1、Sqoop是什么
Sqoop:SQL-to-Hadoop
传统数据库与Hadoop间数据同步工具
利用Mapreduce分布式批处理,加快了数据传输速度,保证了容错性
2、Sqoop1架构
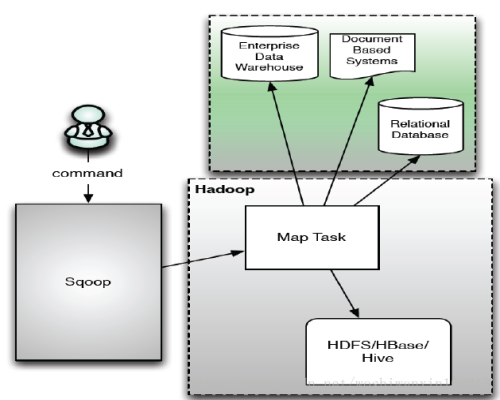
sqoop import原理:
从传统数据库获取元数据信息(schema、table、field、field type),把导入功能转换为只有Map的Mapreduce作业,在mapreduce中有很多map,每个map读一片数据,进而并行的完成数据的拷贝。
sqoop export原理:
获取导出表的schema、meta信息,和Hadoop中的字段match;多个map only作业同时运行,完成hdfs中数据导出到关系型数据库中。
3、sqoop常用用法
1)sqoop import to HDFS:
sqoop import
--connect jdbc:mysql://mysql.example.com/sqoop
--username sqoop
--password sqoop
--table cities
--where "country = 'USA'"
--target-dir /etl/input/cities
--warehouse-dir /etl/input/
--num-mappers 10
--null-string '\N'
--null-non-string '\N'
--incremental append
--check-column id
--last-value 1
说明:
--connnect: 指定JDBC URL
--username/password:mysql数据库的用户名
--table:要读取的数据库表
--where:导入数据的过滤条件
--target-dir:HDFS中导入表的存放目录
--warehouse-dir:指定表存放的父目录,只需要指定一次,下次存放时会在该目录下自动以该表名命名
--num-mappers:并发的map数
--null-string:null值时,HDFS存储为N
--null-non-string:非字符类型的字段为空时,存储为N
--incremental append或lastmodified:自动增量方式
--check-column
--last-value:上一次导入的最后一个值
2) sqoop import to Hbase
bin/sqoop import
--connect "jdbc:mysql://localhost/mytest"
--username "root"
--password "aaa"
--table "student"
--hbase-create-table
--hbase-table student
--column-family info
--hbase-row-key id
3)sqoop export
sqoop export
--connect jdbc:mysql://mysql.example.com/sqoop
--username sqoop
--password sqoop
--table cities
--export-dir cities
--input-fields-terminated-by "�01"
--columns id,name
--batch
-Dsqoop.export.records.per.statement=10 //批量更新,每隔10条提交一次
--staging-table staging_cities //先把数据导入到这个临时表staging_cities,确定所有导入成功后,一次性重命名为正确的表,保证原子性
--update-key id
--update-mode allowinsert
4、Sqoop1存在的问题
Ø基于命令行的操作方式易于出错,且不安全;
Ø数据传输和数据格式是紧耦合的,这使得connector无法支持所有数据格式;
Ø安全密钥是暴露出来的,非常不安全
ØSqoop安装需要root权限
ØConnector必须符合JDBC模型,并使用通用的JDBC词汇
5、常用注意点:
密码保护方法:1)加参数-P,执行时要求终端输入
2)参数--password-file my-sqoop-password,指定密码文件的路径,密码放到文件,文件只读,只有自己可读的
解决数据倾斜:由于数据分布不均匀,导致少数MapJob 比较缓慢,使用--split-by 按照字段进行切分,然后-m 提高并行的。