Flink架构
Flink是一个分布式系统,为了执行流式应用,需要对计算资源进行有效的分配和管理。它集成了所有常见的集群资源管理器,如Hadoop YARN、Apache Mesos和Kubernetes,但也可以设置为独立集群甚至作为库运行。
本节包含对Flink架构的概述,并描述其主要组件如何交互执行应用程序并从故障中恢复。
Flink集群的解剖
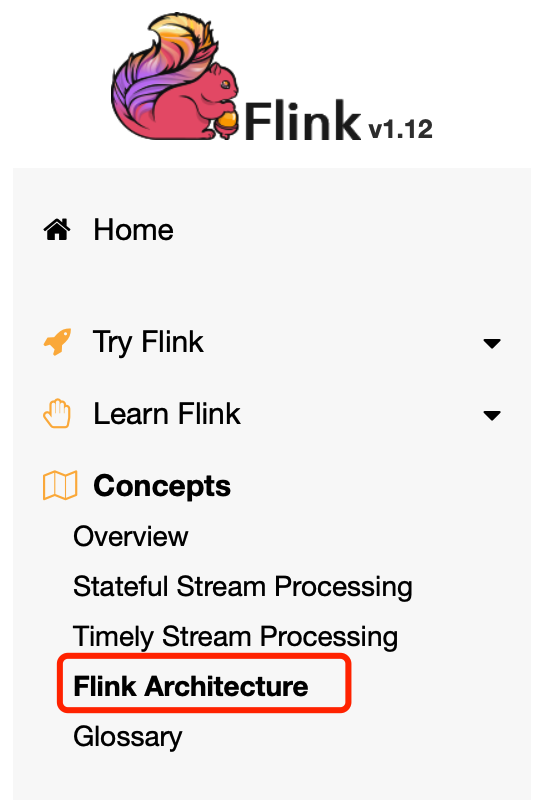
Flink运行时由两种类型的进程组成:一个JobManager和一个或多个TaskManagers。
客户端不是运行时和程序执行的一部分,而是用来准备并向JobManager发送数据流。之后,客户端可以断开连接(分离模式),或者保持连接以接收进度报告(附加模式)。客户端可以作为触发执行的Java/Scala程序的一部分运行,也可以在命令行进程中运行./bin/flink run ....。
JobManager和TaskManagers可以以各种方式启动:直接在机器上作为一个独立的集群,在容器中,或由YARN或Mesos等资源框架管理。TaskManagers连接到JobManagers,宣布自己可用,并被分配工作。
JobManager
JobManager有一些与协调Flink应用的分布式执行有关的职责:它决定何时安排下一个任务(或一组任务),对已完成的任务或执行失败作出反应,协调检查点,并协调失败时的恢复等。这个过程由三个不同的组件组成。
ResourceManager
ResourceManager负责Flink集群中的资源去/分配和供应--它管理任务槽,任务槽是Flink集群中资源调度的单位(见TaskManagers)。Flink针对不同的环境和资源提供者(如YARN、Mesos、Kubernetes和独立部署)实现了多个ResourceManagers。在独立设置中,ResourceManager只能分配可用的TaskManagers的槽位,而不能自行启动新的TaskManagers。
Dispatcher
Dispatcher提供了一个REST接口来提交Flink应用执行,并为每个提交的作业启动一个新的JobMaster。它还运行Flink WebUI来提供作业执行的信息。
JobMaster
