj3: if 条件3: ...
生成器表达式
g = (i for i in range(100000000000000000000000000000000000000000000000000)) print(g) print(next(g)) #next(g) == g.__next__() print(next(g)) #next(g) == g.__next__() print(next(g)) #next(g) == g.__next__() print(next(g)) #next(g) == g.__next__() print(next(g)) #next(g) == g.__next__() 结果: <generator object <genexpr> at 0x0000000002734990> 0 1 2 3 4
注意:和[i for i in range(1000000000000000000000000000000000000000000)]的区别,有兴趣可以尝试运行此命令。。
len('hello') #'hello'.__len__() print(len('hello')) print('hello'.__len__()) 结果: 5 5
注意:
相似的原理:iter(g) #g.__iter__()
三元表达式
x = 2 y = 3 if x > y: print(x) else: print(y) res = 'aaaaa' if x > y else 'bbbbbbb' print(res) 结果: 3 bbbbbbb
def max2(x, y): # if x > y: # return x # else: # return y return x if x > y else y print(max2(1, 2)) 结果: 2
生成器函数
函数体内包含有yield关键字,该函数执行的结果是生成器
def foo(): print('first------>') yield 1 print('second----->') yield 2 print('third----->') yield 3 print('fourth----->') g = foo() print(g) from collections import Iterator print(isinstance(g, Iterator)) 结果: <generator object foo at 0x0000000001E14990> True
所以我们得到的结果:生成器就是迭代器
def foo(): print('first------>') yield 1 print('second----->') yield 2 print('third----->') yield 3 print('fourth----->') g = foo() print(g.__next__()) print(g.__next__()) print(g.__next__()) # print(g.__next__()) #StopInteration 结果: first------> 1 second-----> 2 third-----> 3
def foo(): print('first------>') yield 1 print('second----->') yield 2 print('third----->') yield 3 print('fourth----->') g = foo() for i in g: #obj=g.__iter__() #obj.__next__() print(i) 结果: first------> 1 second-----> 2 third-----> 3 fourth----->
上两例对比,我们可以看到for 自动捕捉到了StopInteration
总结:
'''
yield的功能:
1.与return类似,都可以返回值,但不一样的地方在于yield返回多次值,而return只能返回一次值
2.为函数封装好了__iter__和__next__方法,把函数的执行结果做成了迭代器
3.遵循迭代器的取值方式obj.__next__(),触发的函数的执行,函数暂停与再继续的状态都是由yield保存的
'''
def countdown(n): print('starting countdown') while n > 0: yield n n -= 1 print('stop countdown') g = countdown(5) print(g) print(g.__next__()) print(g.__next__()) print(g.__next__()) print(g.__next__()) print(g.__next__()) # print(g.__next__()) #StopInteration 结果: <generator object countdown at 0x0000000001DF4990> starting countdown 5 4 3 2 1
同样地,用for可以捕捉StopInteration。
def countdown(n): print('starting countdown') while n > 0: yield n n -= 1 print('stop countdown') g = countdown(5) print(g) for i in g: print(i) 结果: <generator object countdown at 0x0000000002144990> starting countdown 5 4 3 2 1 stop countdown
