原文参见DeepMind的博客:https://www.deepmind.com/blog/article/replay-in-biological-and-artificial-neural-networks
作者:Zeb Kurth-Nelson, Will Dabney
One of a series of posts explaining the theories underpinning our research.
一系列解释理论基础的文章之一,这些理论是我们研究的基础。
Our waking and sleeping lives are punctuated by fragments of recalled memories: a sudden connection in the shower between seemingly disparate thoughts, or an ill-fated choice decades ago that haunts us as we struggle to fall asleep. By measuring memory retrieval directly in the brain, neuroscientists have noticed something remarkable: spontaneous recollections, measured directly in the brain, often occur as very fast sequences of multiple memories. These so-called 'replay' sequences play out in a fraction of a second–so fast that we're not necessarily aware of the sequence.
我们的清醒和睡眠生活被回忆的片段所打断:洗澡时看似截然不同的思想之间突然的联系,或者数十年前不幸的选择困扰着我们,使我们难以入睡。通过直接在大脑中测量记忆恢复,神经科学家注意到了一些了不起的事情:直接在大脑中测量的自发性回忆通常以非常快速的多重记忆序列出现。这些所谓的“回放”序列会在不到一秒的时间内播放完毕,以至于我们不一定知道该序列。
In parallel, AI researchers discovered that incorporating a similar kind of experience replay improved the efficiency of learning in artificial neural networks. Over the last three decades, the AI and neuroscientific studies of replay have grown up together. Machine learning offers hypotheses sophisticated enough to push forward our expanding knowledge of the brain; and insights from neuroscience guide and inspire AI development. Replay is a key point of contact between the two fields because like the brain, AI uses experience to learn and improve. And each piece of experience offers much more potential for learning than can be absorbed in real-time–so continued offline learning is crucial for both brains and artificial neural nets.
同时,人工智能研究人员发现,结合类似的经验回放可以提高人工神经网络中学习的效率。在过去的三十年中,AI和回放的神经科学研究共同发展。机器学习提供了足够复杂的假设,以推动我们不断扩展的大脑知识;和来自神经科学的见识指导并启发了AI的发展。回放是这两个领域之间联系的关键点,因为AI就像大脑一样,会利用经验来学习和改进。而且,每一次经验都提供了比实时吸收更多的学习潜能——因此,持续离线学习对于大脑和人工神经网络都至关重要。
Replay in the brain
Neural replay sequences were originally discovered by studying the hippocampus in rats. As we know from the Nobel prize winning work of John O’Keefe and others, many hippocampal cells fire only when the animal is physically located in a specific place. In early experiments, rats ran the length of a single corridor or circular track, so researchers could easily determine which neuron coded for each position within the corridor.
神经回放序列最初是通过研究大鼠海马体发现的。我们从John O’Keefe等人的诺贝尔奖获奖作品中知道,许多海马细胞只有在动物物理上位于特定位置时才会发放。在早期的实验中,大鼠沿着一条走廊或圆形轨道运行,因此研究人员可以轻松确定走廊中每个位置所编码的神经元。
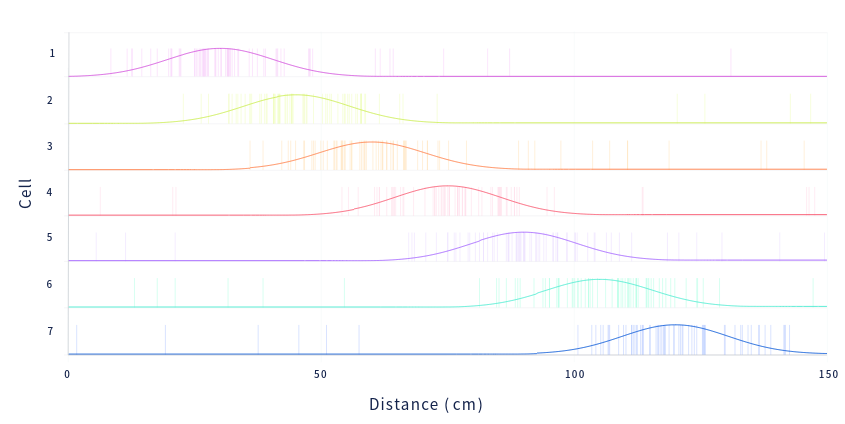
When rats are awake and active, each hippocampal place cell codes for a particular location in space. Each row is a different cell, and they are sorted by the location they represent. Each vertical tick mark is an action potential. The solid lines represent smoothed firing rates.
