
https://docs.mongodb.com/v4.0/reference/operator/query/expr/
https://www.bilibili.com/video/BV11b41127Lg?p=1
https://www.bilibili.com/video/BV1Rt41117mT?p=1
MongoDB是一个使用C++编写的、开源的、面向文档的NOSQL数据库,也是当前最热门的NoSQL数据库之一。
NoSQL的意思是“不仅仅是SQL”,是目前流行的“非关系型数据库”的统称。常见的NoSQL数据库如:Redis、CouchDB、MongoDB、Hbase、Cassandra等。






# mongoDB只允许一个文档最大为16M,可以使用以下命令查看文档大小 Object.bsonsize({"name":"毛毛"}) # 输出 20 # 即20个字节 var x = {"name":"keke","sex":1} Object.bsonsize(x) # 查看状态 db.stats() db.xinhua.stats()

# 查看所有文档 db.col.find() # 查看集合中第一个文档 db.col.findOne({条件对象}) # 文档替换,这是替换整个文档,不常用 db.col.update(条件,新的文档) db.xuser.update({"userId":"s0","course":"课程0"},{"userId":"s0","course":"课程0","score":99}) # 更新修改器,用来做复杂的更新操作 db.col.update(条件,{"$set":{}}) db.xuser.update({"age":22},{"$set":{"work":"cxy"}},0,1) # 参数0表示upset:找到符合条件的文档就更新,否则会以这个条件来更新文档来创建新文档 # 指定update方法的第三个参数为true,可表示是upset # 参数1表示改条件的文档全量更新 db.xuser.update({"name":"u2"},{"$inc":{"age":5}}) db.xuser.update({"name":"毛毛"},{"$push":{"like":"play"}}) db.xuser.update({"name":"毛毛"},{"$push":{"like":{"$each":["sleep","sport"]}}}) # slice是和$push $each一起使用的 db.xuser.update({"name":"毛毛"},{"$push":{"like":{"$each":["LOL","study"],"$slice":-3}}}) # $是按照索引来取,把毛毛的like数据里的第2个元素改为"AVM" db.xuser.update({"like.2":"sport","name":"毛毛"},{"$set":{"like.$":"AVM"}})

# save如果存在就修改,不存在就新增。insert只能插入不重复_id的文档。

db.col.find function (query, fields, limit, skip, batchSize, options) { ... return cursor; } # 查询年龄大于20岁 db.xuser.find({"age":{"$gt":20}}) # 投影,过滤id字段,只取3条 db.xuser.find({},{"_id":0},3) # 大于20小于27岁,默认是and条件(隐式) db.xuser.find({"age":{"$gt":20,"$lt":27}}) db.xuser.find({"name":{"$ne":"u1"}}) # 名称不为“u1” # 显式指明,数组内关系为and或or db.xuser.find({"$and":[{name:"u3"},{"age":{"$gt":20}}]}) db.xuser.find({"$or":[{name:"u3"},{"age":{"$gt":20}}]}) # $not不能最为顶级操作符,且其后只能跟document或正则 错误写法:db.xuser.find({"$not":{"name":"u1"}}) 错误写法:db.xuser.find({"name":{"$not":"u1"}}) 跟正则:db.xuser.find({"name":{"$not":/u1/}}) # 名称不为u1 跟document:db.xuser.find({"age":{"$not":{"$gt":25}}}) # 年龄不大于25岁 # $mod拿age和100求余,余数为2的文档 db.xuser.find({"age":{"$mod":[20,2]}}) # $in 年龄不在22、23的文档 db.xuser.find({"age":{"$not":{"$in":[22,23]}}}) db.xuser.find({"age":{"$nin":[22,23]}}) # $all 数组内必须包含LOL和study的文档 db.xuser.find({"like":{"$all":["LOL","study"]}}) # $exists 查询必须存在like键的文档 db.xuser.find({"like":{"$exists":1}}) # null 不仅能查不存在键work的文档,还能查键work为null的文档 db.xuser.find({"work":null}) db.xuser.find({"work":{"$in":[null],"$exists":1}})

# 正则查询 db.xuser.find({"name":/^u/}) # 单个元素匹配 db.xuser.find({"name":"u1"}) # 多个元素匹配 db.xuser.find({"like":{$all:["LOL","study"]}}) # 可以使用索引指定查询数组特定位置,{"key.索引号":"value"} db.xuser.find({"like.0":"AV"})

