首先,在自己写的MR程序中通过org.apache.hadoop.mapreduce.Job来创建Job。配置好之后通过waitForCompletion方法来提交Job并打印MR执行过程的log。Hadoop版本是1.0.0。
public boolean waitForCompletion(boolean verbose
) throws IOException, InterruptedException, ClassNotFoundException {
if (state == JobState.DEFINE) {
submit(); //一
}
if (verbose) {
jobClient.monitorAndPrintJob(conf, info); //二
} else {
info.waitForCompletion(); //三
}
return isSuccessful(); //四
}
我们将waitForCompletion分成四步来讲解。
一、在判断状态state可以提交Job后,执行submit()方法。
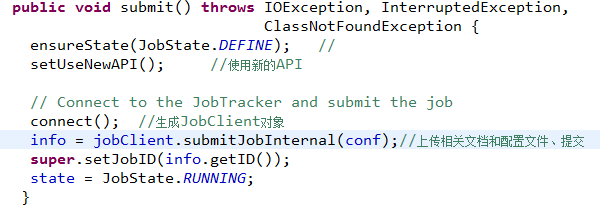
Submit方法首先是确保当前的Job的状态是处于DEFINE,否则不能提交Job。然后启用新的API,即org.apache.hadoop.mapreduce下的Mapper和Reducer,这一点会在后面的MapTask和ReduceTask中觉得是否使用mapreduce包下的新API或者是mapred包下的旧API,这里默认已经使用新的了。
Connect方法会产生一个JobClient实例,用来和JobTracker通信。
jobClient.submitJobInternal(conf)用来:
1、链接JobTracker获取JobID
2、提交作业jar文件
3、提交分片信息splits
4、提交job.xml配置文件
5、提交Job
上述五步中的2~4可以看做一个过程就是向HDFS上传作业资源。由于比较
麻烦,后续会再讲提交过程。
jobClient.submitJobInternal(conf)会返回一个RunningJob—info,这个info一般是org.apache.hadoop.mapred. NetworkedJob的实例,NetworkedJob实现了RunningJob接口,可以用来跟踪作业的执行进度等一些统计信息。
提交给JobTracker后,就将作业状态调整为RUUNING,表示该作业正在被调度运行。
二、jobClient.monitorAndPrintJob(conf, info)会不断的刷新获取job运行的进度信息,并打印。waitForCompletion方法的boolean参数verbose为true表明要打印运行进度,为false就只是等待job运行结束,不打印运行日志。
三、坐等Job运行完毕,不打印日志。
四、返回作业成功与否
大体的流程比较简单,但是实际的运行过程非常复杂,不知道后面的还能不能写出来(好些东西还不清楚)。。。。代码量比较大。以此做笔记,便于和大伙交流并记忆。
有问题欢迎交流留言哈!