最近刷题的时候遇到一个基础题,就是将16进制数转为8进制数。咋一看极其简单,用二进制做中介即可,简单规划了一下就开始动手了。
问题描述
给定n个十六进制正整数,输出它们对应的八进制数。
输入格式
输入的第一行为一个正整数n (1<=n<=10)。
接下来n行,每行一个由0~9、大写字母A~F组成的字符串,表示要转换的十六进制正整数,每个十六进制数长度不超过100000。
输出格式
输出n行,每行为输入对应的八进制正整数。
题目链接:基础练习 十六进制转八进制
一、二进制作为中介的解法
因为一个十六进制数为4个二进制数组成,而一个八进制数则由三个二进制数组成,所以二进制就成了链接八进制与十六进制的桥梁。又因为输入数据的规模较为庞大,所以我们得申请大量的内存空间。
我们需要申请的内存空间主要分为三部分:存储输入的n个数组,存放中间值的二进制数组,以及存放转换好的八进制的数组。由于题目要求输出必须在全部输入后,所以我们有这样一条流程:
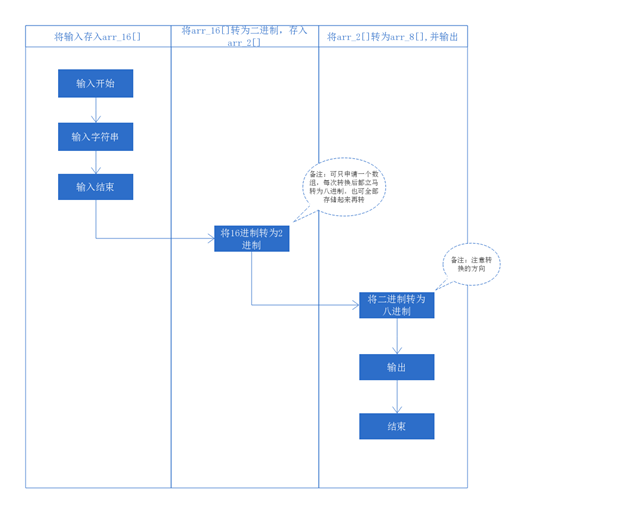
如果只申请一块内存空间用于存放二进制数,那最少也得申请1.2MB左右的空间,再加上进制转化过程中的各种繁琐操作(如必须由后往前读取比特),还没开写,就能想到产出必定是又长又乱,且还满身补丁的奇葩代码(博主照这个流程完成的也的确乱的一蹋糊涂,没通过后就直接重构了,连修改的欲望都没有了。类似的版本百度一下即可得到)。
二、格式化输入输出里的转换说明符
我们知道,在格式化输入输出函数中,请求打印变量的指令取决于变量的类型,即转换说明符指定了如何把数据转换成可显示的形式。除了我们常用的%d %f %c之外,还有一些特定的进制数计数法,如:
%i:有符号十进制数; %u:无符号十进制整数; %o:无符号八进制整数; %x:使用0f的无符号十六进制整数; %X: 使用0F的无符号十六进制整数。
所以,在输入的时候以十六进制输入,输出时以八进制输出,就完成了这个程序的基本框架。
-
/*
-
用printf的格式化进行16进制与8进制的转换
-
*/
-
#include <stdio.h>
-
-
int main (void)
-
{
-
int x = 0;
-
-
scanf("%x",&x);
-
printf("%x: %%d = %d , %%o = %o\n",x,x,x);
-
-
return 0;
-
}
输入十六进制 'ABC'
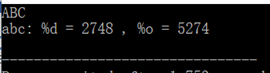
十进制为A*16^2+B*16^1+c*16^0 = 2748,二进制为1010 1011 1100,转换为八进制为5274,正确。
三、sscanf()
有了借助于转换说明符的方法也不行,因为在<=100000的输出条件下,哪怕是long long long ….也得溢出。所以不能直接就把输出scanf()到变量里。我们在这儿借助一个数组(字符串),把所有的输入都存起来,再把输入流stdin导入到scanf()里。这里我们借助了sscanf()函数。
Int sscanf( string str, string fmt, mixed var1, mixed var2 ... );
从一个字符串中读进与指定格式相符的数据
四、对字符串的操作
对于一组长度恐怖的数据进行操作,分解是必须要做的。所以,一次读取多少个数据,又该怎么读,就成了下一个要思考的问题。
在传统的解法,也即将二进制作为中介的解法中,对十六进制的操作是从最后一位开始的,因此对于十六进制'ABCD',把它分成两部分放入scanf()中,与一次读入的结果是不同的。所以对于数组,从低位到高位是可行的方法。