# 如果内嵌是个数组,则x.y中y就是索引,如果内嵌是个文档,则x.y中y就是key

# 使用count()函数是统计find({})的结果,不受其他过滤条件影响 >db.xuser.find().limit(3).count() 4 >db.xuser.find().limit(3).count(true) 3

MongoDB的聚合框架,主要用来对集合中的文档进行变换和组合,从而对数据进行分析以加以利用。
聚合框架的基本思路是:采用多个构件来创建一个管道,用于对一连串的文档进行处理。这些构建包括:筛选(filtering)、投影(projecting)、分组(grouping)、排序(sorting)、限制(limiting)和跳过(skipping)。
db.集合.aggregate(构件1,构件2...)
# 注意由于聚合的结果要返回客户端,因此聚合结果必须限制在16M以内,这是MongoDB支持
# 最大响应消息的大小
# 插入预备数据: for(var i=0;i<100;i++) { for(var j=0;j<4;j++) { db.xuser.insert({"userId":"s"+i,"course":"课程"+j,"score":Math.random()*100}) } }
# 1、找到所有考了80分以上的学生,不区分课程 # {"$match":{"score":{"$gte":80}}} db.getCollection('xuser').aggregate([{"$match":{"score":{"$gte":80}}}]) # 2、将每个学生的名字投影出来,注意顺序,如果$project放在前面查询 # 结果为空,因为这是一个管道,按照顺序过滤 # {"$project":{"userId":1}} db.getCollection('xuser').aggregate([ {"$match":{"score":{"$gte":80}}}, {"$project":{"userId":1}} ]) # 3、对学生名字进行排序,某个学生的名字出现一次,就给他加1,注意_id是必须的,其value就是你要分组的字段 # {"$group":{"_id":"$userId","count":{"$sum":1}}} db.getCollection('xuser').aggregate([ {"$match":{"score":{"$gte":80}}}, {"$project":{"userId":1}}, {"$group":{"_id":"$userId","count":{"$sum":1}}} ]) # 4、对结果集分数的降序进行排列 # {"$sort":{"count":-1}} db.getCollection('xuser').aggregate([ {"$match":{"score":{"$gte":80}}}, {"$project":{"userId":1}}, {"$group":{"_id":"$userId","count":{"$sum":1}}}, {"$sort":{"count":-1}} ]) # 5、限制limit # ${limit:5} db.getCollection('xuser').aggregate([ {"$match":{"score":{"$gte":80}}}, {"$project":{"userId":1}}, {"$group":{"_id":"$userId","count":{"$sum":1}}}, {"$sort":{"count":-1}}, {"$limit":5} ])
每个操作符接受一系列的文档,对这些文档做相应的处理,然后把转换后的文档作为结果传递给下一个操作符。最后一个操作符会将结果返回。
不同的管道操作符,可以按照任意顺序,任意个数组合在一起使用。如上$project、$sort、$group等,注意:不同的顺序可能会直接影响最终的结果。
用于对文档集合进行筛选,里面可以使用所有常规的查询操作符。通常会放置在管道最前面的位置,理由如下:
若project放在$match之前,则match里的过滤条件必须包含在project里,否则查不到任何内容。
用来从文档中提取字段,可以指定包含和排除字段,也可以重命名字段,不写默认取所有。比如要将studentId改为sid,如下:
db.sources.aggreate([{"$project":{"sid":"$studentId"}}]})
$add:[expr1[,expr2,..exprn]]
$subtract:[expr1,expr2]
$multiply:[expr1[,expr2,...exprn]]
$divice:[expr1,expr2]
$mod:[expr1,expr2]
# 例如给成绩集体加20分
{"$project":{"newScore":{"$add":["$score":20]}}}
# 注意:这些只能操作日期型的字段,不能操作数据,用法案例
{"$project":{"opeDay":{"$dayOfMonth":"$recoredTime"}}} # 从redoredTime字段取出月重命名为opeDay
$substr:[expr,开始位置,要取的字节个数]
$concat:[expr1[,expr2,...exprn]]
$toLower:expr
$toUpper:expr
# 例如:{"$project":{"sid":{"$concat":["$studentId","cc"]}}}}
$cmp:[expr1,expr2] #比较两个表达式,0表示相等,正数前面的大,负数后面的大
$strcasecmp:[string1,string2] # 比较两个字符串,区分大小写,只对由罗马字符[I,II,III,IV,VI]组成的字符串有效
$eq $ne $gt $gte $lt $lte:[expr1,expr2]
$cond:[booleanExpr,trueExpr,falseExpr]:#三目运算符。如果boolean表达式为true,返回true表达式,否则返回false表达式。
$ifNull:[expr,otherExpr]:#如果expr为null,返回otherExpr,否则返回expr
# 例如
db.scores.aggregate([{"$project":{"newScore":["$cmp":["$studentId","sss"]]}}])
用来将文档依据特定字段的不同值进行分组。选定了分组字段过后,就可以把这些字段传递给$group函数的"_id"字段了。例如:
db.score.aggregate({"$group":{"_id":"$studentId"}}) 或者
db.score.aggregate({"$group":{"_id":{"sid":"studentId","score":"$score"}}})
$sum:value #对于每个文档,将value与计算结果相加
$avg:value #返回每个分组的平均值
$max:expr #返回分组内的最大值
$min:expr #返回分组内的最小值
$first:expr #返回分组的第一个值,忽略其他值,一般只有排序后,明确知道数据顺序的时候,此操作才有意义
$last:expr #与上面一个相反,返回分组的最后一个值
$addToSet:expr # 如果当前数组中不包括expr,那就将它加入到数组中
$push:expr # 把expr加入到数组中
# 案例
db.getCollection('xuser').aggregate([{"$group":{"_id":"$userId","avg":{"$avg":"$score"}}}])
db.getCollection('xuser').insert({"userId":"小米","like":["apple","play","eat"]})
db.getCollection('xuser').aggregate([{"$unwind":"$like"}])
# 返回结果
/* 1 */
{
"_id" : ObjectId("5ef98dc0388090bf5b20fc4a"),
"userId" : "小米",
"like" : "apple"
}
/* 2 */
{
"_id" : ObjectId("5ef98dc0388090bf5b20fc4a"),
"userId" : "小米",
"like" : "play"
}
/* 3 */
{
"_id" : ObjectId("5ef98dc0388090bf5b20fc4a"),
"userId" : "小米",
"like" : "eat"
}
可以根据任何字段进行排序,与普通查询中的语法相同。如果要对大量的文档进行排序,强烈建议在管道的第一阶段进行排序,这时可以使用索引。
db.col.find().count()
db.runCommand({"distinct":"users","key":"userId"})
# 语法 db.collection.mapReduce( function() {emit(key,value);}, //map 函数 function(key,values) {return reduceFunction}, //reduce 函数 { out: collection, query: document, sort: document, limit: number } ) # 执行结果参数 result:储存结果的collection的名字,这是个临时集合,MapReduce的连接关闭后自动就被删除了。 timeMillis:执行花费的时间,毫秒为单位 input:满足条件被发送到map函数的文档个数 emit:在map函数中emit被调用的次数,也就是所有集合中的数据总量 ouput:结果集合中的文档个数(count对调试非常有帮助),out: { inline: 1 }设置了 {inline:1} 将不会创建集合,整个 Map/Reduce 的操作将会在内存中进行。注意,这个选项只有在结果集单个文档大小在16MB限制范围内时才有效。 ok:是否成功,成功为1 err:如果失败,这里可以有失败原因,不过从经验上来看,原因比较模糊,作用不大

