接下来我将会用一段时间来更新python爬虫
网络爬虫大体可以分为三个步骤。
首先建立请求,爬取所需元素;
其次解析爬取信息,剔除无效数据;
最后将爬取信息进行保存;
今天就先来讲讲第一步,请求库requests
request库主要有七个常用函数,如下所示
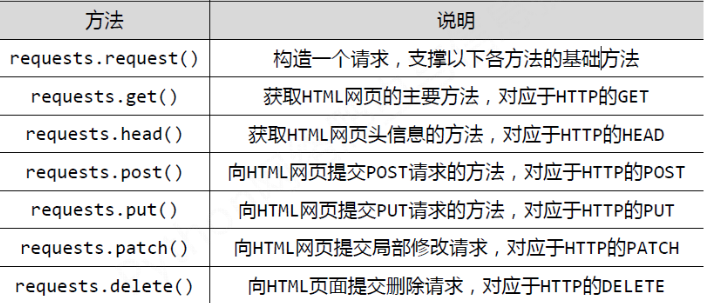
而通过requests创建的数据类型为response
我们以爬取百度网站为例
import requests as r t=r.get("https://www.baidu.com/") print(type(t))
运行结果如下所示
<class 'requests.models.Response'>
[Finished in 1.3s]
那么作为请求对象,具有哪些属性呢?
爬取数据第一步要做的事便是确认是否连接成功
status_code()从功能角度考虑,算的上是一种判断函数,调用将会返还结果是否成功
如果返回结果为200,则代表连接成功,如果返回结果为404,则代表连接失败
import requests as r t=r.get("https://www.baidu.com/") print(type(t)) print(t.status_code)
如图所示返回结果为200,连接成功

那么下一步便是获得网址代码,不过在获得代码之前,还需要做一件事,得到响应内容的编码方式
不同的编码方式将会影响爬取结果
比如说百度网址:https://www.baidu.com/
采用编码方式为ISO-8859-1
获取编码方式为encoding
如下所示
import requests as r t=r.get("https://www.baidu.com/") print(type(t)) print(t.status_code) print(t.encoding)
结果:
<class 'requests.models.Response'>
200
ISO-8859-1
当然有的网页采用 utf8,也有使用gbk,
不同的编码方式会影响我们获得的源码
也可以通过手动更改来改变获得的编码方式
比如:
import requests as r t=r.get("https://www.baidu.com/") print(t.encoding) t.encoding="utf-8" print(t.encoding)
结果
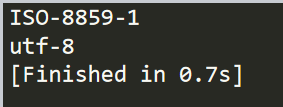
也可以试着备选码方式,apparent_encoding
之后我们就可以获得源代码了,我们需要将源代码以字符串类型输出保存
这就需要用到text
如下所示:
import requests as r t=r.get("https://www.baidu.com/") print(t.text)
结果:

这样我们就获得了对应网站的源码,完成了爬虫的第一步