一个JobMaster负责管理单个JobGraph的执行。在Flink集群中可以同时运行多个作业,每个作业都有自己的JobMaster。
总是至少有一个JobManager。一个高可用性设置可能有多个JobManager,其中一个总是领导者,其他的是备用的(见高可用性(HA))。
TaskManagers
任务管理器(TaskManagers)(也叫worker)执行数据流的任务,并缓冲和交换数据流。
必须始终有至少一个TaskManager。TaskManager中资源调度的最小单位是一个任务槽。一个任务管理器中任务槽的数量表示并发处理任务的数量。请注意,一个任务槽中可以执行多个操作者(参见任务和操作者链)。
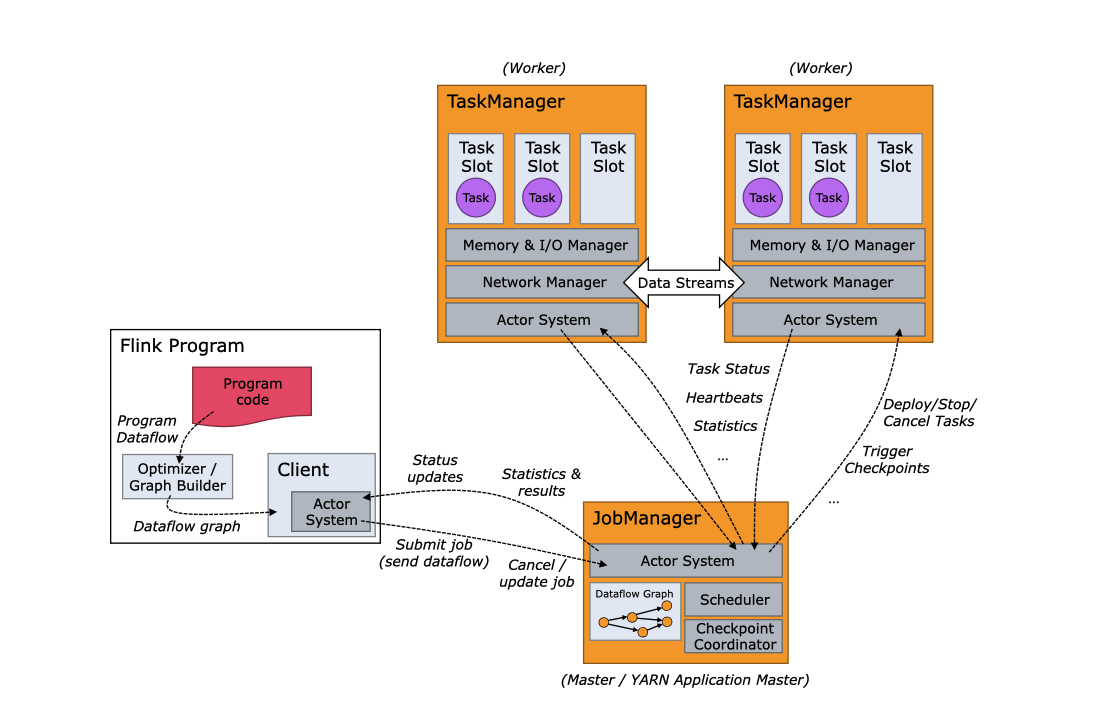
任务和操作链
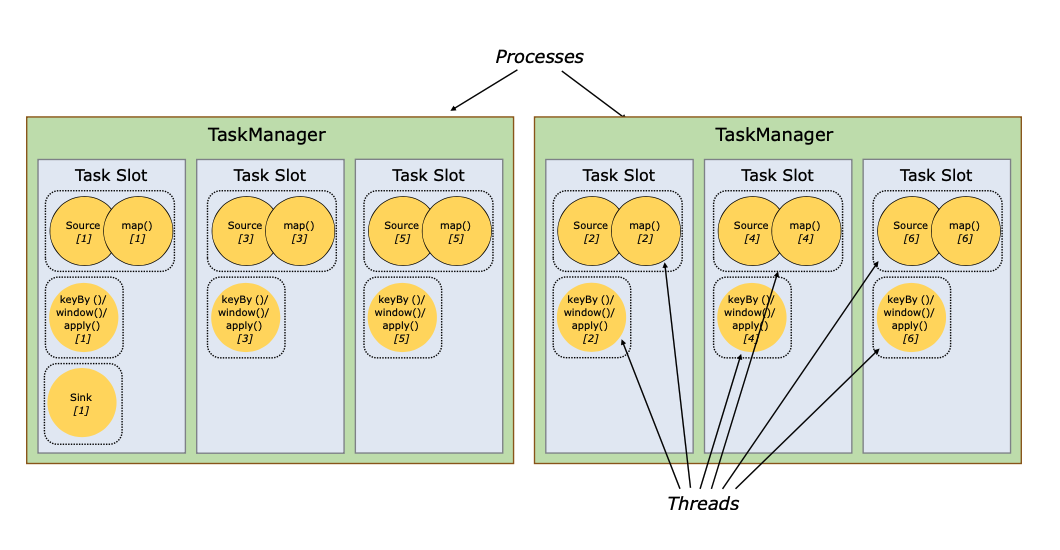
对于分布式执行,Flink将操作者的子任务链成任务。每个任务由一个线程执行。将运算符一起链入任务是一种有用的优化:它减少了线程到线程的交接和缓冲的开销,增加了整体的吞吐量,同时降低了延迟。链锁行为可以配置,详情请看链锁文档。
下图中的示例数据流是以五个子任务,也就是五个并行线程来执行的。
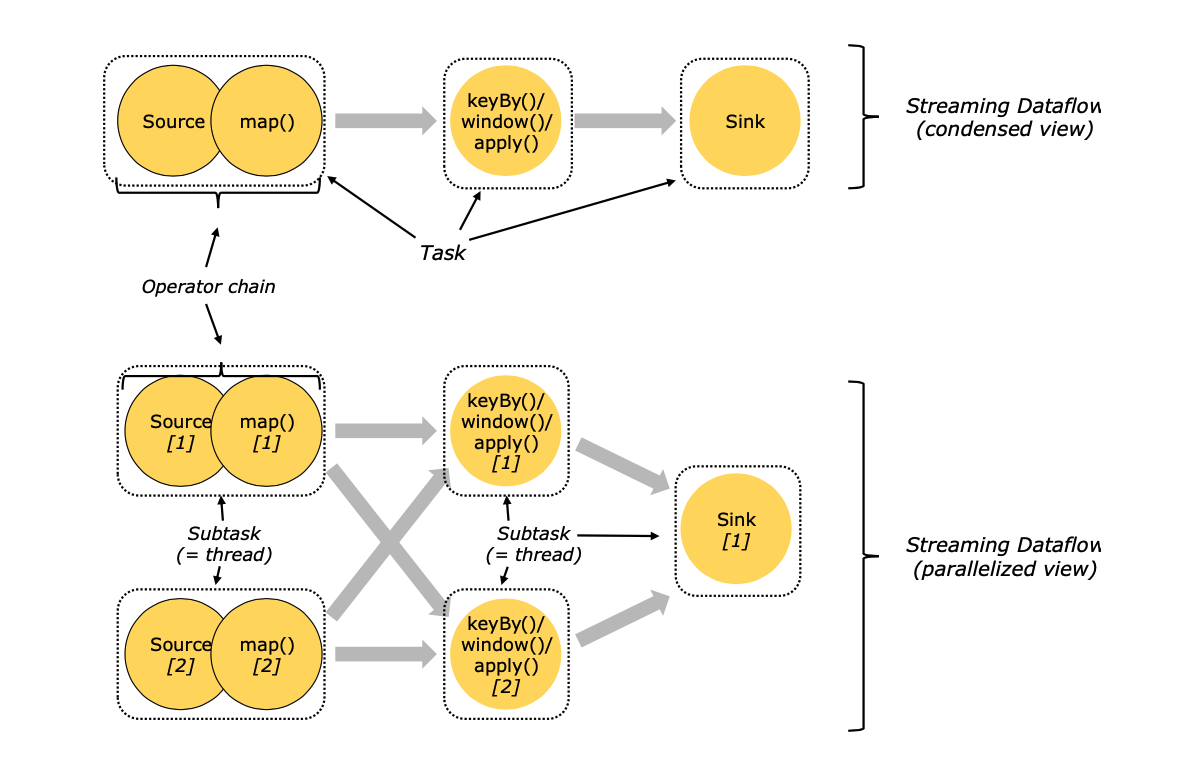
任务槽和资源
每个worker(TaskManager)都是一个JVM进程,可以在单独的线程中执行一个或多个子任务。为了控制一个任务管理器接受多少任务,它有所谓的任务槽(至少一个)。
每个任务槽代表任务管理器的一个固定的资源子集。例如,一个有三个槽的任务管理器,将把其管理内存的1/3奉献给每个槽。槽位资源意味着一个子任务不会与其他任务的子任务争夺管理内存,而是拥有一定量的预留管理内存。需要注意的是,这里并没有发生CPU隔离,目前插槽只是将任务的管理内存分开。
通过调整任务槽的数量,用户可以定义子任务之间的隔离方式。每个任务管理器有一个插槽意味着每个任务组都在一个单独的JVM中运行(例如可以在一个单独的容器中启动)。拥有多个插槽意味着更多的子任务共享同一个JVM。同一JVM中的任务共享TCP连接(通过多路复用)和心跳消息。它们还可以共享数据集和数据结构,从而减少每个任务的开销。
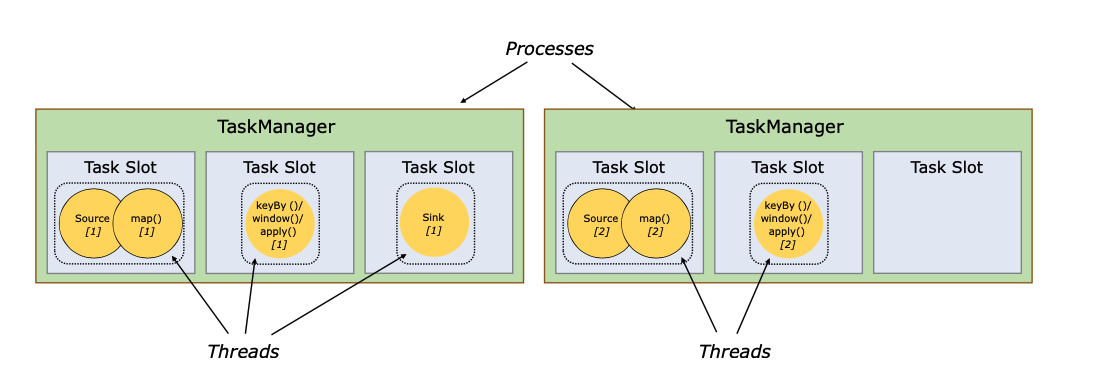