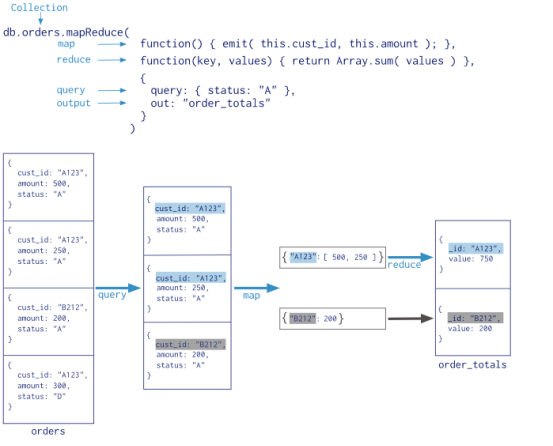
在MongoDB的聚合框架中,还可以使用MapReduce,它非常强大灵活,但具有一定的复杂性,专门用于实现一些复杂的聚合功能。
MongoDB中的MapReduce使用JavaScript来作为查询语言,因此能表达任意的逻辑,但是它运行的非常慢,不应该用在实时的数据分析中。
# 找出集合中所有的键值,并统计每个键出现的次数。 # 1、Map函数必须使用emit函数来返回要处理的值,示例如下: var map = function() { # map函数会对每一个文档进行处理,这里的this即指当前文档 for(var key in this) { # emit里的这个key和下面reduce参数里的key是对应的, # emits存储的是所有的emit(key,value)里的当前key对应的value数组 emit(key,{count:1}); } } # 2、reduce函数需要处理Map阶段或者是前一个reduce的数据,因此reduce返回的 # 文档必须要能作为recude的第二个参数的一个元素,示例如下: var reduce = function(key,emits) { var total = 0; for(var i in emits) { total += emits[i].count; } return {"count":total} } # 连贯起来,在shell执行如下: db.xuser.mapReduce( function() { for(var key in this) { emit(key,1); } }, function(key, values) {return Array.sum(values)}, { out:"post_total" } ) # 执行结果如下: { "result" : "post_total", "timeMillis" : 20.0, "counts" : { "input" : 401, "emit" : 401, "reduce" : 100, "output" : 101 }... # input:有401个符合条件的查询,emit:在map函数中生成了5个键值对,最后使用 # reduce函数将相同的键值分为101组 db.post_total.find({}).limit(2) # 执行结果: /* 1 */ { "_id" : "s0", "value" : 4.0 } /* 2 */ { "_id" : "s1", "value" : 4.0 }
finalize:function(key,value){return value} # 可以将reduce的结果发送到finalize,这是整个处理的最后一步
keeptemp:boolean # 是否在连接关闭的时候,保存临时结果集合
query:document # 在发送给map前对文档进行过滤
sort:document #在发送给map前对文档进行排序
limit:integer #在发送map函数的文档数量上限
scope:document #可以在javascript中使用的变量
verbose:boolean #是否记录详细的服务器日志
# 案例
db.xuser.mapReduce(
function() { emit(this.userId,1);},
function(key, values) {return Array.sum(values)},
{
out:"post_total" ,
finalize:function(key,value){
return {'mk':key,'mv':value}
}
}
)
db.post_total.find({}).limit(1)
# 返回结果:
/* 1 */
{
"_id" : "s0",
"value" : {
"mk" : "s0",
"mv" : 4.0
}
}
用来对集合进行分组,分组过后,再对每一个分组内的文档进行聚合
将文档插入到MongoDB的时候,文档是按照插入的顺序,依次在磁盘上相邻保存。因此,一个文档变大了,原来的位置要是放不下这个文档了,就需要把这个文档移动到集合的另外一个位置,通常是最后,能放下这个文档的地方。

