本篇文章内容基于Shusen Wang老师的《RNN模型与NLP应用》系列课程。
课程视频链接:https://www.youtube.com/playlist?list=PLvOO0btloRnuTUGN4XqO85eKPeFSZsEqK
课件:https://github.com/wangshusen/DeepLearning
1. Tokenization & Build dictionary
token是“符号”的意思,那tokenization简单理解就是分词,比如 “我是中国人”可以分解成['我', '是', '中国人']。
假设我们需要把英语翻译成德语,那么我们首先要做的是对不同语种做tokenization(分词)。常用的分词做法是以“词”为单位,这里为方便介绍,就以字符为单位:
- 英语有26个字母,考虑大小写的话就有52个字符。
- 德语也有26个字母,还有4个特殊字符。
分词后就可以得到不同语种对应的字典,结果如下图所示。
注意不同语种之前分词的结果是不一样的,比如字符 a 在英文中的编号是1,而在德文中是3。另外因为现在的任务是讲英文翻译成德文,所以德文里额外添加了两个特殊符号: 和
分别表示起始和结束符号,你也可以用其他特殊符号,只要不与其他符号重复就可以了。

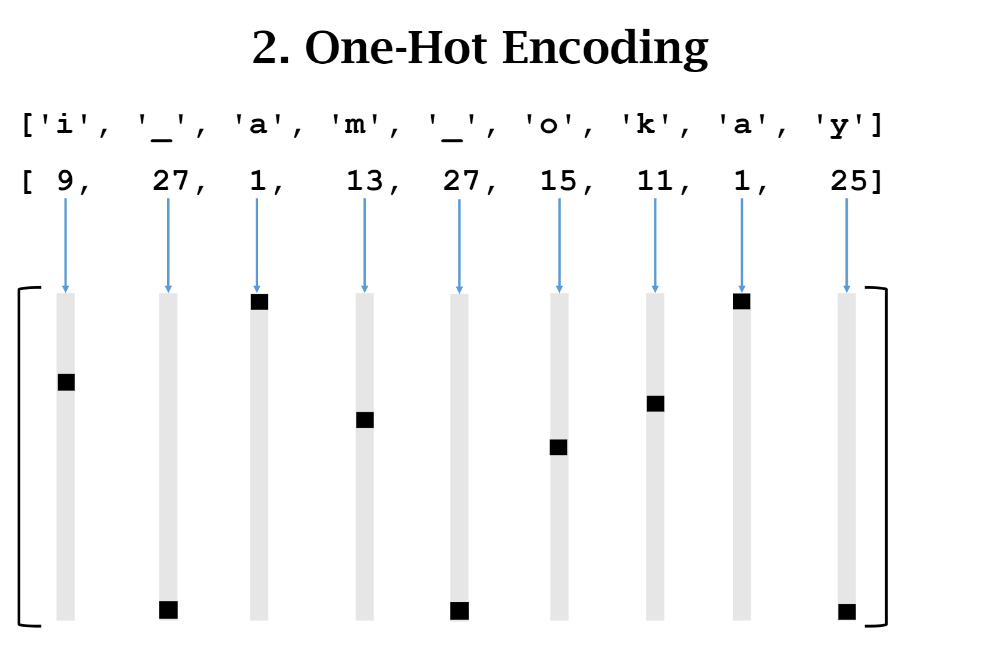
2. One-hot Encoding
分词和构建字典后,我们需要把每个字符转化成one-hot格式,如下图示。所以,每个字符有相同长度的列向量表示,其中只有一个位置的值为1,其余位置均为0。一个词或者一句话由一个矩阵表示。
3. Seq2Seq
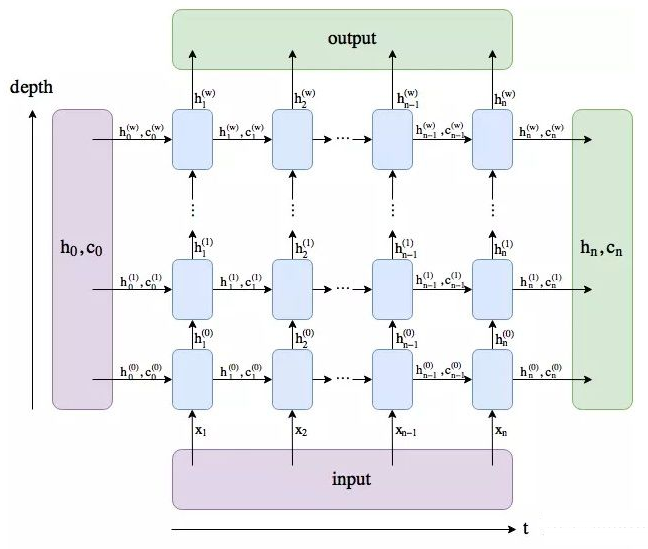
Seq2Seq由两部分组成:Encoder和Decoder。这两部分都是LSTM结构,下面分别介绍两个部分。
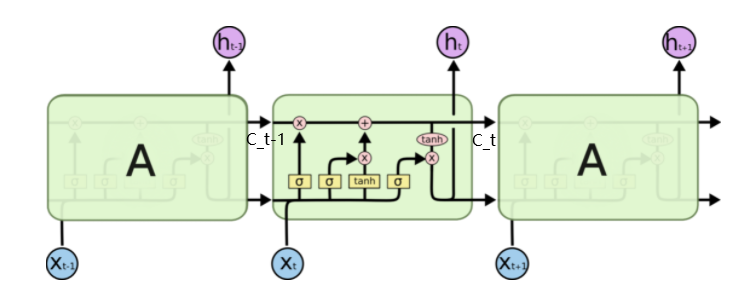
如果对LSTM不熟悉,可以看看最后给出的参考文献和下面两个示意图:
LSTM结构示意图:LSTM Cell结构示意图:
3.1 Encoder
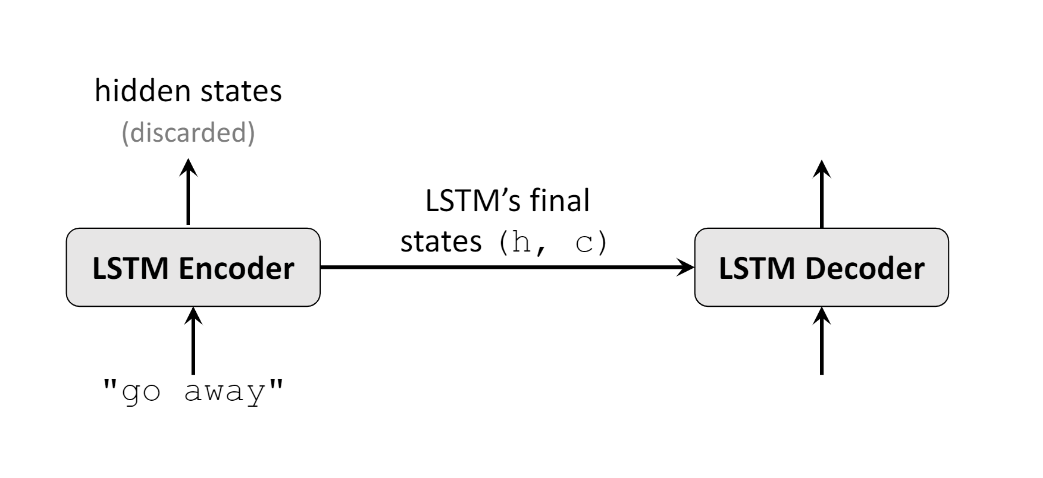
Encoder主要用来对输入的英语句子进行特征提取,它最后的输出会作为输入传给Decoder。
