Java基础系列2:深入理解String类
String是Java中最为常用的数据类型之一,也是面试中比较常被问到的基础知识点,本篇就聊聊Java中的String。主要包括如下的五个内容:
- String概览
- “+”连接符解析
- 字符串常量池
- String.intern()方法解析
- String、StringBuffer与StringBuilder
String概览
在Java中,所有类似“ABCabc”的字面值,都是String的实例;String类位于java.lang包下,是Java语言的核心类,提供了字符串的比较、查找、截取、大小写转换等操作;Java语言为“+”连接符以及对象转换为字符串提供了特殊支持,字符串对象可以使用“+”连接其他对象。String的部分源码如下:
public final class String
implements java.io.Serializable, Comparable<String>, CharSequence {
/** The value is used for character storage. */
private final char value[];
/** Cache the hash code for the string */
private int hash; // Default to 0
...
}
从上面的源码可以看出:
- String类被final关键字修饰,意味着String类时不可变类,不能被继承,并且其成员value也是final的,因此字符串一旦创建就不能再修改;
- String类实现了Serializable、CharSequence、Comparable接口;
- String实例的值是通过字符数组实现字符串存储的。
“+”连接符解析
“+”连接符的实现原理
Java语言为“+”连接符以及对象转换为字符串提供了特殊的支持。其中字符串连接是通过StringBuilder及其append方法实现的,对象转换字符串是通过toString方法实现的,toString方法由Object类实现,并可被Java中的所有类继承。用个简单的例子来验证“+”连接符的实现原理:
// 测试代码
public class Test {
public static void main(String[] args) {
int i = 2;
String str = "abc";
System.out.println(str + i);
}
}
// 反编译后
public class Test {
public static void main(String args[]) {
byte byte0 = 10;
String s = "abc";
System.out.println((new StringBuilder()).append(s).append(byte0).toString());
}
}
由反编译后的代码可以看出,Java使用“+”连接字符串对象时,JVM会创建一个StringBuilder对象,并调用其append方法将字符串连接,最后调用StringBuilder对象的toString方法返回拼接好的字符串。所以在实际代码编写中,使用“+”来拼接字符串和使用StringBuilder对象的append方法来拼接字符串对象是等价的。
“+”连接符的注意事项
“+”的效率
使用“+”连接符时,JVM会隐式创建StringBuilder对象,这种方式在大部分情况下并不会造成效率的损失,不过在进行大量循环拼接字符串时则需要注意。因为大量StringBuilder创建在堆内存中,必然会造成效率的损失,所以这种情况建议在循环体外创建一个StringBuilder对象调用append方法手动拼接。
字符串常量的优化
String s = "hello" + "world!";
// 反编译后
String s0 = "helloworld!";
/**
* 编译期确定
* 对于final修饰的变量,它在编译时被解析为常量值的一个本地拷贝存储到自己的常量池中或嵌入到它的字节码流中。
* 所以此时的"a" + s1和"a" + "b"效果是一样的。故结果为true。
*/
String s0 = "ab";
final String s1 = "b";
String s2 = "a" + s1;
System.out.println((s0 == s2)); // true
/**
* 编译期无法确定
* 这里面虽然将s1用final修饰了,但是由于其赋值是通过方法调用返回的,那么它的值只能在运行期间确定
* 因此s0和s2指向的不是同一个对象,故上面程序的结果为false。
*/
String s0 = "ab";
final String s1 = getS1();
String s2 = "a" + s1;
System.out.println((s0 == s2)); // false
public String getS1() {
return "b";
}
综上,“+”连接符对于直接相加的字符串常量效率很高,因为在编译期间便确定了它的值,也就是说形如"hello"+"java"; 的字符串相加,在编译期间便被优化成了"Ilovejava"。对于间接相加(即包含字符串引用,且编译期无法确定值的),形如s1+s2+s3; 效率要比直接相加低,因为在编译器不会对引用变量进行优化。
字符串常量池
字符串常量池介绍