当大鼠处于清醒状态且活跃时,每个海马体位置的细胞都会为空间中的特定位置编码。每行是一个不同的细胞,并按其表示的位置对其进行排序。每个垂直刻度线都是一个动作电位。实线表示平滑的发放率。
Afterwards, the scientists recorded from the same neurons while the rats rested. During rest, the cells sometimes spontaneously fired in rapid sequences demarking the same path the animal ran earlier, but at a greatly accelerated speed. These sequences are called replay. An entire replay sequence only lasts a fraction of a second, but plays through several seconds worth of real experience.
之后,科学家们在大鼠休息时从相同的神经元中进行记录。在休息期间,细胞有时会以快速序列自发发放,这标志着动物较早地奔跑的相同路径,但速度大大加快。这些序列称为回放。整个回放序列只需要一秒钟的时间,但却可以播放几秒钟的真实经验。
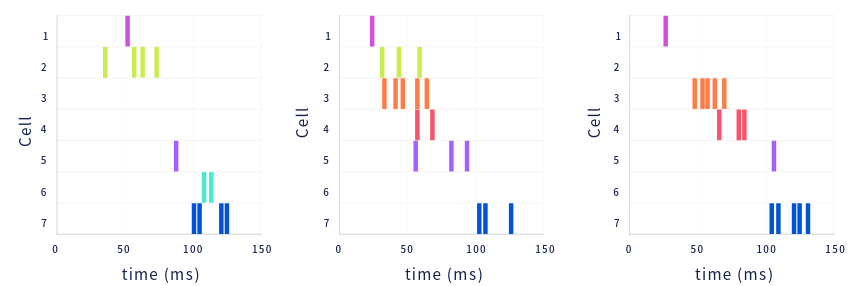
During rest, place cells spontaneously fire in fast sequences that sweep through paths in the environment.
在休息期间,位置细胞以快速序列自发发放,并扫过环境中的路径。
We now know replay is essential for learning. In a number of more recent experiments, researchers recorded from hippocampus to detect a signature of replay events in real time. By disrupting brain activity during replay events (either during sleep or wakeful resting), scientists significantly impaired rodents’ ability to learn a new task. The same disruption applied 200 milliseconds out of sync with replay events had no effect on learning.
现在我们知道回放对于学习至关重要。在许多最近的实验中,研究人员从海马记录下来,以实时检测回放事件的特征。通过在回放事件期间(睡眠或清醒休息期间)破坏大脑活动,科学家极大地损害了啮齿动物学习新任务的能力。与回放事件不同步地应用了200毫秒的相同中断对学习没有影响。
While these experiments have been revealing, a significant limitation of rodent experiments is the difficulty of studying more sophisticated aspects of cognition, such as abstract concepts. In the last few years, replay-like sequences have also been detected in human brains, supporting the idea that replay is pervasive, and expanding the kinds of questions we can ask about it.
虽然这些实验已经揭示出来,但是啮齿动物实验的一个显著局限是研究认知的更复杂方面(例如抽象概念)的困难。在过去的几年中,还可以在人脑中检测到类似回放的序列,这支持回放无处不在的想法,并扩展了我们可以提出的各种问题。
Replay in artificial intelligence

Artificial neural networks collect experience by interacting with the environment, save that experience to a replay buffer, and later play it back to continue learning from it.
人工神经网络通过与环境交互来收集经验,将该经验保存到回放缓存区中,然后进行回放以继续从中学习。
Incorporating replay in silico has been beneficial to advancing artificial intelligence. Deep learning often depends upon a ready supply of large datasets. In reinforcement learning, these data come through direct interaction with the environment, which takes time. The technique of experience replay allows the agent to repeatedly rehearse previous interactions, making the most of each interaction. This method proved crucial for combining deep neural networks with reinforcement learning in the DQN agent that first mastered multiple Atari games.
