flask操作mysql数据库
orm
无论是flask框架或者django框架,都可以通过orm(Object-Relation Mapping),中文名为对象-关系映射,来通过框架内的模型类与数据库中的数据表进行映射,从而对数据表进行增删改查,模型类对应这数据表,类中的字段对应着数据库的字段,模型类的对象对应着一条表记录,对象的数据对应着表记录的对应字段属性

orm的优点:
- 不用再执行原生的sql语句,只要通过执行模型类的属性和方法就可以对数据库进行增删改查
- 通过模型类去操作数据库,当需要更换数据库的类型时,可以根据需求进行相应配置,无需修改其他代码
orm的缺点
1.不同框架直接的orm的模型类操作不一样,当使用同种语言不同框架,或者不同语言之间的orm操作语句需要重新学习
2.采用模型类对数据库进行操作,本质是底层将原生sql语句封装程成模型类的方法,所以相对于原生sql语句,操作模型类会有性能的损耗
在flask框架中,没有提供orm的操作,所以我们需要安装第三方模块来对orm进行操作,安装:
pip install flask-sqlalchemy -i https://pypi.douban.com/simple/
同时,为了能够连接数据库,需要安装mysql驱动flask-mysqldb,如果在ubuntu上第一次安装flask-mysqldb,会报错
OSError: mysql_config not found
,解决方法是通过apt先安装 libmysqlclient-dev
sudo apt-get install libmysqlclient-dev #然后安装 pip install flask-mysqldb
通过添加配置文件就可以连接数据库
from flask import Flask app = Falsk(__name__) class Config(): DEBUG = True # 数据类型://登录用户:登录密码@数据库IP或地址:端口/数据库名?charset=编码 SQLALCHEMY_DATABASE_URI = 'mysql://root:123@127.0.0.1:3306/flaskDemo?charset=utf8mb4' # 动态追踪修改设置,如未设置只会提示警告 SQLALCHEMY_TRACK_MODIFICATIONS = True #查询时会显示原始SQL语句 SQLALCHEMY_ECHO = True app.config.from_object(Config)
数据库的初始化
# 数据库初始化 from flask_sqlalchemy import SQLAlchemy db = SQLAlchemy(app)
SQLAlchemy中的常用模型类字段名或者列选项可以查看官网:
常用的模型类字段名或者列选项以及常用的查询方法点击这里查看:
模型类的创建:
class User(db.Model): __tablename__ = "user" #自定义表名 id = db.Column(db.Integer, primary_key=True, comment="ID") name = db.Column(db.String(20), comment="用户名") age = db.Column(db.SmallInteger, nullable=True, comment="年龄") sex = db.Column(db.Boolean, default=True, comment="性别") birthday = db.Column(db.DateTime, nullable=True, comment="出生日期")
创建数据表或者删除数据表,由于SQLAlchemy不提供数据迁移的命令,所以只能在程序中执行下所示程序
if __name__ == '__main__': # 创建所有表, 根据当前系统应用中模型对应的数据表 # db.create_all() # 删除所有表 # db.drop_all() app.run(host="0.0.0.0", port=8080,debug=True)
数据的增删改查
# 增 User内部的等号左边是类属性名,右边是自定义属性值 user = User(name=name,age=age,sex=sex,birthday=bitd) db.session.add(user) db.session.commit()
# 删 #先获取要删除的数据 user = User.query.first() db.session.delete(user) db.commit()
# 改 #先获取要修改的数据 user = User.query.first() # 修改属性值 user.name = "zhangsan" db.session.delete(user) db.commit()
# 查 # filter内写查询条件 user = User.query.filter().all()
数据库关系之一对多