在Java语言中的8种基本类型和String类型,JVM都为它们提供了一种常量池的概念,常量池就类似于一个Java系统级别提供的缓存。8种基本类型的常量池都是系统协调的,String类型的常量池比较特殊,它的主要使用方法有两种:
- 直接使用双引号声明出来的String对象会直接存储在常量池中;
- 如果不是双引号声明的String对象,可以使用String提供的intern方法。intern方法是个Native方法,会从字符串常量池中查询当前字符串是否存在,若不存在就会将当前字符串放入常量池中。
由于String字符串的不可变性,常量池中一定不存在两个相同的字符串。
内存区域
在HotSpot VM中字符串常量池是通过一个StringTable类实现的,它是一个Hash表,默认值大小长度是1009;这个StringTable在每个HotSpot VM的实例中只有一份,被所有的类共享;字符串常量由一个一个字符组成,放在了StringTable上。要注意的是,如果放进String Pool的String非常多,就会造成Hash冲突严重,从而导致链表会很长,而链表长了后直接会造成的影响就是当调用String.intern时性能会大幅下降(因为要一个一个找)。在JDK6及之前版本,字符串常量池是放在Perm Gen区(也就是方法区)中的,StringTable的长度是固定的1009;在JDK7版本中,字符串常量池被移到了堆中,StringTable的长度可以通过-XX:StringTableSize=66666参数指定。至于JDK7为什么把常量池移动到堆上实现,原因可能是由于方法区的内存空间太小且不方便扩展,而堆的内存空间比较大且扩展方便。
内存的分配
在JDK6及之前版本中,String Pool里放的都是字符串常量;在JDK7.0中,由于String.intern()发生了改变,因此String Pool中也可以存放放于堆内的字符串对象的引用。请看如下代码:
String s1 = "ABC";
String s2 = "ABC";
String s3 = new String("ABC");
System.out.println(s1 == s2); // true
System.out.println(s1 == s3); // false
System.out.println(s1.intern() == s3.intern()); // true
由于常量池中不存在两个相同的对象,所以s1和s2都是指向JVM字符串常量池中的"ABC"对象。new关键字一定会产生一个对象,并且这个对象存储在堆中。所以String s3 = new String(“ABC”);产生了两个对象:保存在栈中的s3和保存在堆中的String对象。当执行String s1 = "ABC"时,JVM首先会去字符串常量池中检查是否存在"ABC"对象,如果不存在,则在字符串常量池中创建"ABC"对象,并将"ABC"对象的地址返回给s1;如果存在,则不创建任何对象,直接将字符串常量池中"ABC"对象的地址返回给s1。由于s1,s2,s3的字符串值都是在常量池中的同一个引用,所以intern()方法的返回值是相等的。
String.intern()方法解析
String.intern()方法解析
先来看一下String.intern()方法的代码和注释:
/**
* Returns a canonical representation for the string object.
* <p>
* A pool of strings, initially empty, is maintained privately by the
* class {@code String}.
* <p>
* When the intern method is invoked, if the pool already contains a
* string equal to this {@code String} object as determined by
* the {@link #equals(Object)} method, then the string from the pool is
* returned. Otherwise, this {@code String} object is added to the
* pool and a reference to this {@code String} object is returned.
* <p>
* It follows that for any two strings {@code s} and {@code t},
* {@code s.intern() == t.intern()} is {@code true}
* if and only if {@code s.equals(t)} is {@code true}.
* <p>
* All literal strings and string-valued constant expressions are
* interned. String literals are defined in section 3.10.5 of the
* <cite>The Java™ Language Specification</cite>.
*
* @return a string that has the same contents as this string, but is
* guaranteed to be from a pool of unique strings.