将回放整合到计算机中已对推进人工智能有所帮助。深度学习通常取决于大型数据集的现成供应。在强化学习中,这些数据通过与环境的直接交互获得,这需要时间。经验回放技术使智能体可以重复演练以前的交互,从而充分利用每个交互。实践证明,该方法对于将深度神经网络与DQN智能体中的强化学习相结合至关重要,而DQN智能体首先掌握了多种Atari游戏。
Since the introduction of DQN, the efficiency of replay has been improved by preferentially replaying the most salient experiences from memory, rather than simply choosing experiences at random for replay. And recently, a variant of preferential replay has been applied as a model in neuroscience to successfully explain empirical data from brain recordings.
自从引入DQN以来,通过优先从内存中回放最显著的经验,而不是简单地随机选择要回放的经验,这提高了重播的效率。最近,优先回放的一种变体已被用作神经科学的模型,以成功地解释来自大脑记录的经验数据。
Further improvements in agent performance have come from combining experiences across multiple agents, learning about a variety of different behaviours from the same set of experiences, and replaying not only the trajectory of events in the world, but also the agent's corresponding internal memory states. Each of these methods makes interesting predictions for neuroscience that remain largely untested.
智能体性能的进一步提高来自以下方面:组合多个智能体的经验,从同一组经验中了解各种不同的行为,不仅回放事件的轨迹,而且回放智能体的相应内部记忆状态。这些方法中的每一种都对神经科学做出了有趣的预测,而这些预测在很大程度上尚未得到测试。
Movie versus imagination
As mentioned above, research into experience replay has unfolded along parallel tracks in artificial intelligence and neuroscience, with each field providing ideas and inspiration for the other. In particular, there is a central distinction, which has been studied in both fields, between two versions of replay.
如上所述,对经验回放的研究已经沿着人工智能和神经科学的平行方向展开,每个领域都为另一个领域提供了想法和灵感。特别是,在两个版本的回放之间存在着一个中心的区别,这已经在两个领域中进行了研究。