由于mysql是一种关系型数据库,所以通常表与表之间会存在关系,而这种关系可以采用db的relationship来声明一个字段表示,通过该字段可以设置跨表查询的正向查询字段和反向查询字段,但是改属性不会再数据库生成相应字段名,所以再一张表中声明了relationshiph后,需要在另一种表设置外键,通过外键将两张表关联在一起,例如:在上面的User类的基础上添加一个外键和一个角色表Role
class Role(db.Model): ... #关键代码 改属性不会再数据表生成对应字段,通过该字段来声明正向查询通过user_list字段,反向查询通过backref对应的值role
lazy=dynamic代表懒查询,即执行语句不会真正查询,当使用数据才会去查询,当lazy=subquery就会马上查询 user_list = db.relationship('User', backref='role', lazy='dynamic') ... class User(db.Model): ... # 新增外键字段 role_id = db.Column(db.Integer, db.ForeignKey('roles.id'))
数据库关系之多对多
这种数据表的关系的两张表的其中一张表对应着另一张表的多条数据,此时我们需要第三张表来将两张表联系再一起
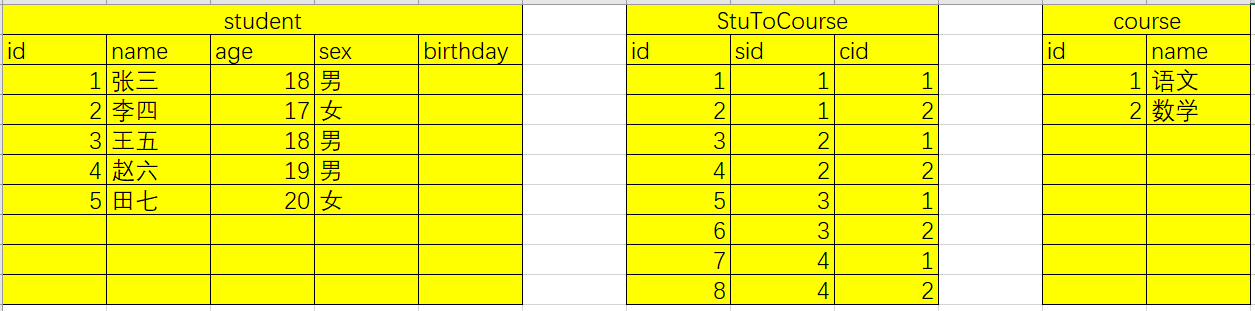
如上如,中间的StuToCourse表可以过设置外键来将studnent表和course表关联再一起,通过一对多的例子可以直到,处理设置外键以外,我们该需要设置db.relationship这个查询属性来控制student表和course的正向查询和反向查询。
再设置第三张表的时候有两种方法来设置,其中student和course表如下所示
class Student(db.Model): id = db.Column(db.Integer, primary_key=True, comment="ID") name = db.Column(db.String(20), comment="用户名") age = db.Column(db.SmallInteger, nullable=True, comment="年龄") sex = db.Column(db.Boolean, default=True, comment="性别") birthday = db.Column(db.DateTime, nullable=True, comment="出生日期") class Course(db.Model): id = db.Column(db.Integer, primary_key=True, comment="ID") name = db.Column(db.String(20), comment="等级")
方法一
通过db.talbe的方法添加第三张表,这种方法添加会弊端是无法添加其他字段:
StuToCourse = db.Table("StuToCourse", db.Column('id',db.Integer, primary_key=True, comment="ID"), db.Column("sid",db.Integer, db.ForeignKey("student.id")), db.Column("cid",db.Integer, db.ForeignKey("course.id")), )
新建第三种表后,只要再student或者course其中一张表添加db.relationship这个属性即可,如下所示
class Course(db.Model): ...... students = db.relationship("Student",secondary=StuToCourse,backref="courses",lazy="dynamic")
方法二
可以像普通表一样设置一张score表,这样我们既可以关联两张表,又可以添加分数字段来存储学生分数
class Achievement(db.Model): id = db.Column(db.Integer, primary_key=True, comment="主键ID") db.Column('score', db.Numeric, comment="分数"), student_id = db.Column(db.Integer, db.ForeignKey('tb_student.id')) course_id = db.Column(db.Integer, db.ForeignKey('tb_course.id'))
