Python的八种数据类型
八种数据类型分别是:
number(数字)、string(字符串)、Boolean(布尔值)、None(空值)
list(列表)、tuple(元组)、dict(字典)、set(集合)。
## 可变类型:列表,字典,集合————》 在内存中是以链表的形式存储,每个元素都有独立的地址和地址指向,可以直接修改
## 不可变类型:数字,字符串,元祖
# 数组如何存储?
# 数组底层的存储结构是顺序存储结构,这样的结构有这样一些优点:逻辑上相邻的节点在物理位置上也是相邻的,可以节省空间,并且可以实现随机存取(也称直接访问)。
# 创建一个数组时,会在内存中开辟一块固定长度的区域用于直接存储元素,扩容要考虑这块区域的后面是否有存储其他对象,所以数组在定义好之后就无法扩容了。
# 而且在查询时,是根据索引和元素存储大小去计算地址偏移量的,如果元素类型不一致,所占内存空间不相同,就不能实现随机存储,所以数组不能同时存储不同类型的数据;
#
# 列表如何存储?
# 列表本质是动态的数组,列表存储的是每个元素在内存中的地址(即引用),当列表中空白占位低于1/3时,会在内存中开辟一块更大的空间,
# 并将旧列表中存储的地址复制到新列表中,旧列表则被销毁,这样就实现了扩容。因为列表存储的是元素的引用这个特性,而引用所占的内存空间是相同的,
# 这样便可以同时存放不同类型的数据了。