默认情况下,Flink允许子任务共享槽,即使它们是不同任务的子任务,只要它们来自同一个作业。其结果是,一个槽可以容纳整个作业的流水线。允许这种槽位共享有两个主要好处。
- 一个Flink集群需要的任务槽数量正好与作业中使用的最高并行度相同。不需要计算一个程序总共包含多少个任务(具有不同的并行度)。
- 更容易获得更好的资源利用率。如果没有槽位共享,非密集型的source/map()子任务和资源密集型的window子任务一样,会阻塞很多资源。有了槽位共享,在我们的例子中,将基础并行度从2个增加到6个,就会产生槽位资源的充分利用,同时确保重度子任务在TaskManager中公平分配。
Flink应用程序执行
Flink应用程序是任何从其main()方法中生成一个或多个Flink作业的用户程序。这些作业的执行可以发生在本地JVM(LocalEnvironment)中,也可以发生在多台机器的远程集群设置(RemoteEnvironment)中。对于每个程序,ExecutionEnvironment提供了控制作业执行的方法(例如设置并行性)和与外界交互的方法(参见Anatomy of a Flink Program)。
Flink应用的作业可以提交到一个长期运行的Flink会话集群、一个专门的Flink作业集群或一个Flink应用集群。这些选项之间的区别主要与集群的生命周期和资源隔离保证有关。
Flink会话集群
集群生命周期:在Flink会话集群中,客户端连接到一个预先存在的、长期运行的集群,可以接受多个作业提交。即使在所有作业完成后,集群(和JobManager)将继续运行,直到会话被手动停止。因此,一个Flink会话集群的寿命不受任何Flink作业寿命的约束。
资源隔离:TaskManager插槽由ResourceManager在作业提交时分配,作业完成后释放。因为所有作业都共享同一个集群,所以对集群资源有一定的竞争--比如提交作业阶段的网络带宽。这种共享设置的一个限制是,如果一个任务管理器崩溃,那么所有在这个任务管理器上有任务运行的作业都会失败;同样,如果在作业管理器上发生一些致命的错误,也会影响集群中运行的所有作业。
其他考虑因素:拥有一个预先存在的集群,可以节省大量申请资源和启动TaskManagers的时间。这在作业的执行时间非常短,高启动时间会对端到端用户体验产生负面影响的场景中非常重要--就像对短查询的交互式分析一样,希望作业能够利用现有资源快速执行计算。