如下图示,传入的是英文"go away"的one-hot编码,encoder会生成很多hidden states,只不过只会保留最后的hidden state (h, c)。
3.2 Decoder
拿到了Encoder的编码结果后,此时Decoder就会开始做预测。
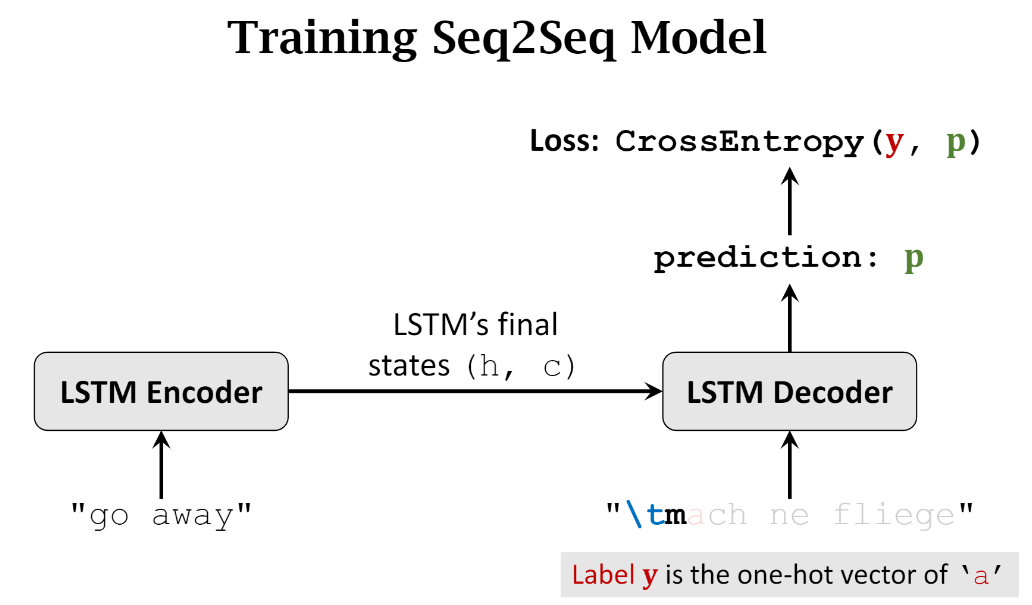
Decoder最开始的输入是起始符号 ,初始状态是Encoder传入的(h,c),基于这些会输出预测概率向量 p,这和图像分类的softmax输出类似。真实的labely就是下一个字符m的one-hot编码,之后我们可以通过计算交叉熵来更新Encoder和Decoder的参数权重。
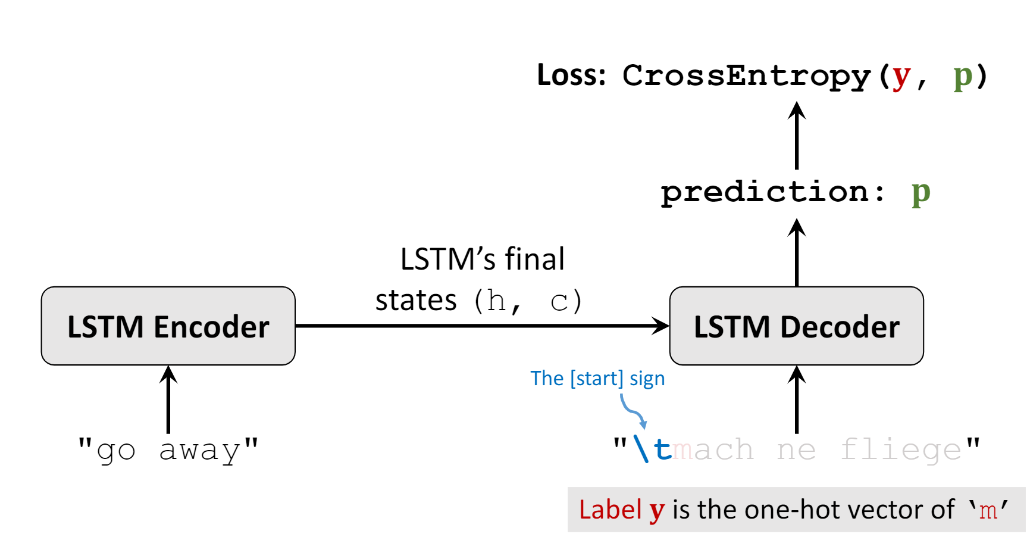
上面只是预测了一个字符,我们还需要不断预测。我们假设前一次预测的概率向量中概率最大的索引刚好就是m这个字符的索引, 即argmax(p)等于index(m),那么Decoder下一个输入值就是m的one-hot编码序列。Decoder按照前面介绍的方式不断做预测,直到预测的字符为终止符号
。
3.3 Inference
假设Seq2Seq模型训练好了,那它的inference流程是什么样的呢?