#
# Python中的列表与数组的区别在于: 数组定义好之后就无法扩容了,而列表在定义好之后可以扩容; 数组只能同时存储一种类型的数据,而列表可以同时存储不同类型的数据。
#
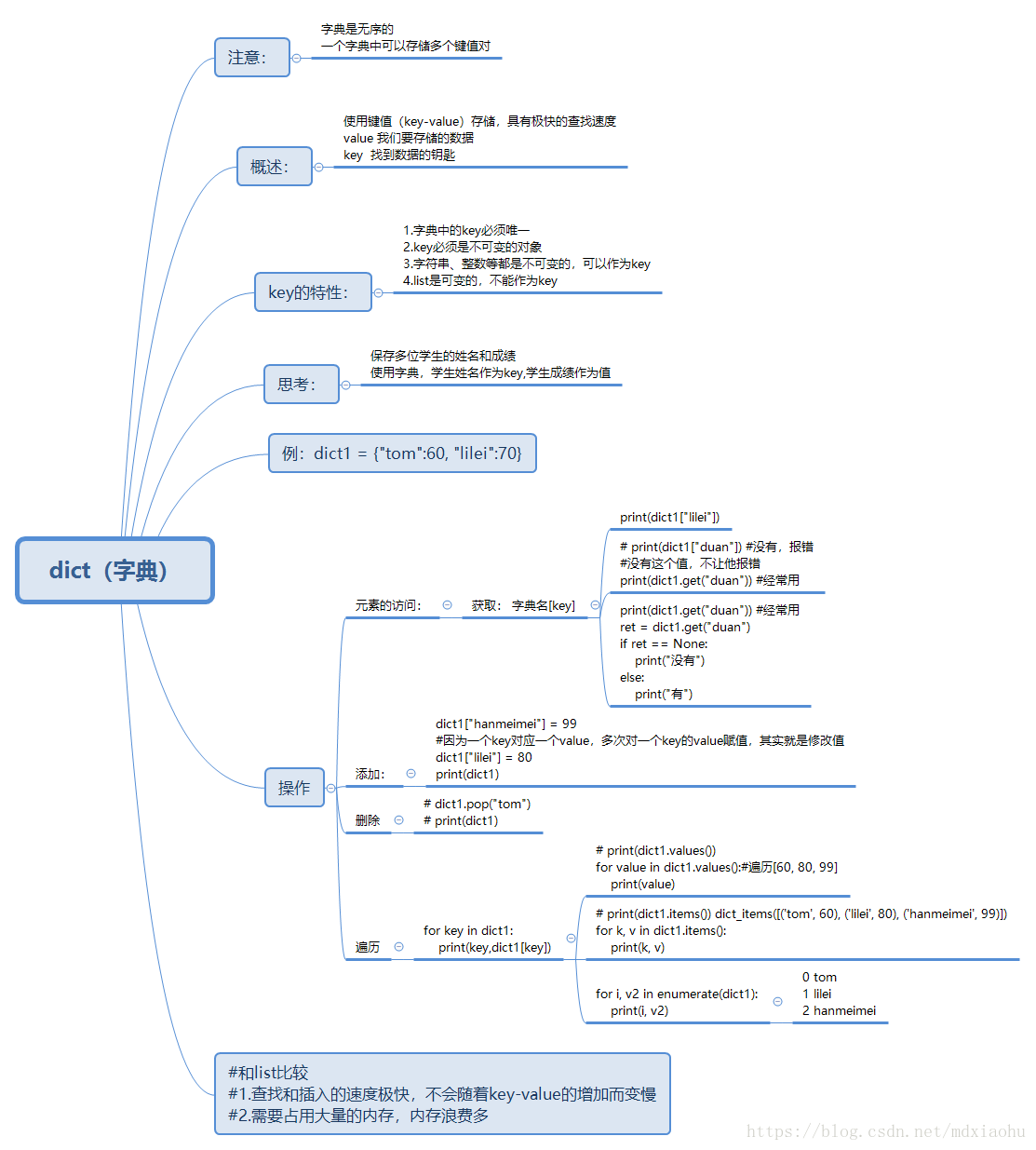
# 字典如何存储?
# Python中的字典底层是通过散列表(哈希表)来实现的, “哈希表是根据关键码值(Key value)而直接进行访问的数据结构。
# 也就是说,它通过把关键码值映射到表中一个位置来访问记录,以加快查找的速度。这个映射函数叫做散列函数,存放记录的数组叫做散列表。”