*/
public native String intern();
直接使用双引号声明出来的String对象会直接存储在字符串常量池中,如果不是用双引号声明的String对象,可以使用String提供的intern方法。intern 方法是一个native方法,intern方法会从字符串常量池中查询当前字符串是否存在,如果存在,就直接返回当前字符串;如果不存在就会将当前字符串放入常量池中,之后再返回。
String.intern()的使用
来看看使用和不使用intern()的执行过程,在用new String("ABC")实例化String对象的时候,如果使用了intern方法,那么会先去字符串常量池中去查找是否有值为"ABC"的字符串,找到了就不会创建新的"ABC"字符串,找不到才会去创建新的"ABC"字符串;如果不使用intern方法,则没有去常量池查找的过程,会直接创建新的"ABC"字符串。可以看出二者的区别是:
- 使用intern(),实际创建的对象数目是少于需要创建的对象数目的,因为会有常量池的字符串共享;但相应的,所需要的常量池的查询消耗会增加时间损耗;这体现出的是一种空间友好,不需要太多gc来回收空间;
- 不使用intern(),实际需要多少对象,就会创建多少对象,因此会有大量的重复值的String对象出现;但相应的,少了查询的消耗,时间损耗会少一些;这体现出的是一种时间友好。
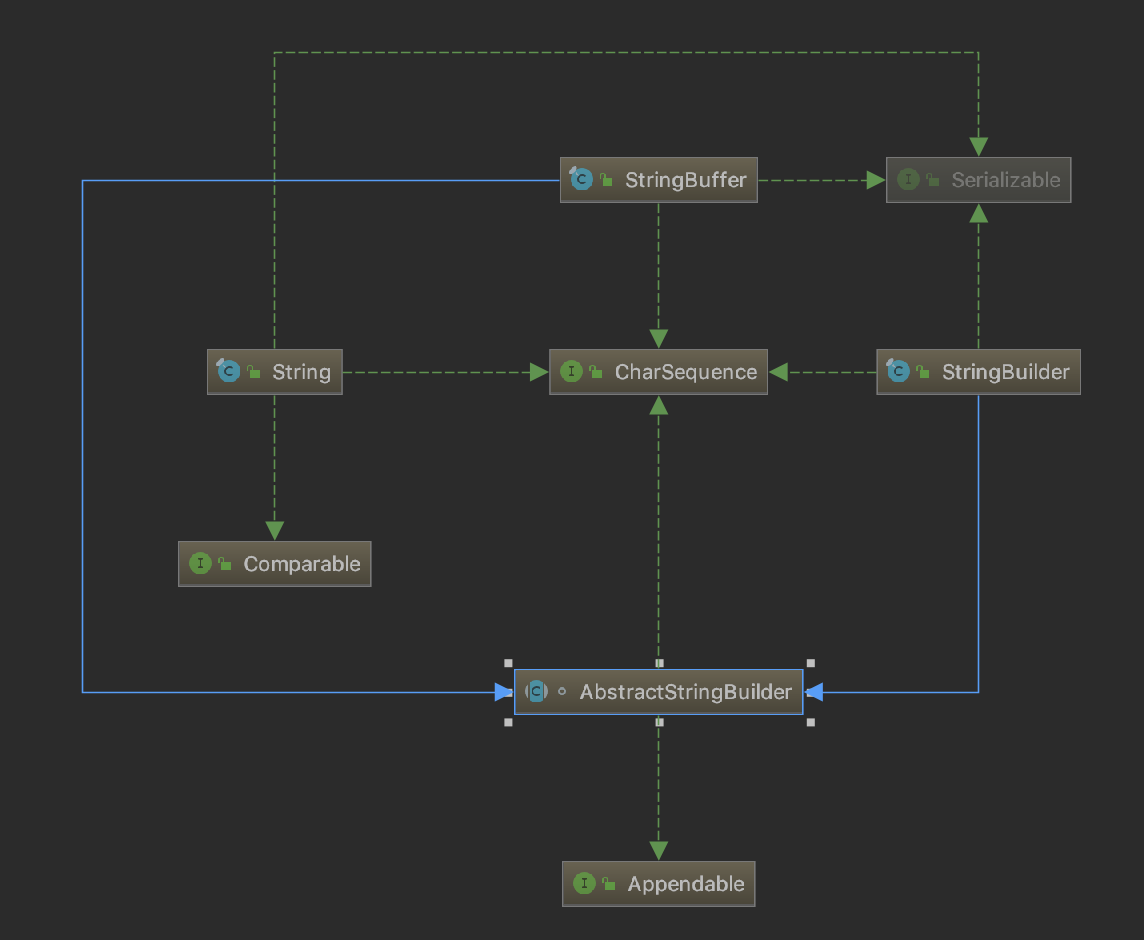
String、StringBuffer与StringBuilder
类图
主要区别
- String是不可变字符序列,StringBuilder和StringBuffer是可变字符序列;
- StringBuilder是非线程安全的,StringBuffer是线程安全的,其线程安全是通过在成员方法上添加synchronized关键字来实现的;
- 执行效率上,StringBuilder > StringBuffer > String