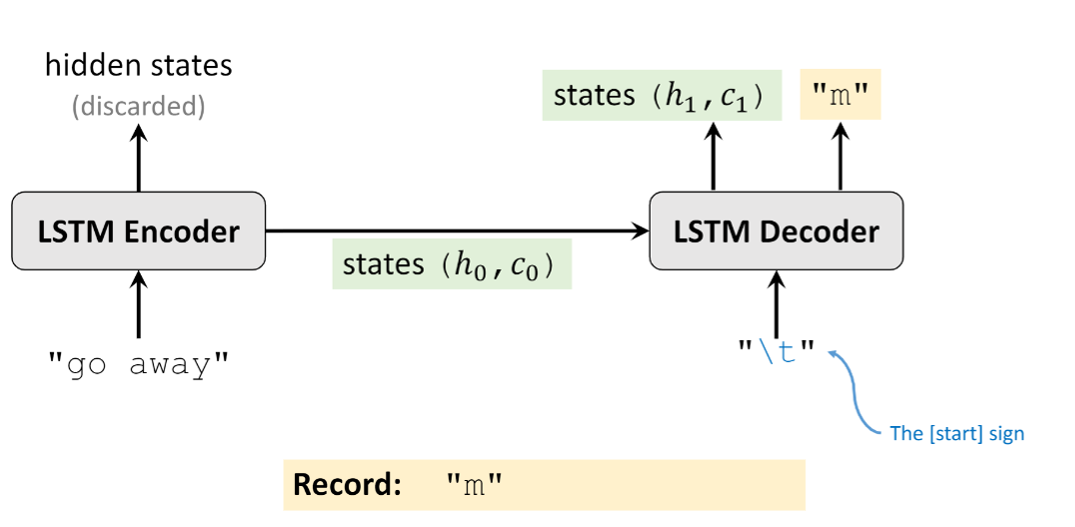
- Step 1: 首先Decoder接收Encoder的输入 ((h_0,c_0)),输入为
m
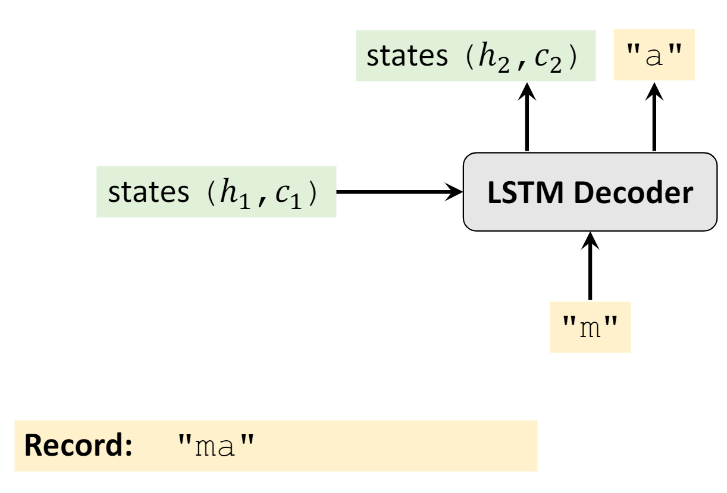
- Step 2:之后Decoder的初始状态不再是Encoder的输出,而是上一时刻的((h_1,c_1)),其输入也变成了上一时刻预测的
m - ... 重复上面的操作知道输出为
4. 总结
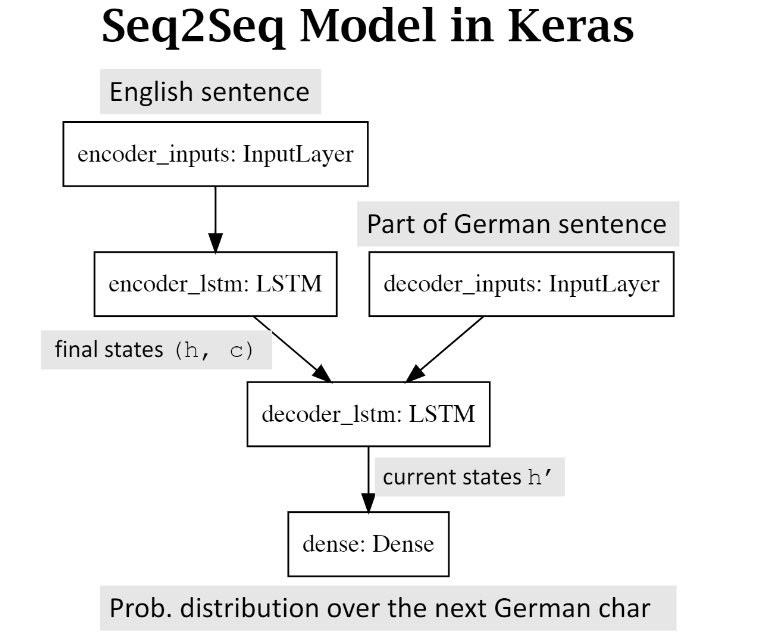
下面给出了利用Keras实现Seq2Seq的示意图,每次给Decoder传入新的输入,计算loss并更新Decoder和Encoder。