# 字典本质也是一个数组,但其索引是键经过散列函数处理后得到的散列值,散列函数的目的是使键均匀地分布在散列表中,
# 并且可以在内存中以O(1)的时间复杂度进行寻址,从而实现快速查找和修改。散列表其实是一个稀疏数组(总是有空白元素的数组称为稀疏数组),
# 散列表里的单元通常叫作表元。在字典的散列表当中,**每个键值对都占用一个表元,每个表元都有两个部分,一个是对键的引用,另一个是对值的引用。
# **散列表中散列函数的设计困难在于将数据均匀分布在散列表中,从而尽量减少散列碰撞和冲突。
#
# 字典如何添加和查询?
# **添加:**Python 调用内部的散列函数,将键(Key)作为参数进行转换,得到一个唯一的地址(这也就解释了为什么给相同的键赋值会直接覆盖的原因,
# 因为相同的键转换后的地址是一样的),然后将值(Value)存放到该地址中。 **查询:**使用散列函数将key转换为数组的下标,并定位到数组对应位置获取value。
#
# 字典为什么是无序的?
# 键值的哈希碰撞,hash(key1) == hash(key2)时,向字典里连续添加的这个两个键的顺序是不可以控制的,也是无法做到连续的,后来的键会按算法调整到其它位置。
# 序是不可以控制的,也是无法做到连续的,后来的键会按算法调整到其它位置。 字典空间扩容,当键的数量超过字典默认开的空间时,
# 字典会做空间扩容,扩容后的键顺和创建顺序就会发生变化,不受人为控制。
下面,我将这八种类型的相关知识,做一个梳理。