注:以前的Flink Session Cluster也被称为会话模式下的Flink Cluster。
Flink工作集群
- 集群生命周期:在Flink Job Cluster中,可用的集群管理器(如YARN或Kubernetes)为每个提交的作业旋转一个集群,这个集群只对该作业可用。在这里,客户端首先向集群管理器请求资源来启动JobManager,并将作业提交给运行在这个进程内部的Dispatcher。然后根据作业的资源需求,懒惰地分配TaskManager。作业完成后,Flink Job Cluster就会被拆掉。
- 资源隔离:JobManager的致命错误只影响该Flink Job Cluster中运行的一个作业。
- 其他考虑因素:由于ResourceManager需要申请并等待外部资源管理组件来启动TaskManager进程并分配资源,因此Flink Job Cluster更适合运行时间长、稳定性要求高、对启动时间较长不敏感的大型作业。
注:以前,Flink Job Cluster在作业(或每作业)模式下也被称为Flink Cluster。
Flink应用集群
- - 集群生命周期:Flink应用集群是一个专用的Flink集群,它只执行来自一个Flink应用的作业,并且main()方法运行在集群上而不是客户端上。作业提交是一个一步到位的过程:你不需要先启动一个Flink集群,然后向现有的集群会话提交作业,而是将你的应用逻辑和依赖关系打包成一个可执行的作业JAR,集群入口点(ApplicationClusterEntryPoint)负责调用main()方法来提取作业图。这允许你像在Kubernetes上部署其他应用一样部署Flink应用,例如。因此,Flink Application Cluster的寿命与Flink Application的寿命是绑定的。
- - 资源隔离:在Flink Application Cluster中,ResourceManager和Dispatcher的范围是单一的Flink Application,这比Flink Session Cluster提供了更好的分离关注点。
注:Flink Job Cluster可以看作是Flink Application Cluster的 "run-on-client "替代品。