Pandas
包概述 :
Pandas是一个Python 的包,提供快速、灵活和富有表现力的数据结构,旨在使"关系或标记数据的使用既简单又直观"。
它的目标是成为用Python进行实际的、真实的数据分析的基础高级模块。
此外,它还有更宏远的目标,即成为超过任何语言的最强大,最灵活的开源数据分析/操作工具。它已朝着这个目标迈进。
Series的基本概念和创建
我们来学习Series,它的基本概念和创建方式. Series可以认为是一个一维数组
Series的 导入方式 :
1 import numpy as np 2 import pandas as pd
Series对象的创建方式,如下:
tes = pd.Series(np.random.rand(5)) print(tes) print(tes.values , type(tes.values))

根据输出结果可以看到 : Series是一个带有标签的一维数组,可以保存任何的数据类型.包括整数,字符串,浮点数,Python对象. 轴标签就是索引, Index
以上是Series的基本概念,下面来了解下Series的几种创建方式:
dic ={'a':1,'b':2,'c':'a'}
tes = pd.Series(dic)
tes.values

当元素里的类型不一致时,tes的类型就是一个Object对象.
arr =np.random.randn(5) tes = pd.Series(arr) print(tes)

既然Index是默认使用整数,那么也可以对它进行修改,修改方法是这样的:
tes = pd.Series(arr,index=list('abcde'),dtype=np.float64) print(tes)

这样就可以对默认索引替换了,可以看到在创建Series时添加了一个index属性.还可以在创建 Series 时添加 dtype属性,设置数组的数据类型.例如 dtype=np.float64
tes = pd.Series(10,index=list('abcde')) print(tes)

Series的索引和切片
索引分别为哪些呢?分为 : 位置下标,标签索引,切片索引和布尔型索引
那什么是位置下标呢?如示例
tes =pd.Series(np.random.rand(5),index=list('abcde')) print(tes[0])

可以看到,和序列差不多,尝试使用tes[-1],却报错了,说明行不通(jupyter),易混淆,不能使用负数取值.Pycharm却可以....

标签索引的使用:取单个值和多个值
print(tes['a'],tes[['a','b']],tes['a'].dtype) #运行时 tes['a'] 已去除

根据结果可以看出,索引的方式和字典差不多,相当于字典,选择多个返回的则是一个Series对象
那么上面的位置下标是否也可以选取多个值.试一下看看
print(tes[[1,4]]) #注意:索引标签index前面已设置

所以不能使用负数,它和列表的取值是有区别的,接下来看切片的使用:
s1 = pd.Series(np.random.rand(5)) s2 = pd.Series(np.random.rand(5),index=list('abcde')) print(s1[1:4]) print(s2['a':'c'])

可以看到标签索引包头尾,所以:标签索引切片是一个闭区间,是字符串索引,包含头和尾
切片的写法和list基本一致, 同样可以这样切片 s2[::2] 从第一个开始隔2取1个值..
布尔型索引,先定义示例数据 :
s = pd.Series(np.arange(10)) s[4]=None #将其中一个值设置为空值 # 对s数组做一个判断,并得到结果 bs1 = s>5 print(bs1)

可以看到 返回的是一个布尔类型的数组
再设置2个判断 用isnull()和notnull(),得到bs2 和 bs3.
bs2 = s.isnull()
bs3 = s.notnull()
数组做了判断之后返回的一个由布尔值组成的新数组,Series,序列.bs2和bbs3是判断返回的布尔型新数组.
s[bs1] # 就拿到了所有为True的值,也就是拿到了所有>5的值 s[bs2] # 拿到了所有为None的值 s[bs3] # 拿到了所有不为None的值 # 输出结果就不一一展示了.这就是布尔型索引 #
Series的基本操作
首先是 数据查看
arr = pd.Series(np.random.rand(50)) print(arr.head()) # head方法默认显示前面5个

既然有查看前面个数的,那也查看尾数几个的, .tail()方法
arr.tail(10) #默认显示最后5个,可以在括号里添加显示个数

重新索引 (reindex) ,也就是对索引进行更改,如何做呢,往下看
tes = pd.Series(np.random.rand(5),index=list('abcde')) s = tes.reindex(['c','d','a','d','ab']) #会根据你的索引,重新排序 print(s)
 如果给个不存在的,如果索引不存在,就引入缺失值NaN,如上代码,已添加不存在索引
如果给个不存在的,如果索引不存在,就引入缺失值NaN,如上代码,已添加不存在索引tes.reindex(['c','d','a','d','ab'],fill_value=0)

reindex 会返回一个新的Series,不修改原数据,另外索引还可以重复.这个是很有用的,如多拷贝一行,重新索引就可以做到.
下一个知识 : 对齐
s1 = pd.Series(np.random.rand(3),index = ['Jack','Mary','Tom']) s2 = pd.Series(np.random.rand(3),index = ['Wang','Jack','Marry']) print(s1) print(s2) print(s1+s2)
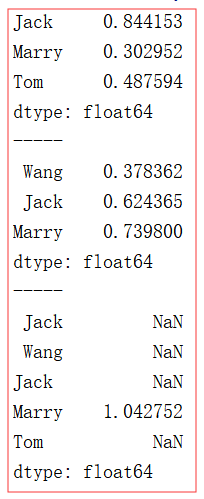
index是自动对齐,顺序不受影响,没找到默认为None,None和任何值计算都为None.所以Tom+None 和Wang+None 都为None.
再一个 删除 功能 :
tes = pd.Series(np.random.rand(5),index=list('abcde'))
如果我们要删除'c', 该怎么做?
tes.drop('c')

drop 返回一个删除了指定数据的新的 Series .
drop 里有个inplace参数 默认为False , drop删除之后会返回新的Series,将inplace设置为True,不会返回新的序列,会修改原数据 将指定数据删除.
添加 元素 :
可以直接添加
tes['f'] = 100

能不能添加多个?
tes[['f','e']]=100 Traceback (most recent call last) : File" C:/Users/Administrator/ PycharmPro jects/Python test/pandas 2 2. py”,line 8,in <module> tes[['f' ,'e' ]]=100 File "C: Users Administrator PycharmProjectsPython test venvlibsite-packages pandascoreseries. py",line 1244, in_ _setitem_ setitem(key,value) File "C:UsersAdministrator PycharmPro jectsPython test venvlibsite-packages pandascoreseries. py”,line 1240, in setitem self._ set_ with (key, value) File "C: UsersAdministrator PycharmPro jectsPython test venvlibsite-packages pandascoreseries.py", line 1301, in_ _set_ with self._ set_ labels(key, value) File "C:UsersAdministrator PycharmPro jectsPython test venvlibsite-packages pandascoreseries. py”,line 1311, in_ set_ 1abels raise ValueError("%s not contained in the index” % str (key [mask])) ValueError: [’ f'] not contained in the index #出现报错,所以这样行不通#
还能通过索引添加 :
arr = pd.Series(np.random.rand(5))
arr[5]=200

那么还有一个添加方法 append() 直接添加一个数组
tes.append(arr)
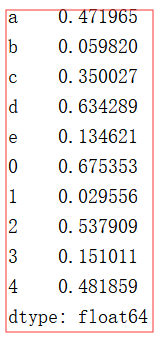
.append 方法会返回一个新的序列Series, 不改变原数据
修改 修改很简单,直接通过赋值的方式 :
arr = pd.Series(np.random.rand(5),index=list('abcde')) arr['a']=100

直接通过索引赋值,类似于列表.
以上就是Series的一些基本操作......
#------------------#