1.number(数字类型)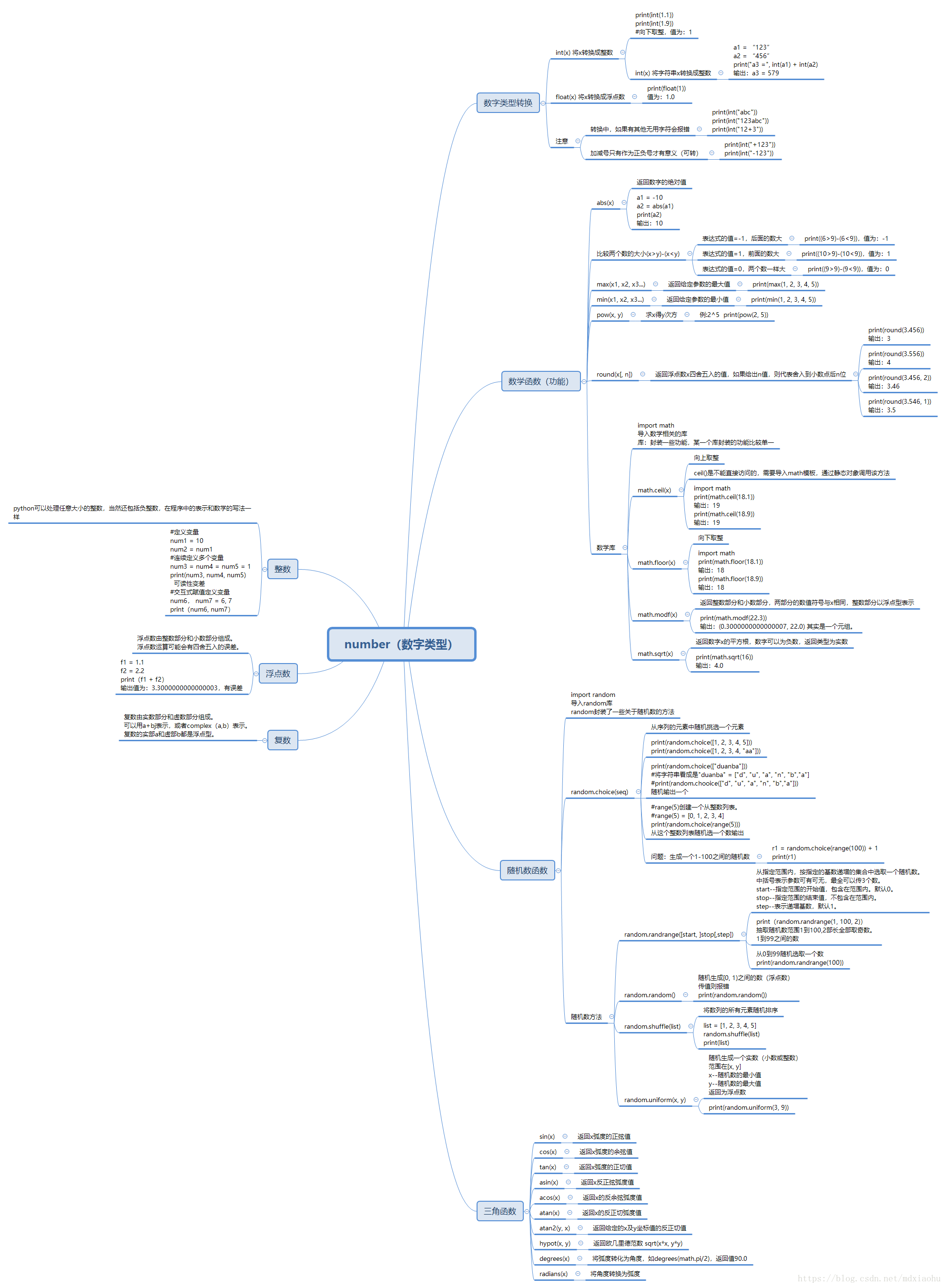
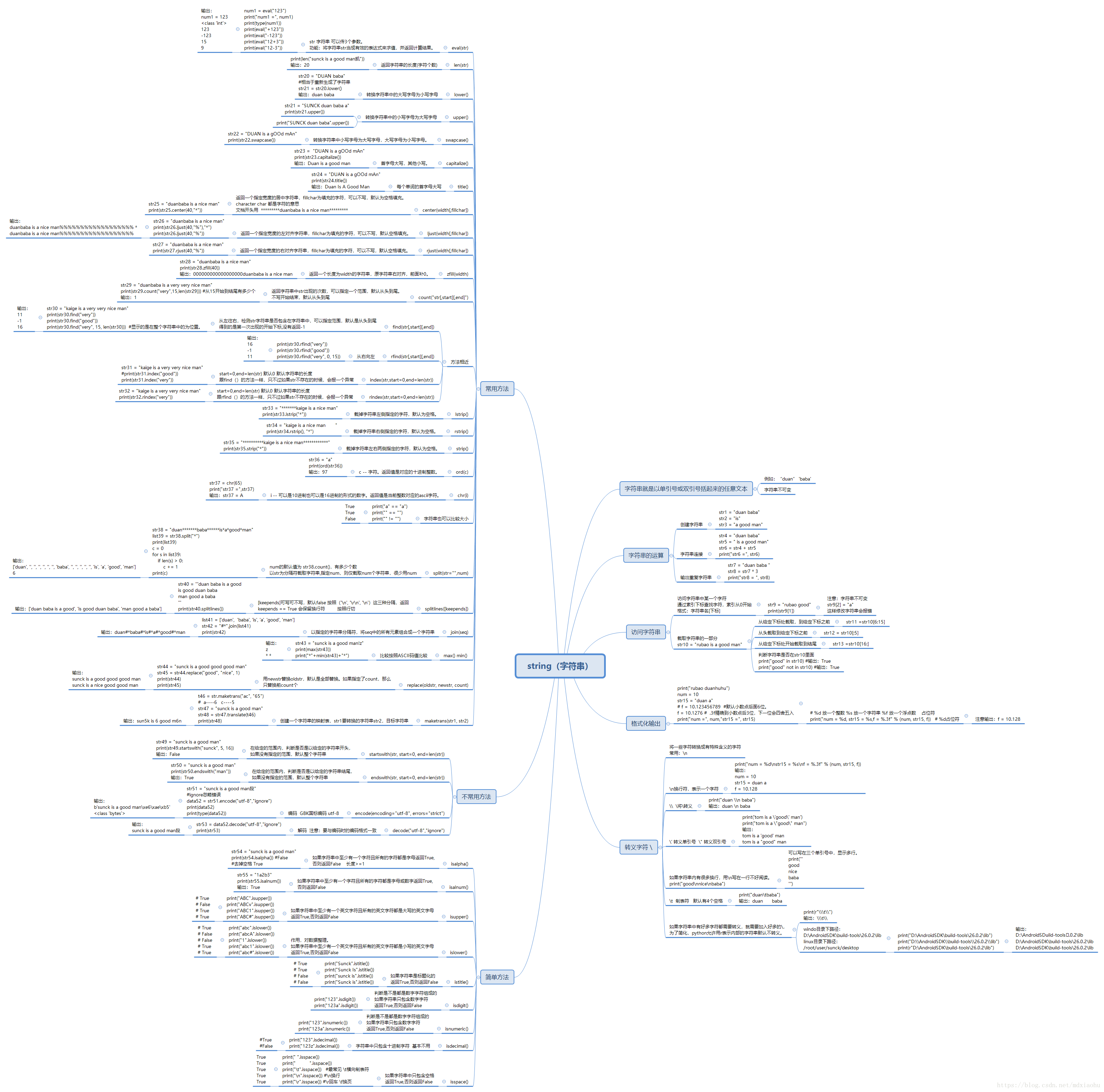
2.string(字符串类型)
3.Boolean(布尔值)与空值

4.list(列表类型)

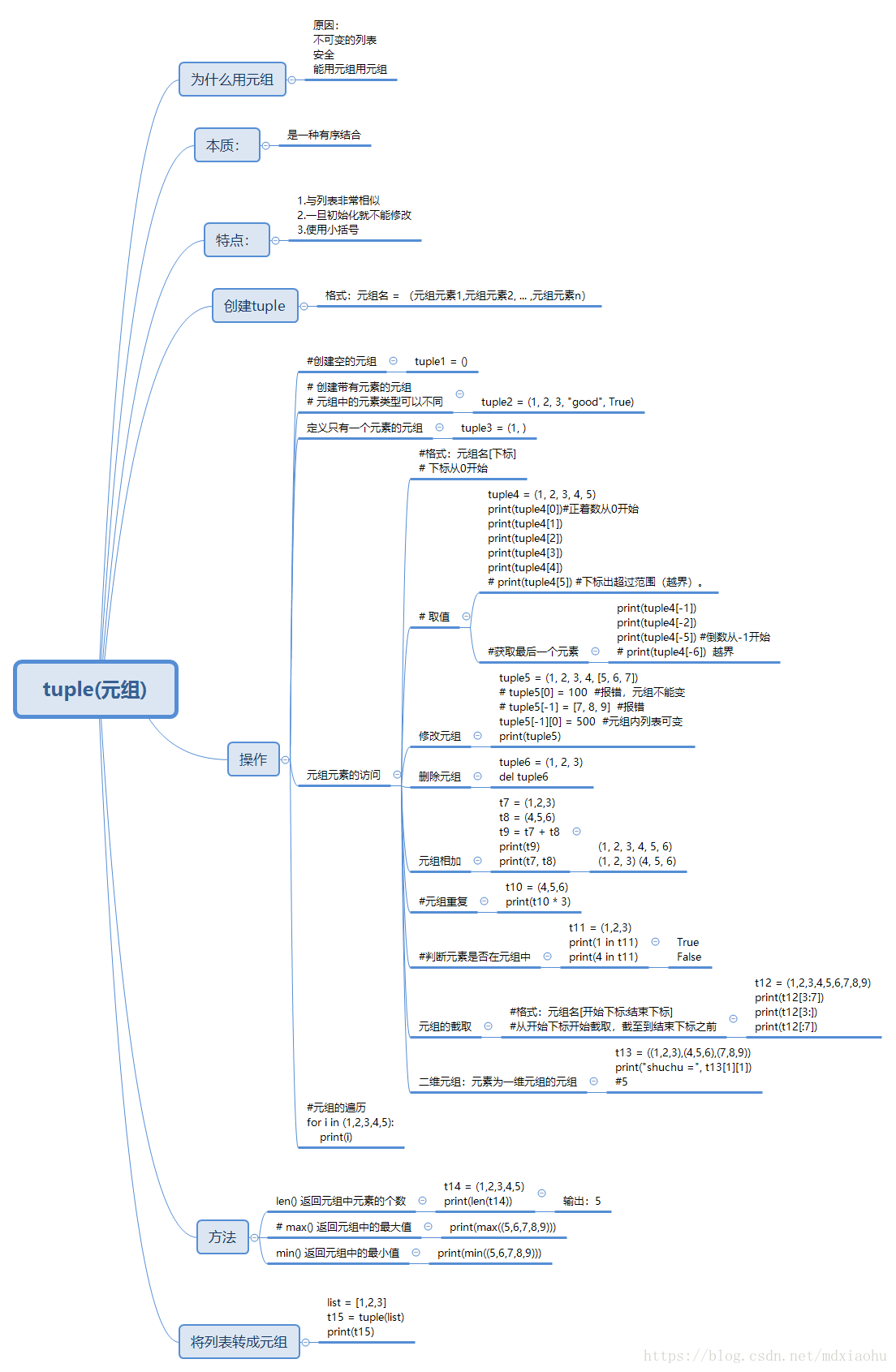
5.tuple(元组类型)
6.dict(字典类型)
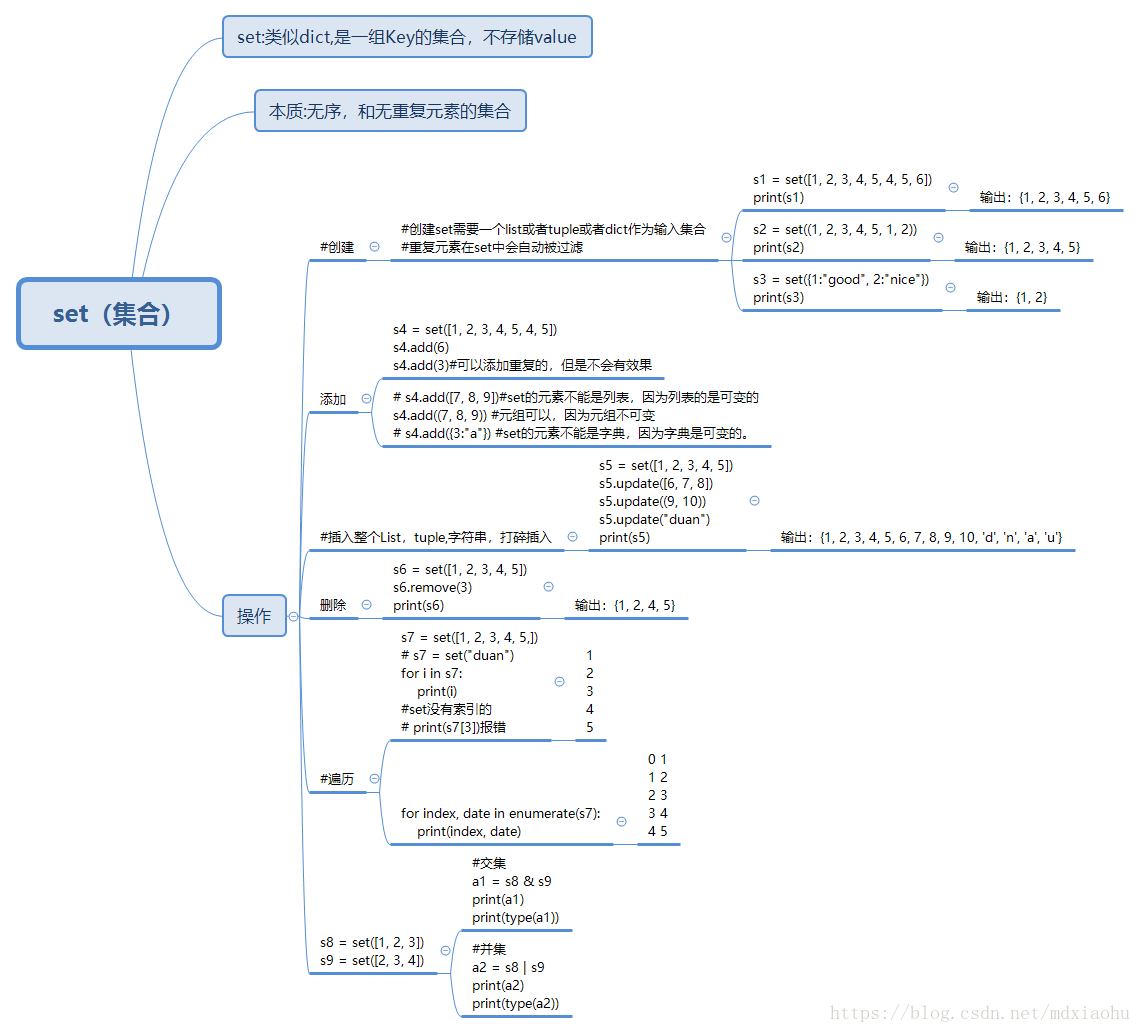
7.set(集合类型)
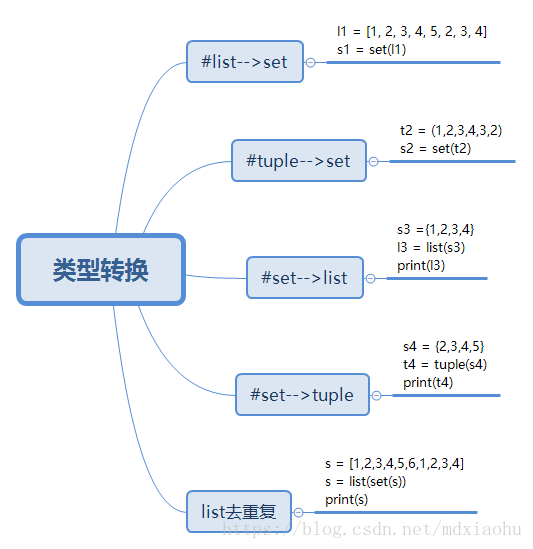
8.数据类型装换