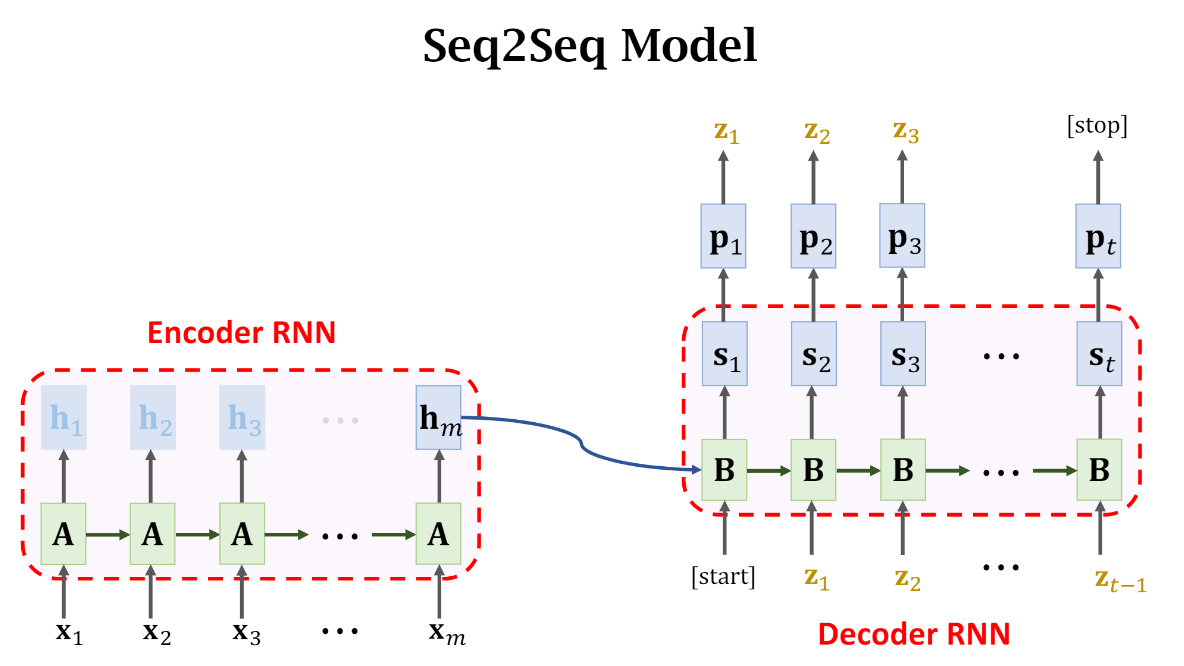
下图给出了Seq2Seq更加直观的网络结构示意图。
参考
- NLP领域中的token和tokenization到底指的是什么? - 周鸟的回答 - 知乎
https://www.zhihu.com/question/64984731/answer/292860859 - 理解Pytorch中LSTM的输入输出参数含义 - marsggbo的文章 - 知乎
https://zhuanlan.zhihu.com/p/100360301 - LSTM结构详解:https://colah.github.io/posts/2015-08-Understanding-LSTMs/