图像聚类,将一堆各种各样原始图像文件中,通过算法模型进行图片特征提取,然后采用聚类算法对特征进行聚类,将相似的图片进行分组归为一类。这里介绍K-means算法对特征进行聚类,可应用于测试数据的清洗、数据的搜索。
特征提取
-
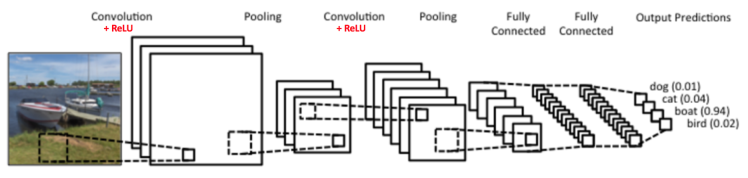
首先介绍下用到的算法模型:Vgg16卷积网络模型,CNN模型的一种。CNN为卷积神经网络,常见的结构如图
-
图片特征提取代码
from keras.applications.vgg16 import VGG16
from keras.preprocessing import image
from keras.applications.vgg16 import preprocess_inputimport numpy as np
from numpy import linalg as LA
import io
from PIL import Image
model = VGG16(weights='imagenet', pooling='max', include_top=False)
img_path = 'test.jpg'
# 加载图像有两种方式,区别图像来源是本地的还是网络传输的bytes
# 方式一
img = image.load_img(img_path, target_size=(224, 224)) # 加载图像,对象为PIL Image实例
# 方式二
img_bytes = open(img_path, 'rb').read()
img = Image.open(io.BytesIO(img_bytes))
img = img.convert('RGB')
img = img.resize((224, 224), Image.NEAREST)
def RemoveBlackEdge(img):
"""移除图片黑边,防止无用的黑边进行的干扰
Args:
img: PIL image 实例
Returns:
PIL image 实例
"""
width = img.width
img = image.img_to_array(img)
img_without_black = img[~np.all(img == np.zeros((1, width, 3), np.uint8), axis=(1, 2))]
img = image.array_to_img(img_without_black)
return img
img = RemoveBlackEdge(img)
x = image.img_to_array(img)
x = np.expand_dims(x, axis=0)
x = preprocess_input(x)
features = model.predict(x) # 这里提取出来的 feature 就是特性向量。
norm_feat = feat[0]/LA.norm(feat[0]) # 方便后续操作,将特征向量归一化处理
图片聚类
from sklearn.pipeline import make_pipeline
from sklearn.preprocessing import StandardScaler
from sklearn.cluster import KMeans
import pandas as pd
import numpy as np
# 特征长度512
features = [
[],
[]
]
# 图像名称
names = ['', '']
df = pd.DataFrame(features)
name_df = pd.DataFrame(names)
samples = df.values
kmeans=KMeans(n_clusters=3) # n_clusters分组数量
kmeans.fit(samples) # 训练模型
labels=kmeans.predict(samples) # 预测
name_df[labels==1]