但是通过这种方法来设计表,就必须再student表和course表都写上db.relationship属性
class Student(db.Model): """学生信息""" ..... score = db.relationship('Achievement', backref='student', lazy='dynamic') class Course(db.Model): """课程信息""" ...... score = db.relationship('Achievement', backref='course', lazy='dynamic')
数据库迁移
在上文中我们知道,创建数据表和数据库只能通过添加代码db.create_all()和db.drop_all()的方法添加,那么如果项目正在运行,我们没办法添加程序怎么办,此时,我们可以通过第三方模块进行数据迁移,而这个第三方模块就是flask-migrate,改这个模块中提供的MigrateCommand提供了数据库迁移的命令
在使用这个模块之前,我们需要安装模块:pip install flask-migrate
然后,需要将添加两个配置
#第一个参数是Flask的实例,第二个参数是Sqlalchemy数据库实例 migrate = Migrate(app,db) #manager是Flask-Script的实例,这条语句在flask-Script中添加一个db命令 manager.add_command('db',MigrateCommand)
然后我们就可以通过python manage.py查看命令(执行python manage.py之前先进入执行app.run()程序所在文件目录,文件名为manage.py)
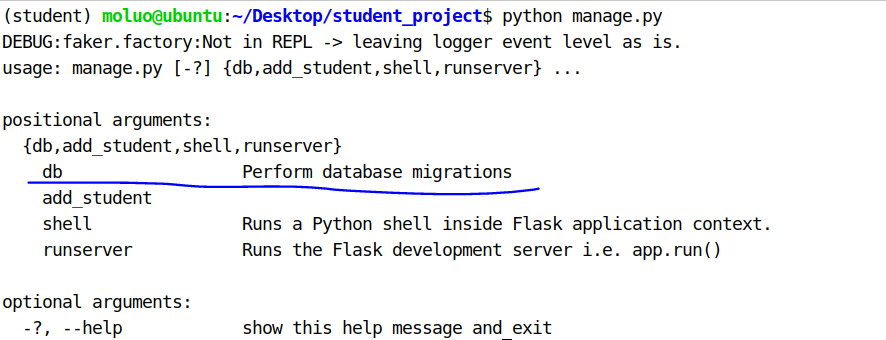
常用的迁移命令有
1. 初始化数据迁移的目录
python manage.py db init
2. 数据库的数据迁移版本初始化
python manage.py db migrate -m 'initial migration'
3. 升级版本[创建表]
python manage.py db upgrade
4. 降级版本[删除表]
python manage.py db downgrade
flask操作redis数据库
在项目中,数据一般储存在mysql中,但对于以下经常修改的数据,我们可以将它放在缓存中,所以需要直到flask是如何对redis数据库进行增删改查操作,通过将session信息存储在redis的方式连接flask如何操作redis
首先需要将保证系统中有redis,安装rendsis pip install redis
其次,将session存储在redis中,需要下载第三方模块 flask-session 安装: pip install flask-session
然后在配置文件中添加配置
from flask import Flask,session from redis import Redis from flask_session import Session #实例化Flask对象 app = Flask(__name__) class Config1: '''session采用redis方式储存''' DEBUG = True # 密钥 可以通过 base64.b64encode(os.urandom(48)) 来生成一个指定长度的随机字符串 SECRET_KEY = 'GMncFpwL1oQ2A/xIHI0K/W0BDSTuOsx++bhgW4kJIKRRAYaybmy7Gkp1GTbcO+eG' # 连接redis 参数分别是ip,端口号,数据库名 SESSION_REDIS = Redis(host="127.0.0.1", port=6379, db=0) # session类型为redis SESSION_TYPE = "redis" # 如果设置为True,则关闭浏览器session就失效。 SESSION_PERMANENT = False # 是否对发送到浏览器上session的cookie值进行加密 SESSION_USE_SIGNER = False # 保存到session中的值的前缀 SESSION_KEY_PREFIX = "session:" app.config.from_object(Config) db.init_app(app) Session(app)
通过该实例我们直到,通过Redis(host="127.0.0.1", port=6379, db=0)生成的对象来操作数据库