import java.io.BufferedReader; import java.io.File; import java.io.FileReader; import java.io.IOException; import java.util.Random; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.Path; import org.apache.log4j.Logger; import org.apache.parquet.example.data.Group; import org.apache.parquet.example.data.GroupFactory; import org.apache.parquet.example.data.simple.SimpleGroupFactory; import org.apache.parquet.hadoop.ParquetReader; import org.apache.parquet.hadoop.ParquetReader.Builder; import org.apache.parquet.hadoop.ParquetWriter; import org.apache.parquet.hadoop.example.GroupReadSupport; import org.apache.parquet.hadoop.example.GroupWriteSupport; import org.apache.parquet.schema.MessageType; import org.apache.parquet.schema.MessageTypeParser; public class ReadParquet { static Logger logger=Logger.getLogger(ReadParquet.class); public static void main(String[] args) throws Exception { // parquetWriter("test\parquet-out2","input.txt"); parquetReaderV2("test\parquet-out2"); } static void parquetReaderV2(String inPath) throws Exception{ GroupReadSupport readSupport = new GroupReadSupport(); Builder<Group> reader= ParquetReader.builder(readSupport, new Path(inPath)); ParquetReader<Group> build=reader.build(); Group line=null; while((line=build.read())!=null){
Group time= line.getGroup("time", 0);
//通过下标和字段名称都可以获取
/*System.out.println(line.getString(0, 0)+" "+
line.getString(1, 0)+" "+
time.getInteger(0, 0)+" "+
time.getString(1, 0)+" ");*/
System.out.println(line.getString("city", 0)+" "+
line.getString("ip", 0)+" "+
time.getInteger("ttl", 0)+" "+
time.getString("ttl2", 0)+" ");
//System.out.println(line.toString());
} System.out.println("读取结束"); } //新版本中new ParquetReader()所有构造方法好像都弃用了,用上面的builder去构造对象 static void parquetReader(String inPath) throws Exception{ GroupReadSupport readSupport = new GroupReadSupport(); ParquetReader<Group> reader = new ParquetReader<Group>(new Path(inPath),readSupport); Group line=null; while((line=reader.read())!=null){
System.out.println(line.toString());
}
System.out.println("读取结束");
}
/**
*
* @param outPath 输出Parquet格式
* @param inPath 输入普通文本文件
* @throws IOException
*/
static void parquetWriter(String outPath,String inPath) throws IOException{
MessageType schema = MessageTypeParser.parseMessageType("message Pair {
" +
" required binary city (UTF8);
" +
" required binary ip (UTF8);
" +
" repeated group time {
"+
" required int32 ttl;
"+
" required binary ttl2;
"+
"}
"+
"}");
GroupFactory factory = new SimpleGroupFactory(schema);
Path path = new Path(outPath);
Configuration configuration = new Configuration();
GroupWriteSupport writeSupport = new GroupWriteSupport();
writeSupport.setSchema(schema,configuration);
ParquetWriter<Group> writer = new ParquetWriter<Group>(path,configuration,writeSupport);
//把本地文件读取进去,用来生成parquet格式文件
BufferedReader br =new BufferedReader(new FileReader(new File(inPath)));
String line="";
Random r=new Random();
while((line=br.readLine())!=null){
String[] strs=line.split("\s+");
if(strs.length==2) {
Group group = factory.newGroup()
.append("city",strs[0])
.append("ip",strs[1]);
Group tmpG =group.addGroup("time");
tmpG.append("ttl", r.nextInt(9)+1);
tmpG.append("ttl2", r.nextInt(9)+"_a");
writer.write(group);
}
}
System.out.println("write end");
writer.close();
}
}
说下schema(写Parquet格式数据需要schema,读取的话"自动识别"了schema)
/* * 每一个字段有三个属性:重复数、数据类型和字段名,重复数可以是以下三种: * required(出现1次) * repeated(出现0次或多次) * optional(出现0次或1次) * 每一个字段的数据类型可以分成两种: * group(复杂类型) * primitive(基本类型)
* 数据类型有
* INT64, INT32, BOOLEAN, BINARY, FLOAT, DOUBLE, INT96, FIXED_LEN_BYTE_ARRAY
*/
这个repeated和required 不光是次数上的区别,序列化后生成的数据类型也不同,
比如repeqted修饰 ttl2 打印出来为 WrappedArray([7,7_a])
而 required修饰 ttl2 打印出来为 [7,7_a]
除了用MessageTypeParser.parseMessageType类生成MessageType 还可以用下面方法
(注意这里有个坑--spark里会有这个问题--ttl2这里 as(OriginalType.UTF8) 和 required binary city (UTF8)作用一样,加上UTF8,在读取的时候可以转为StringType,不加的话会报错 [B cannot be cast to java.lang.String )
/*MessageType schema = MessageTypeParser.parseMessageType("message Pair { " + " required binary city (UTF8); " + " required binary ip (UTF8); " + "repeated group time { "+ "required int32 ttl; "+ "required binary ttl2; "+ "} "+ "}");*/ //import org.apache.parquet.schema.Types; MessageType schema = Types.buildMessage() .required(PrimitiveTypeName.BINARY).as(OriginalType.UTF8).named("city") .required(PrimitiveTypeName.BINARY).as(OriginalType.UTF8).named("ip") .repeatedGroup().required(PrimitiveTypeName.INT32).named("ttl") .required(PrimitiveTypeName.BINARY).as(OriginalType.UTF8).named("ttl2") .named("time") .named("Pair");
解决 [B cannot be cast to java.lang.String 异常:
1.要么生成parquet文件的时候加个UTF8
2.要么读取的时候再提供一个同样的schema类指定该字段类型,比如下面:
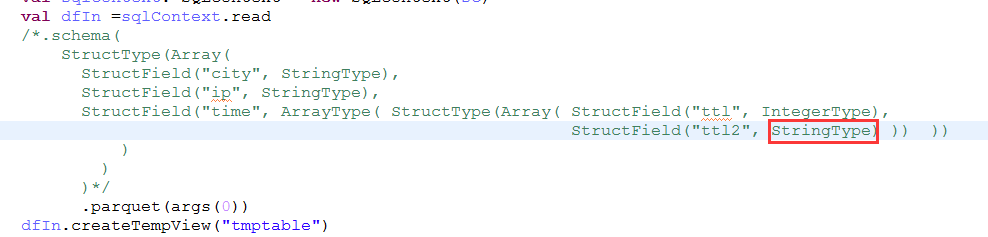
hadoop Mapreducer读写 Parquetexample
http://www.cnblogs.com/yanghaolie/p/7389543.html
maven依赖(我用的1.7)
<dependency> <groupId>org.apache.parquet</groupId> <artifactId>parquet-hadoop</artifactId> <version>1.7.0</version> </dependency>