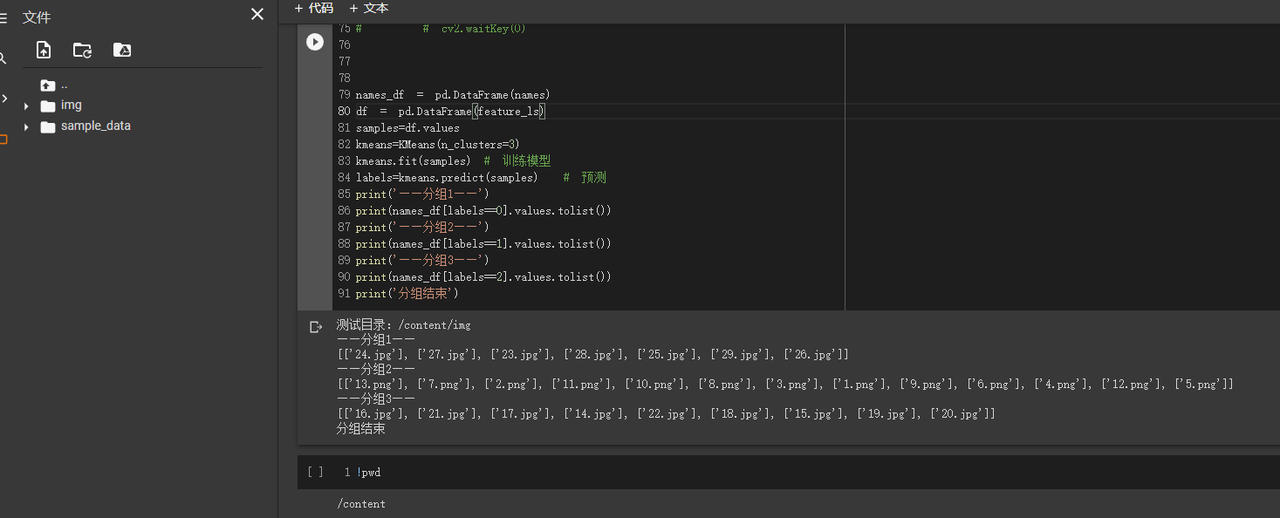
测试脚本
from keras.applications.vgg16 import VGG16
from keras.preprocessing import image
from keras.applications.vgg16 import preprocess_input
import os
import numpy as np
import pylab
import io
from PIL import Image
from numpy import linalg as LA
from sklearn.cluster import KMeans
test_path = '/content/img'
model = VGG16(weights='imagenet', pooling='max',include_top=False) #这里也可以使用自己的数据集进行训练
def RemoveBlackEdge(img):
"""移除图片黑边,防止无用的黑边进行的干扰
Args:
img: PIL image 实例
Returns:
PIL image 实例
"""
width = img.width
img = image.img_to_array(img)
img_without_black = img[~np.all(img == np.zeros((1, width, 3), np.uint8), axis=(1, 2))]
img = image.array_to_img(img_without_black)
return img
def get_image_feature(path):
img = Image.open(path)
img = img.convert('RGB')
img = img.resize((224,224), Image.NEAREST)
img = RemoveBlackEdge(img) # 移除黑边
x = image.img_to_array(img)
x = np.expand_dims(x, axis=0)
x = preprocess_input(x)
features = model.predict(x)
return features[0]
feature_ls = []
names = []
for name in os.listdir(test_path):
features = get_image_feature(os.path.join(test_path, name))
#特征归一化
vec = features/LA.norm(features)
# print(name,"==", vec.tolist())
names.append(name)
feature_ls.append(vec.tolist())
df = pd.DataFrame(feature_ls)
names_df = pd.DataFrame(names)
samples=df.values
kmeans=KMeans(n_clusters=3)
kmeans.fit(samples) # 训练模型
labels=kmeans.predict(samples) # 预测
print(labels, names_df[labels==0] )
print(labels, names_df[labels==1] )
print(labels, names_df[labels==2] )
案例运行
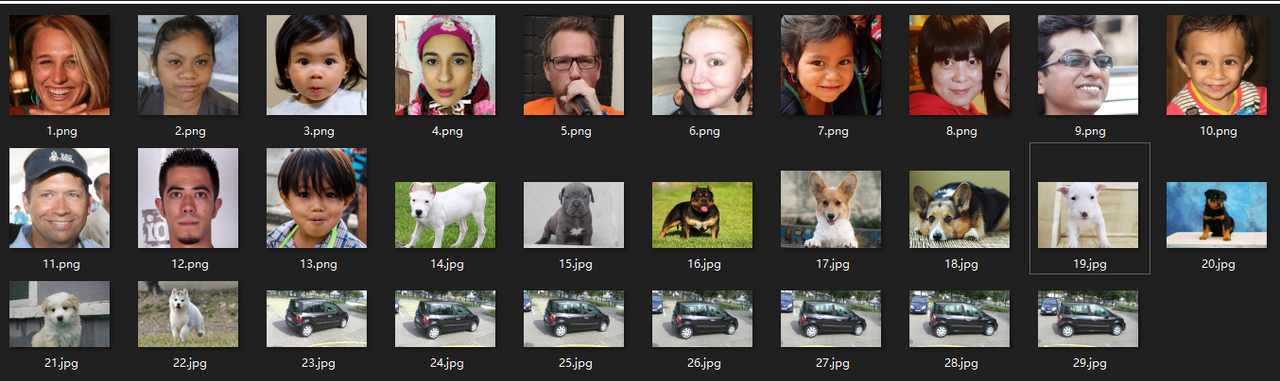
- 这里收集了一些各种各样的图片,可以看到包括
- 人脸:1-13
- 狗:14-22
- 车辆:23-29
google colab代码
https://colab.research.google.com/drive/1XkdM5Qvioysdn3zUPr2N2a_aQGX3Ifhw?usp=sharing
- 结果可以看到图片名称按照正确的预期类别成功分类到对应的分组