一、字符编码
(1)计算机基础知识
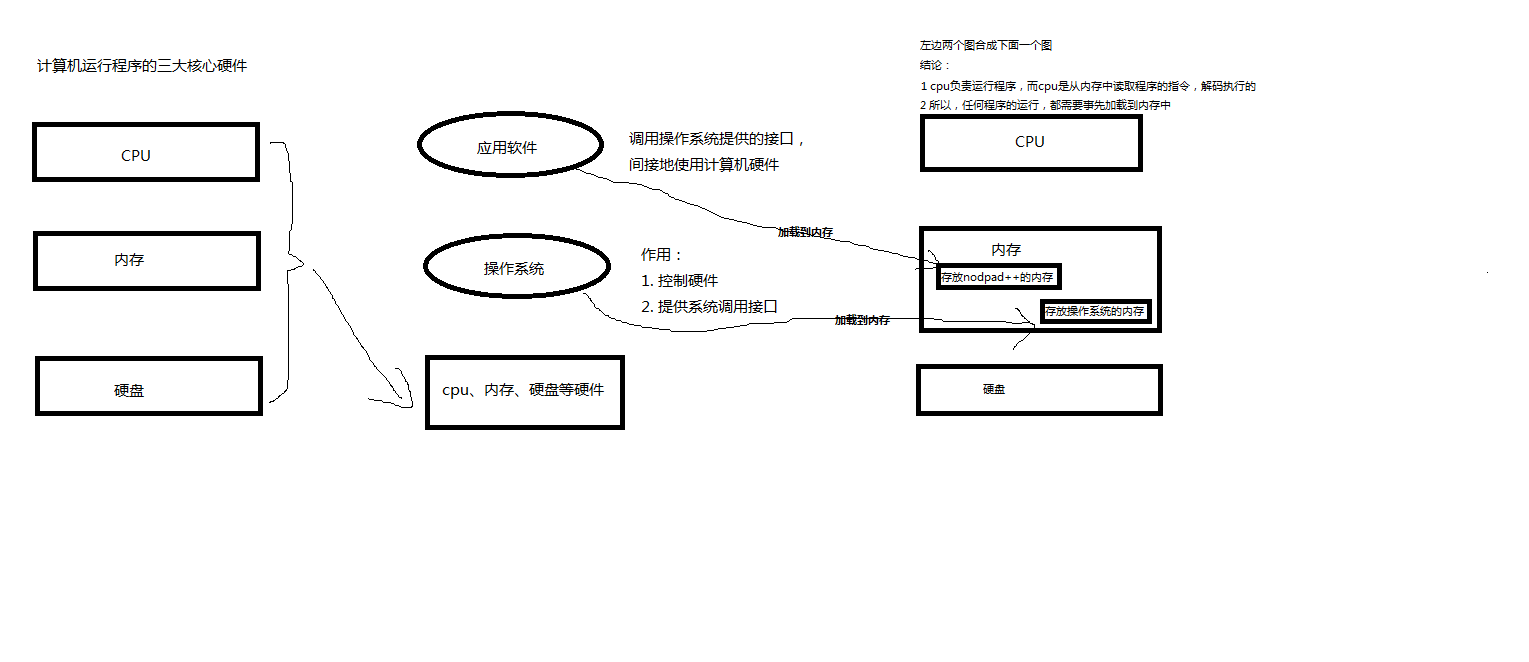
(2)python 解释器执行py文件的原理
<1>python 解释器启动
<2>python解释器相当于一个文本编辑器,打开txt.py文件,从硬盘把txt.py文件内容读到内存中
<3>python解释器解释刚刚加载到内存中的txt.py的代码(在该阶段及执行时,才会识别python的语法,执行文件内存代码,执行到name="egon",会开辟内存空间存放字符串"egon")
(3)python解释器与文本编辑的异同
相同点:python解释器是解释执行文件内容的,因而python解释器具备读py文件的功能,这一点与文本编辑器一样
不同点:文本编辑器将文本内容读入内存后,是为了显示,而python解释器将内容读入内存后,是为了执行。
二、什么是字符编码
三、字符编码的发展史
(1)计算机起源于英国,最早诞生也是基于英文的考虑ASCII
ASCII:一个Bytes代表一个字符(英文字符/键盘上的所有其他字符),1Bytes=8bit,8bit可以表示0-2**8-1种变化,即可以表示256个字符
(2)为满足中文,中国人制定了GKB
GBK:2Bytes代表一个字符
(3) 各国有各国的标准,就会不可避免地出现冲突,结果就是,在多语言混合的文本中,显示出来会有乱码。
于是产生了unicode, 统一用2Bytes代表一个字符, 2**16-1=65535,可代表6万多个字符,因而兼容万国语言
四、文件处理
<1>文件打开模式
打开文件的模式有:
- r ,只读模式【默认模式,文件必须存在,不存在则抛出异常】
- w,只写模式【不可读;不存在则创建;存在则清空内容】
- x, 只写模式【不可读;不存在则创建,存在则报错】
- a, 追加模式【可读; 不存在则创建;存在则只追加内容】
"+" 表示可以同时读写某个文件
- r+, 读写【可读,可写】
- w+,写读【可读,可写】
- x+ ,写读【可读,可写】
- a+, 写读【可读,可写】
"b"表示以字节的方式操作
- rb 或 r+b
- wb 或 w+b
- xb 或 w+b
- ab 或 a+b