Suppose you come home and, to your surprise and dismay, discover water pooling on your beautiful wooden floors. Stepping into the dining room, you find a broken vase. Then you hear a whimper, and you glance out the patio door to see your dog looking very guilty.
假设你回家了,令你惊讶和沮丧的是,你发现美丽的木地板上积水了。走进餐厅,你会发现一个破花瓶。然后,你会听到一阵刺耳的声音,然后瞥了一眼露台门,发现狗狗看起来非常内疚。

A sequence of events, as they were experienced.
他们经历的一系列事件。
In the first version of replay, which we could call the "movie" version, when you sit down on the couch and take a rest, replay faithfully rehearses the actual experiences of the past. This theory says that your brain will replay the sequence: "water, vase, dog". In AI terms, the past experience was stored in a replay buffer, and trajectories for offline learning were drawn directly from the buffer.
在第一个回放版本中,我们可以将其称为“电影”版本,当你坐在沙发上休息时,忠实地重放过去的实际经历。这个理论说,你的大脑将回放该序列:“水,花瓶,狗”。用AI术语来说,过去的经验存储在经验缓存区中,离线学习的轨迹直接从缓存区中抽取。
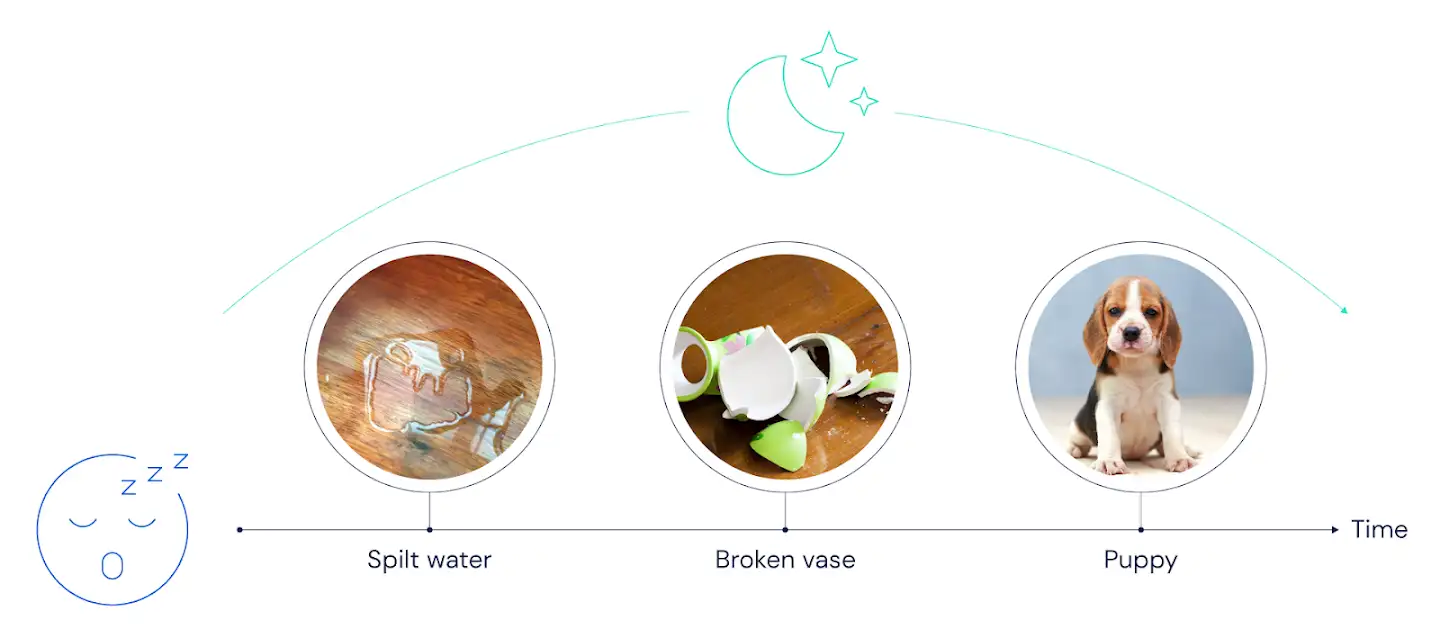
"Movie" replay: events are played back in the same order as they occurred.
“电影”重播:事件回放的顺序与发生的顺序相同。
In the second version, which we might call "imagination," replay doesn’t literally rehearse events in the order they were experienced. Instead, it infers or imagines the real relationships between events, and synthesises sequences that make sense given an understanding of how the world works. In AI terms, these replay sequences are generated using a learned model of the environment.
在第二个版本中,我们可以将其称为“想象力”,回放实际上并不按照事件经历的顺序来排练。取而代之的是,它推断或想象事件之间的真实关系,并综合考虑到对世界运作方式有意义的序列。用AI术语来说,这些回放序列是使用学到的环境模型生成的。
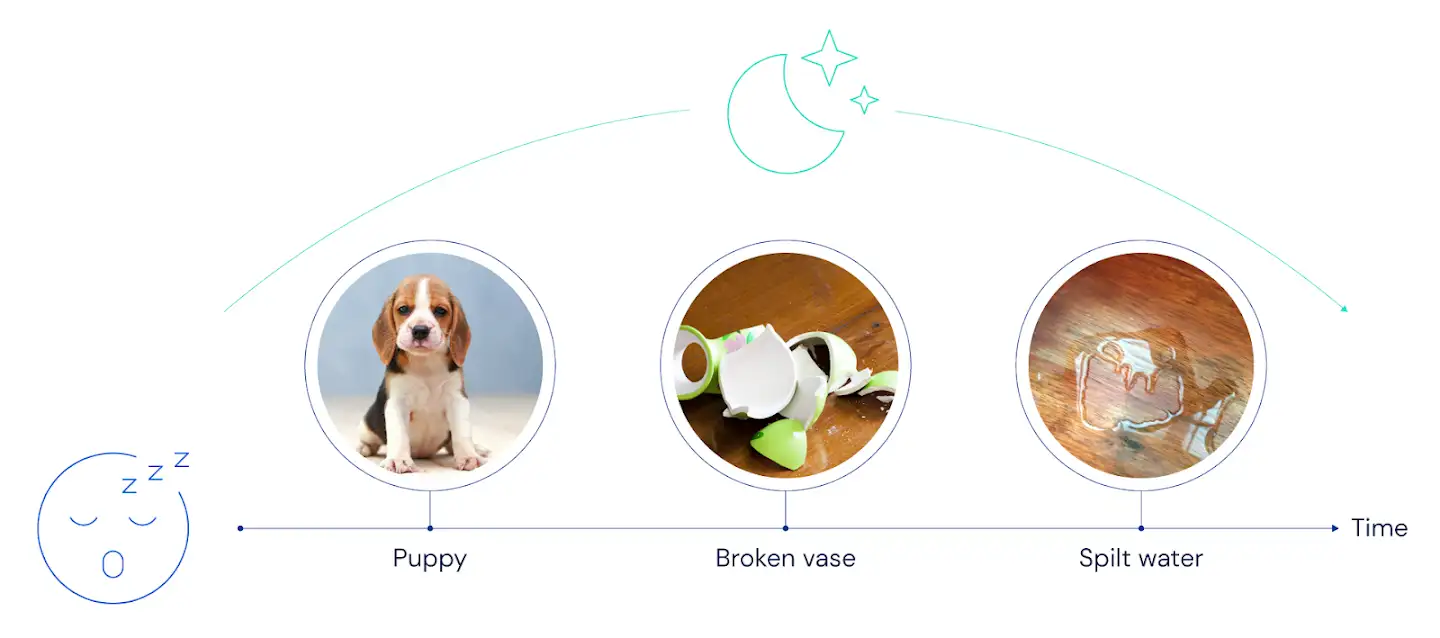
"Imagination" replay: events are played back in a synthesised order which respects knowledge of the structure of the world.
