子查询
数据库中的表沿用 上一篇博客 中使用的Employee1.
练习:
1.求所有年龄比张三小的人
select *
from Employee1
where age < (select age
from employee1
where name = '张三');

2.求年龄比平均年龄小的人
select *
from employee1
where age <(select AVG(age)
from employee1);

分组查询
group by 子句
只有跟在group by后面的列才能写到select后面
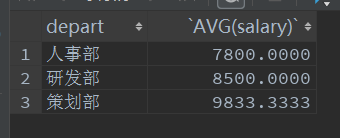
- 求每个部门的平均薪资
select depart,AVG(salary)
from employee1
group by depart;

2.求每个部门相同年龄的人的平均薪资
select depart,age,AVG(salary)
from employee1
group by depart,age;

3.求最大薪资大于10000的部门的平均薪资
having子句 只用来过滤分组情况
一般来说只会跟聚合函数相关的判断
select depart,AVG(salary)
from employee1
group by depart
having MAX(salary) > 10000;
4.求薪资大于等于15000的员工人数>1的部门
select depart,count()
from employee1
where salary >= 10000
group by depart
having count()>1;

5.求年龄小于30 的员工最大薪资大于10000的部门
select depart
from employee1
where age < 30
group by depart
having max(salary) > 10000;
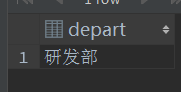
6.求年龄小于30 的员工最大薪资大于10000的部门的全部员工
select *
from Employee
where depart in(select depart
from employee
where age < 30
group by depart
having max(salary) > 10000);
- 先看最后要得到的结果是什么
员工表中差部门 分组 - 哪些是对表中数据本身的限制
在员工表中对员工有限制 那么限制写在where后面 - 哪些条件是对分组的限制
比如所有的聚合函数有限制 写在having后面
练习:
成绩表:

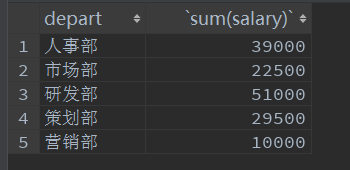
- 查询每个部门的总薪资
select depart,sum(salary)
from employee1
group by depart;
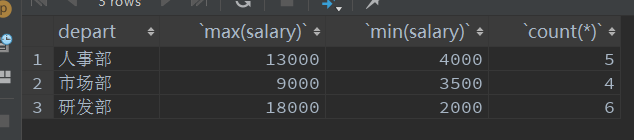
- 员工数超过3人的部门的最高薪资和最低薪资
select depart,max(salary),min(salary),count()
from employee1
group by depart
having count() > 3;
- 工龄超过3年的员工中,薪资最低的所有员工信息
select *
from Employee1
where salary in (select MIN(salary)
from Employee1
where workage > 3);

- 工龄超过3年的员工数大于2的部门
select depart,count()
from Employee1
where workage > 3
group by depart
having count() >2 ;

上周的成绩表
- 查询90分以上的学生的课程名和成绩
select sname,cname,grade
from score
where grade > 90;

- 查询每个学生的成绩在90分以上的各有多少门
select sname,count(grade)
from Score
where grade > 90
group by sname
having COUNT(grade);

- 至少有两门课程在90分以上的学员以及90分以上的课程数
select sname,count()
from Score
where grade > 90
group by sname
having count() >= 2;

- 平均成绩比张三的平均成绩低的学员和其平均分
select sname,AVG(grade)
from Score
group by sname
having AVG(grade) < (
select AVG(grade)
from Score
where sname = '张三'
);

- 查询平均成绩大于90分并且语文课95分以上的学生名和平均成绩
select sname,AVG(grade)
from Score
where sname in ( select sname
from Score
where (cname = '语文' and grade >= 95))
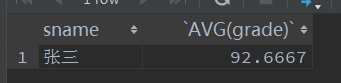
- 查询每个学员的平均分和学生名
select sname,AVG(grade)
from score
group by sname
having AVG(grade);
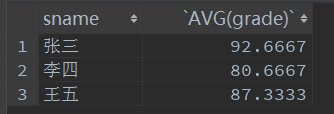
- 查询每门课的最好成绩和平均分
select cname,AVG(grade),MAX(grade)
from score
group by cname
having AVG(grade);
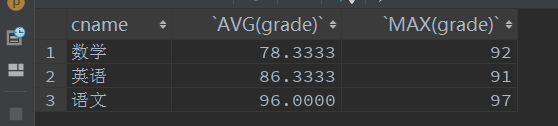
- 查询数学课成绩最好的学员的所有成绩
select *
from score
where sname in (select sname
from score
where grade = (select MAX(grade)
from score
where cname = '数学')
and cname = '数学');
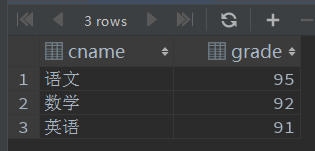
- 查询学员及其总分,按总分降序排列
select sname,sum(grade)
from score
group by sname
having sum(grade)
order by sum(grade) desc;
