一、问题描述
使用python爬虫爬取某网页的内容时,代码中因为这行代码报错:cont = rep.read().decode()
二、出现原因
你请求获取到的内容不是utf-8编码,如果是utf-8编码可以在decode()中不写,默认utf-8
三、解决方案
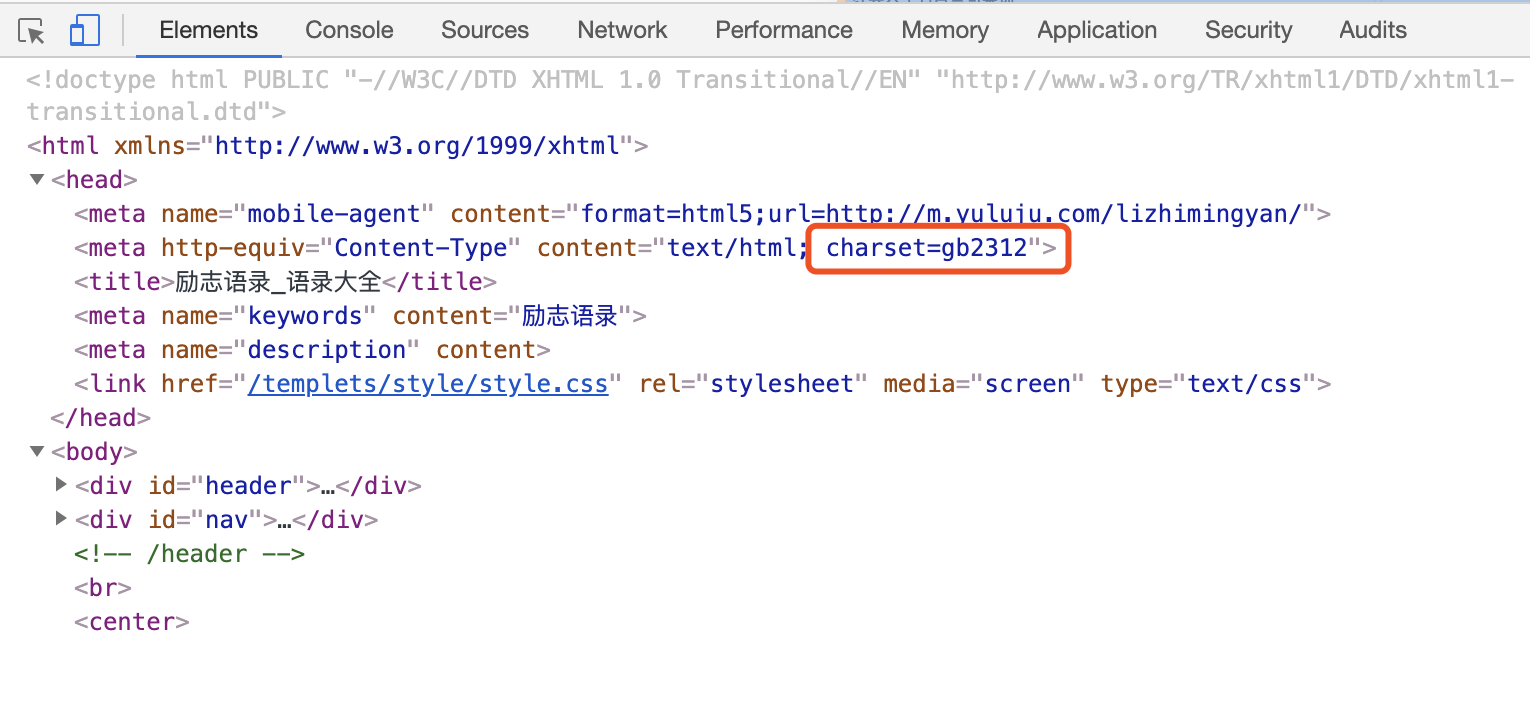
1、首先查看你要爬取网页的内容的编码格式,如下图
2、如果非utf-8编码,就需要在decode()函数中标明,比如我应该写为:cont = rep.read().decode('gb2312'),问题解决。
一、问题描述