1、tornado是单线程的,同时WSGI应用又是同步的,如果我们使用Tornado启动WSGI应用,理论上每次只能处理一个请求都是,任何一个请求有阻塞,都会导致tornado的整个IOLOOP阻塞。如下所示,我们同时发出两个GET请求向http://127.0.0.1:5000/
会发现第一个发出的请求会在大约5s之后返回,而另一个请求会在10s左右返回,我们可以判断,这两个请求是顺序执行的。
from tornado.wsgi import WSGIContainer from tornado.httpserver import HTTPServer from tornado.ioloop import IOLoopfrom flask import Flask import time app = Flask(__name__) @app.route('/') def index(): time.sleep(5) return 'OK' if __name__ == '__main__': http_server = HTTPServer(WSGIContainer(app)) http_server.listen(5000) IOLoop.instance().start()
2、我们知道,tornado实现异步运行同步函数,我们只能使用线程来运行,如下所示:
import tornado.web import tornado.ioloop import time import tornado class IndexHandler(tornado.web.RequestHandler): """主路由处理类""" @tornado.gen.coroutine def get(self): """对应http的get请求方式""" loop = tornado.ioloop.IOLoop.instance() yield loop.run_in_executor(None,self.sleep) self.write("Hello You!") def sleep(self): time.sleep(5) self.write('sleep OK') if __name__ == "__main__": app = tornado.web.Application([ (r"/", IndexHandler), ]) app.listen(8000) tornado.ioloop.IOLoop.current().start()
3、对于这种(使用tornado运行Flask的情况)情况,我们如何做呢,查看 WSGIContainer 的代码我们发现:
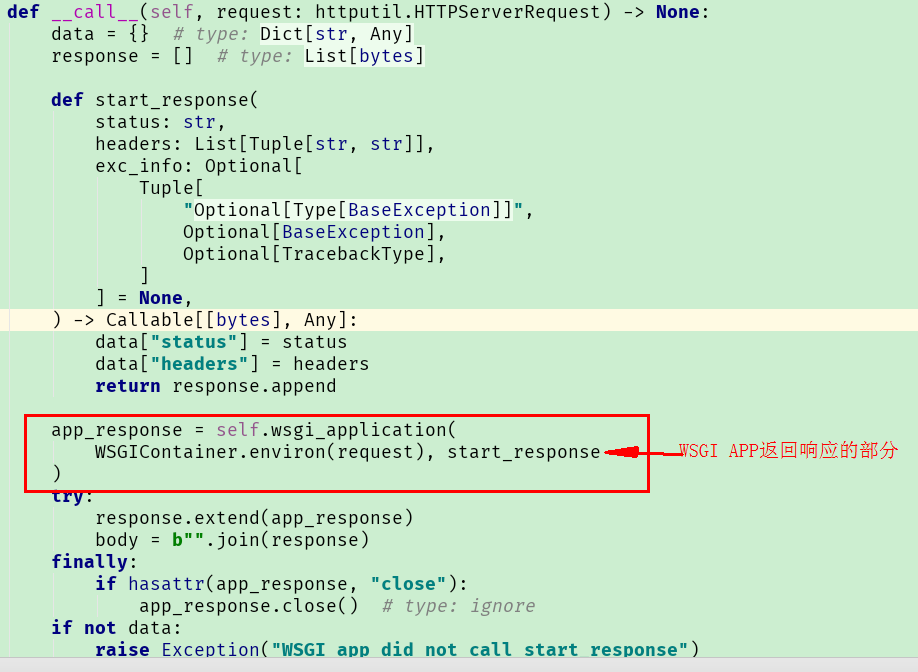
我们只需要重写整个方法,将红圈中的部分变为异步运行即可。
代码如下
loop.run_in_executor 的第一个参数可以为一个ThreadPoolExecutor对象
from flask import Flask import time from tornado.wsgi import WSGIContainer from tornado.httpserver import HTTPServer from tornado.ioloop import IOLoop app = Flask(__name__) @app.route('/') def index(): time.sleep(5) return 'OK' import tornado from tornado import escape from tornado import httputil from typing import List, Tuple, Optional, Callable, Any, Dict from types import TracebackType class WSGIContainer_With_Thread(WSGIContainer): @tornado.gen.coroutine def __call__(self, request): data = {} # type: Dict[str, Any] response = [] # type: List[bytes] def start_response( status: str, headers: List[Tuple[str, str]], exc_info: Optional[ Tuple[ "Optional[Type[BaseException]]", Optional[BaseException], Optional[TracebackType], ] ] = None, ) -> Callable[[bytes], Any]: data["status"] = status data["headers"] = headers return response.append loop = tornado.ioloop.IOLoop.instance() app_response = yield loop.run_in_executor(None, self.wsgi_application, WSGIContainer.environ(request), start_response) # app_response = self.wsgi_application( # WSGIContainer.environ(request), start_response # ) try: response.extend(app_response) body = b"".join(response) finally: if hasattr(app_response, "close"): app_response.close() # type: ignore if not data: raise Exception("WSGI app did not call start_response") status_code_str, reason = data["status"].split(" ", 1) status_code = int(status_code_str) headers = data["headers"] # type: List[Tuple[str, str]] header_set = set(k.lower() for (k, v) in headers) body = escape.utf8(body) if status_code != 304: if "content-length" not in header_set: headers.append(("Content-Length", str(len(body)))) if "content-type" not in header_set: headers.append(("Content-Type", "text/html; charset=UTF-8")) if "server" not in header_set: headers.append(("Server", "TornadoServer/%s" % tornado.version)) start_line = httputil.ResponseStartLine("HTTP/1.1", status_code, reason) header_obj = httputil.HTTPHeaders() for key, value in headers: header_obj.add(key, value) assert request.connection is not None request.connection.write_headers(start_line, header_obj, chunk=body) request.connection.finish() self._log(status_code, request) if __name__ == '__main__': http_server = HTTPServer(WSGIContainer_With_Thread(app)) http_server.listen(5000) IOLoop.instance().start()
注意:
1 、这种方法实际上并没有提高性能,说到底还是使用多线程来运行的,所以推荐如果使用tornado还是和tornado的web框架联合起来写出真正的异步代码,这样才会达到tornado异步IO的高性能目的。