总结
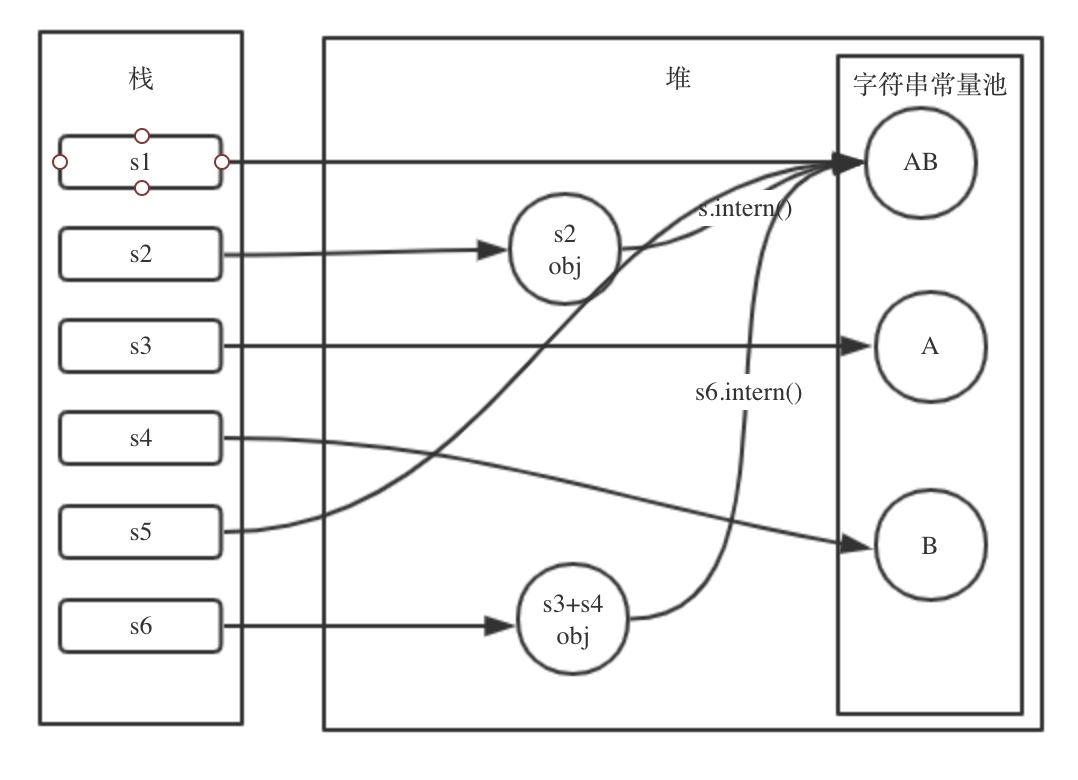
综上,我们再通过一个例子来测验以上的学习成果:
String s1 = "AB";
String s2 = new String("AB");
String s3 = "A";
String s4 = "B";
String s5 = "A" + "B";
String s6 = s3 + s4;
System.out.println(s1 == s2); // false
System.out.println(s1 == s2.intern()); // true
System.out.println(s1 == s5); // true
System.out.println(s1 == s6); // false
System.out.println(s1 == s6.intern()); // true
要理解此题目,需要搞清楚以下三点:
- 直接使用双引号声明出来的String对象会直接存储在常量池中;
- String对象的intern方法会得到字符串对象在常量池中对应的引用,如果常量池中没有对应的字符串,则该字符串将被添加到常量池中,然后返回常量池中字符串的引用;
- 字符串的+操作其本质是创建了StringBuilder对象进行append操作,然后将拼接后的StringBuilder对象用toString方法处理成String对象。
看一下以上的6个String对象在内存的分布情况:
【参考资料】https://tech.meituan.com/2014/03/06/in-depth-understanding-string-intern.htmlhttps://docs.oracle.com/javase/8/docs/api/https://blog.csdn.net/ifwinds/article/details/80849184
关注我的公众号,获取更多关于面试、技术的文章及福利资源。