又因为三位十六进制,即12个bit,恰好可以转化为4个八进制,所以一次读取的数量应该为3的倍数。具体的数目也得依据读入该数据的内存大小来定,也即示例代码中'x'的类型。太大会溢出,太小又不高效。
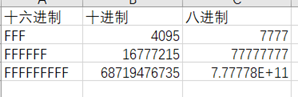
由此可以看出,当一次读入9个F时,对应的十进制数超过了687亿,远远超过了long long 可以表示的范围,所以,一次读取六个字符就成了最好的方案。
五、程序各流程操作的顺序
如果是从后往前读取十六进制字符的话,那么读取到的字符就是反过来的。而输出是要求正序,所以这样的话就要求把处理后的结果保存起来,再输出。但是再次申请内存空间是没必要的,所以我们得做一些处理,让程序正序处理字符串。
整个待处理的十六进制字符串可分为两部分,一部分是一次六个字符被统一读入的部分,另一部分是没有凑够六个的部分。如果字符长度对六取模的值为零,那么正序后者倒叙的结果都一样。所以先对开头的一部分单独处理,再用一个循环来处理后面的字符串,就成了最直接的方法。
-
int x = 0;
-
j = arr_len[i] % 6;
-
if(j != 0)
-
{
-
switch(j)
-
{
-
case 1:
-
sscanf(&arr_16[i][0],"%1x",&x);
-
printf("%o",x);
-
break;
-
case 2:
-
sscanf(&arr_16[i][0],"%2x",&x);
-
printf("%o",x);
-
break;
-
case 3:
-
sscanf(&arr_16[i][0],"%3x",&x);
-
printf("%o",x);
-
break;
-
case 4:
-
sscanf(&arr_16[i][0],"%4x",&x);
-
printf("%o",x);
-
break;
-
case 5:
-
sscanf(&arr_16[i][0],"%5x",&x);
-
printf("%o",x);
-
break;
-
}
-
}
-
-
for(j ;j<arr_len[i];j += 6)
-
//接下来循环处理的部分
变量j是规则部分开始的下标,所以一个循环可以搞定剩下的部分。
-
for(j ;j<arr_len[i];j += 6)
-
{
-
sscanf(&arr_16[i][j],"%6x",&x);
-
printf("%08o",x);
-
}
-
-
printf("\n");
六、特殊十六进制数的处理
上面的模块以及把整个程序交代的差不多了,不过还是有一处细节要交代一下。我们来看一组测试用例:
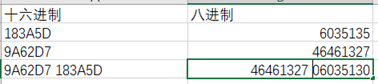
理论上,六位十六进制数可以转化成八个八进制数。但在实际操作中,有时读取到的十六进制数太小,以至于不到八位。如果读取的数是单独的十六进制数那当然没问题,但是如果读取的是一个长十六进制的一部分,那就出错了。所以在输出时得把前导零带上。但是十六进制最开始的几个字符的前导零得去掉,所以要进行一次判断。
-
for(j ;j<arr_len[i];j += 6)
-
{
-
sscanf(&arr_16[i][j],"%6x",&x);
-
if(j != 0)
-
printf("%08o",x);
-
else
-
printf("%8o",x);
-
}
七、效率比较与源码
我在csdn上找了一份该题的另一份源码,这是借助二进制的一个版本。提交后,各情况如下:

新提交的为二进制的版本。可以看到二进制的版本用空间换取了时间,时间消耗极少。而sscanf()版本由于调用了标准库,所以消耗时间较多。
本题源码地址:十六进制转八进制源码