大概2016年到2017年的时候,随着人工智能和大4数据的xingqi,Python火起来了,似乎小学也将Python纳入课程。作为毫无目标的小白,自然会随波逐流,也毫无目标的学了一些Python,但是并没有学习网络爬虫。
如果问我爬虫是什么?我只能说,是获取网站信息的程序和脚本。套用百度百科的话。
网络爬虫(又称为网页蜘蛛,网络机器人,在FOAF社区中间,更经常的称为网页追逐者),是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本。另外一些不常使用的名字还有蚂蚁、自动索引、模拟程序或者蠕虫。
所以,还不了解爬虫。只是觉得Python是一个优美的高级语言。但是,后来工作中,一直使用.NET,那时候,虽然工资不高,但工作时间长啊,加上琐事和自己的毅力不够鉴定、毫无明确目标,于是,爬虫被我放弃了,Python被我遗忘了。
最近,在图书馆看书,看到了关于爬虫的书。刘延林的《Python网络爬虫开发——从入门到精通》。(不保证这本书好,只是需要一本入门的书,无论哪一本其实无所谓,关键是行动力)。

如今,我概览的书籍的目录,打算边学边写博文。虽然不知道以后会不会用上,但从毫无目标的小白变成毫无目标的大白,本着拓宽知识面的原则,还是开始学习了,今天算Python爬虫系列的启动。
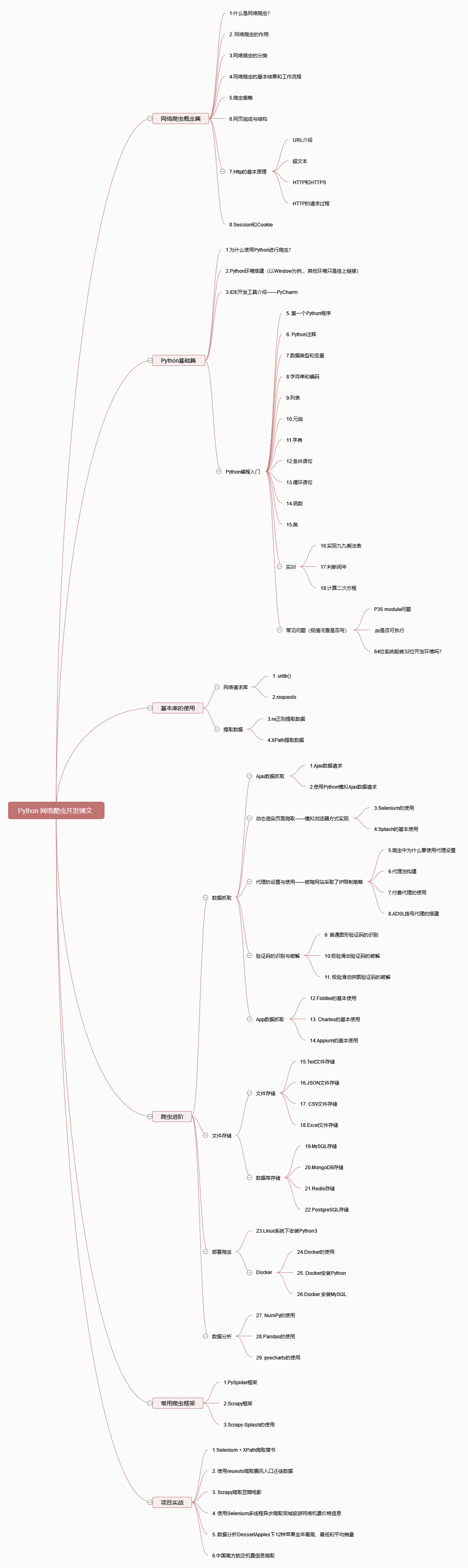
这是我计划的内容。如果粗略的估计的话,一共会有(8+18+4+29+3+6)=68篇。理论上,如果每天写一篇,需要两个月有于的时间。不过,后面的内容只是写出了大概,加上有可能遇到一些问题,需要其他扩展的知识或一些错误,篇幅可能更多。加上生活中有可能有一些其他阻力,自己工作生活中遇到问题也会阻止自己的进度。如果,书籍两个月的时间到了的话。那么,我去买下这本书。反正,计划赶不上变化,但计划还是要有的。
短期的计划需要细化,长期的,只需要一些粗略的方向。
现在,我宣布,Python网络爬虫系列博文项目,在今天正式启动了!
参考网址