MongoDB移动文档的时候,会自动修改集合的填充因子(padding factor),填充因子是为新文档预留的增长空间,不能手动设定填充因子。
1、填充因子开始可能是1,也就是为每个文档分配精确的空间,不预留增长空间。
移动文档的时候,MongoDB需要将文档原先占用的空间释放掉,然后将文档写入新的空间,相对费时,尤其是文档比较大,又频繁需要移动的话,会严重影响性能。


# 查看索引 >db.getCollection('xuser').getIndexes() /* 1 */ [ { "v" : 1, "key" : { "_id" : 1 }, "name" : "_id_", "ns" : "xinhua.xuser" } ] >db.getCollection('xuser').find({}).explain() # https://docs.mongodb.com/v4.0/reference/explain-results/
# 创建索引,1表示升序,-1表示降序 >db.xinhua.createIndex({"name":1}) # 缺省索引名称,mongo会自动生成一个名称 /* 1 */ { "createdCollectionAutomatically" : false, "numIndexesBefore" : 1, "numIndexesAfter" : 2, "ok" : 1.0 } >db.getCollection('xuser').getIndexes() [ { "v" : 1, "key" : { "_id" : 1 }, "name" : "_id_", "ns" : "xinhua.xuser" }, { "v" : 1, "key" : { "name" : 1.0 }, "name" : "name_1", "ns" : "xinhua.xuser" } ] >db.xinhua.createIndex({"age":1},{"name":"myAgeIndex"}) >db.getCollection('xuser').getIndexes() [ { "v" : 1, "key" : { "_id" : 1 }, "name" : "_id_", "ns" : "xinhua.xinhua" }, { "v" : 1, "key" : { "GUNS_XINHUA_VERSION" : 1.0 }, "name" : "GUNS_XINHUA_VERSION_1", "ns" : "xinhua.xinhua" }, { "v" : 1, "key" : { "age" : 1.0 }, "name" : "myAgeIndex", "ns" : "xinhua.xinhua" } ] # 删除索引 db.xinhua.dropIndex({"name":1}) # 按照创建的字段删除索引 db.xuser.dropIndex("myAgeIndex") # 如果自己创建了索引名称,可以使用名称删

MongoDB 固定集合(Capped Collections)是性能出色且有着固定大小的集合,对于大小固定,我们可以想象其就像一个环形队列,当集合空间用完后,再插入的元素就会覆盖最初始的头部的元素!一般用于限制:最新博文(只显示前10篇),最新歌曲,等设定大小,高效利用。
# 创建时需指定capped和size >db.createCollection("cappedLogCollection",{capped:true,size:10000}) # 还可以指定文档个数,加上max:1000属性: >db.createCollection("cappedLogCollection",{capped:true,size:10000,max:1000})

GridFS时是MongoDB用来存储大型二进制文件的一种存储机制。特别适合用在存储一些不常改变,但是经常需要连续访问的大文件的情况。GridFS没有专门的大型分布式文件系统那么强大,如果你不是那么需要大型分布式文件系统使用GridFS还是可以的。
GridFS用于存储和恢复那些超过16M(BSON文件限制)的文件(如:图片、音频、视频等)。它会将大文件对象分割成多个小的chunk(文件片段),一般为256k/个,每个chunk将作为MongoDB的一个文档被存储在chunks集合中。



