scrapy-redis是一个可以scrapy结合redis搭建分布式爬虫的开源模块
scrapy-redis的依赖
- Python 2.7, 3.4 or 3.5,Python支持版本
- Redis >= 2.8,Redis版本
Scrapy>= 1.1,Scrapy版本redis-py>= 2.10,redis-py版本,redis-py是一个Python操作Redis的模块,scrapy-redis底层是用redis-py来实现的
下载地址:https://pypi.python.org/pypi/scrapy-redis/0.6.8
我们以scrapy-redis/0.6.8版本为讲
一、安装scrapy-redis/0.6.8版本的依赖
首先安装好scrapy-redis/0.6.8版本的依赖关系模块和软件
二、创建scrapy项目
执行命令创建项目:scrapy startproject fbshpch
三、将下载的scrapy-redis-0.6.8模块包解压,解压后将包里的crapy-redis-0.6.8srcscrapy_redis的scrapy_redis文件夹复制到项目中
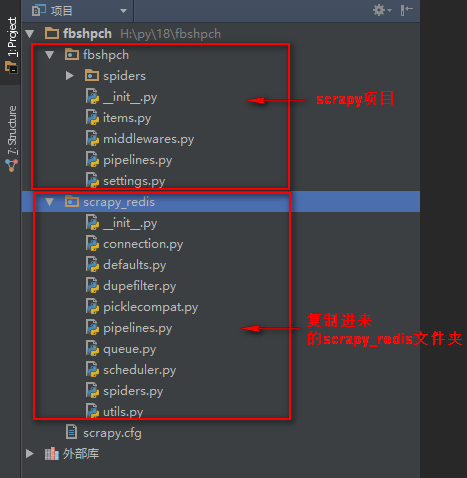
四、分布式爬虫实现代码,普通爬虫,相当于basic命令创建的普通爬虫
注意:分布式普通爬虫必须继承scrapy-redis的RedisSpider类

#!/usr/bin/env python
# -*- coding:utf8 -*-
from scrapy_redis.spiders import RedisSpider # 导入scrapy_redis里的RedisSpider类
import scrapy
from scrapy.http import Request #导入url返回给下载器的方法
from urllib import parse #导入urllib库里的parse模块
class jobboleSpider(RedisSpider): # 自定义爬虫类,继承RedisSpider类
name = 'jobbole' # 设置爬虫名称
allowed_domains = ['blog.jobbole.com'] # 爬取域名
redis_key = 'jobbole:start_urls' # 向redis设置一个名称储存url
def parse(self, response):
"""
获取列表页的文章url地址,交给下载器
"""
# 获取当前页文章url
lb_url = response.xpath('//a[@class="archive-title"]/@href').extract() # 获取文章列表url
for i in lb_url:
# print(parse.urljoin(response.url,i)) #urllib库里的parse模块的urljoin()方法,是自动url拼接,如果第二个参数的url地址是相对路径会自动与第一个参数拼接
yield Request(url=parse.urljoin(response.url, i),
callback=self.parse_wzhang) # 将循环到的文章url添加给下载器,下载后交给parse_wzhang回调函数
# 获取下一页列表url,交给下载器,返回给parse函数循环
x_lb_url = response.xpath('//a[@class="next page-numbers"]/@href').extract() # 获取下一页文章列表url
if x_lb_url:
yield Request(url=parse.urljoin(response.url, x_lb_url[0]),
callback=self.parse) # 获取到下一页url返回给下载器,回调给parse函数循环进行