应用:tail -f a.txt
import time def tail(filepath, encoding='utf-8'): with open(filepath, encoding=encoding) as f: f.seek(0, 2) while True: # f.seek(0, 2) #不行 line = f.readline() if line: # print(line,end='') yield line else: time.sleep(0.5) g = tail('a.txt') print(g) print(g.__next__()) 结果: <generator object tail at 0x0000000001E04AF0> 1111111111
或者可以应用for:
for i in g:
print(i)
应用:tail -f a.txt | grep 'error'
import time def tail(filepath, encoding='utf-8'): with open(filepath, encoding=encoding) as f: f.seek(0, 2) while True: # f.seek(0, 2) #不行 line = f.readline() if line: # print(line,end='') yield line else: time.sleep(0.5) def grep(lines, pattern): for line in lines: if pattern in line: # print(line) yield line tail_g = tail('a.txt') print(tail_g) grep_g = grep(tail_g, 'error') print(grep_g) print(grep_g.__next__()) 结果: <generator object tail at 0x0000000001E24A98> <generator object grep at 0x0000000001E24AF0> qweerror
或者可以应用for:
for i in grep_g:
print(i)
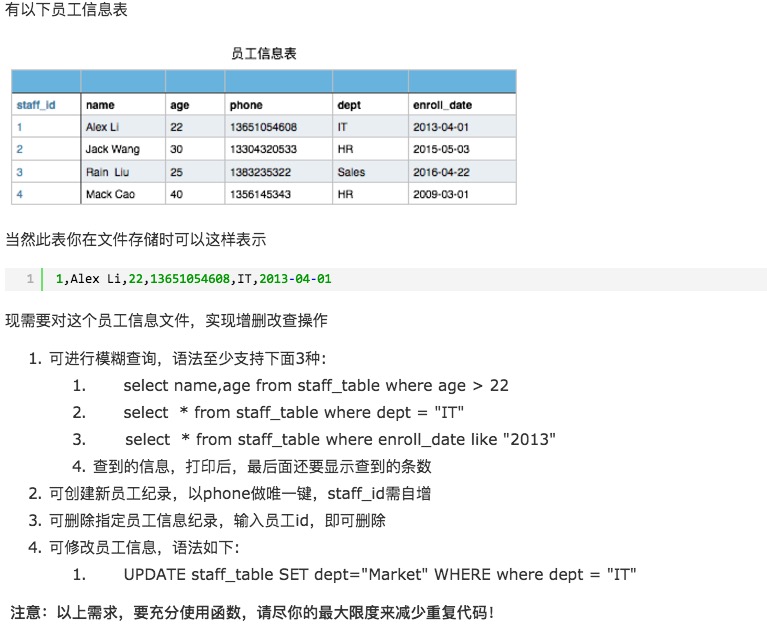
作业: 1 编写 tail -f a.txt |grep 'error' |grep '404'命令,周一默写 2 文件a.txt内容 apple 10 3 tesla 100000 1 mac 3000 2 lenovo 30000 3 chicken 10 3 要求使用列表解析,从文件a.txt中取出每一行,做成下述格式 [{‘name’:'apple','price':10,'count':3},{...},{...},...] 3 格式与2一样,但只保留价格大于1000的商品信息 4 周末大作业(见图): 只实现作业要求的查询功能 增加,删除,修改功能为选做题
答案: # 1 编写 tail -f a.txt |grep 'error' |grep '404'命令,周一默写 import time file_path = r'C:UsersAdministratorPycharmProjectsuntitleda.txt' def tail(file_path): with open(file_path, encoding='utf-8') as f: f.seek(0, 2) while True: line = f.readline() if line: yield line else: time.sleep(0.5) def grep(lines, pattern): for line in lines: if pattern in line: yield line g1 = tail('a.txt') g2 = grep(g1, 'error') g3 = grep(g2, '404') for i in g3: print(i) # 2 文件a.txt内容 # apple 10 3 # tesla 100000 1 # mac 3000 2 # lenovo 30000 3 # chicken 10 3 # # 要求使用列表解析,从文件a.txt中取出每一行,做成下述格式 # [{‘name’:'apple','price':10,'count':3},{...},{...},...] # # print([{'name': i.split()[0], 'price': i.split()[1], 'count': i.split()[2]} for i in # open('a.txt')]) print([{'name': i.strip().split()[0], 'price': i.strip().split()[1], 'count': i.strip().split()[2]} for i in open('a.txt')]) # 3 格式与2一样,但只保留价格大于1000的商品信息 # print([{'name': i.strip().split()[0], 'price': i.strip().split()[1], 'count': i.strip().split()[2]}for i in open('a.txt') if i.strip().split()[1] > '1000']) # 4 周末大作业(见图): # 只实现作业要求的查询功能 # # 增加,删除,修改功能为选做题