def parse_wzhang(self, response):
title = response.xpath('//div[@class="entry-header"]/h1/text()').extract() # 获取文章标题
print(title)
五、分布式爬虫实现代码,全站自动爬虫,相当于crawl命令创建的全站自动爬虫
注意:分布式全站自动爬虫必须继承scrapy-redis的RedisCrawlSpider类
#!/usr/bin/env python
# -*- coding:utf8 -*-
from scrapy_redis.spiders import RedisCrawlSpider # 导入scrapy_redis里的RedisCrawlSpider类
import scrapy
from scrapy.linkextractors import LinkExtractor
from scrapy.spiders import Rule
class jobboleSpider(RedisCrawlSpider): # 自定义爬虫类,继承RedisSpider类
name = 'jobbole' # 设置爬虫名称
allowed_domains = ['www.luyin.org'] # 爬取域名
redis_key = 'jobbole:start_urls' # 向redis设置一个名称储存url
rules = (
# 配置抓取列表页规则
# Rule(LinkExtractor(allow=('ggwa/.*')), follow=True),
# 配置抓取内容页规则
Rule(LinkExtractor(allow=('.*')), callback='parse_job', follow=True),
)
def parse_job(self, response): # 回调函数,注意:因为CrawlS模板的源码创建了parse回调函数,所以切记我们不能创建parse名称的函数
# 利用ItemLoader类,加载items容器类填充数据
neir = response.css('title::text').extract()
print(neir)
六、settings.py文件配置
# 分布式爬虫设置
SCHEDULER = "scrapy_redis.scheduler.Scheduler" # 使调度在redis存储请求队列
DUPEFILTER_CLASS = "scrapy_redis.dupefilter.RFPDupeFilter" # 确保所有的蜘蛛都共享相同的过滤器通过Redis复制
ITEM_PIPELINES = {
'scrapy_redis.pipelines.RedisPipeline': 300 # 存储在redis刮项后处理
}
七、执行分布式爬虫
1、运行命令:scrapy crawl jobbole(jobbole表示爬虫名称)
2、启动redis,然后cd到redis的安装目录,
执行命令:redis-cli -h 127.0.0.1 -p 6379 连接一个redis客户端
在连接客户端执行命令:lpush jobbole:start_urls http://blog.jobbole.com/all-posts/ ,向redis列队创建一个起始URL
说明:lpush(列表数据) jobbole:start_urls(爬虫里定义的url列队名称) http://blog.jobbole.com/all-posts/(初始url)
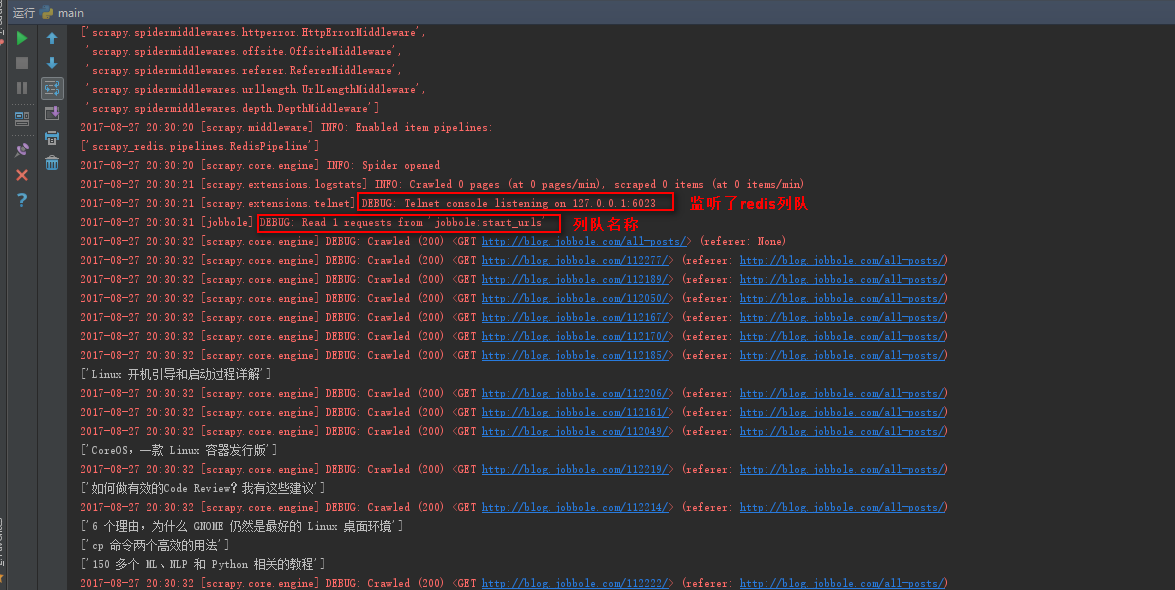
八、scrapy-redis编写分布式爬虫代码原理
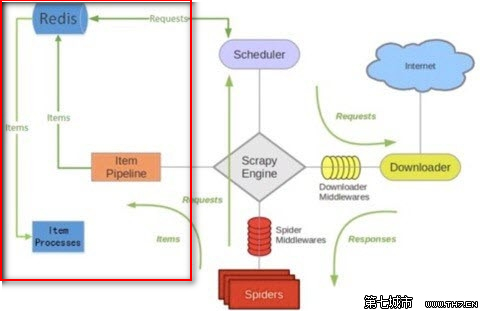
其他使用方法和单机版爬虫一样