“想象”回放:以尊重世界结构知识的合成顺序回放事件。
The imagination theory makes a different prediction about how replay will look: when you rest on the couch, your brain should replay the sequence "dog, vase, water". You know from past experience that dogs are more likely to cause broken vases than broken vases are to cause dogs–and this knowledge can be used to reorganise experience into a more meaningful order.
想象理论对回放的情况有不同的预测:当你坐在沙发上时,你的大脑应回放“狗,花瓶,水”的序列。你可以从过去的经验中知道,狗比花瓶破掉的可能性更大,而这种知识可以用来将经验重新整理成更有意义的顺序。
In deep RL, the large majority of agents have used movie-like replay, because it is easy to implement (the system can simply store events in memory, and play them back as they happened). However, RL researchers have continued to study the possibilities around imagination replay.
在深度RL中,大多数智能体都使用类似于电影的重放,因为它易于实现(系统可以简单地将事件存储在内存中,并在事件发生时进行回放)。但是,RL研究人员继续研究围绕想象回放的可能性。
Meanwhile in neuroscience, classic theories of replay postulated that movie replay would be useful to strengthen the connections between neurons that represent different events or locations in the order they were experienced. However, there have been hints from experimental neuroscience that replay might be able to imagine new sequences. The most compelling observation is that even when rats only experienced two arms of a maze separately, subsequent replay sequences sometimes followed trajectories from one arm into the other.
同时,在神经科学中,经典的回放理论假设电影回放将有助于加强神经元之间的联系,这些神经元以经历的顺序表示不同的事件或位置。但是,实验神经科学已经暗示回放可能能够想象新的序列。最有说服力的观察结果是,即使大鼠仅分别经历了迷宫的两个手臂,随后的回放序列有时仍会从一个手臂移动到另一个手臂。
But studies like this leave open the question of whether replay simply stitches together chunks of experienced sequences, or if it can synthesise new trajectories from whole cloth. Also, rodent experiments have been primarily limited to spatial sequences, but it would be fascinating to know whether humans' ability to imagine sequences is enriched by our vast reserve of abstract conceptual knowledge.
但是像这样的研究留下了一个问题,那就是回放是否只是将经历的片段简单地拼接在一起,或者它是否可以从整个经历中合成出新的轨迹。同样,啮齿动物实验主要局限于空间序列,但是了解人类对序列的想象能力是否会因我们丰富的抽象概念知识储备而变得令人着迷。
A new replay experiment in humans
We asked these questions in a set of recent experiments performed jointly between UCL, Oxford, and DeepMind.
我们在UCL,Oxford和DeepMind之间共同执行的一组最近的实验中提出了这些问题。
In these experiments, we first taught people a rule that defined how a set of objects could interact. The exact rule we used can be found in the paper. But to continue in the language of the "water, vase, dog" example, we can think of the rule as the knowledge that dogs can cause broken vases, and broken vases can cause water on the floor. We then presented these objects to people in a scrambled order (like "water, vase, dog"). That way, we could ask whether their brains replayed the items in the scrambled order that they experienced, or in the unscrambled order that meaningfully connected the items. They were shown the scrambled sequence and then given five minutes to rest, while sitting in an MEG brain scanner.
在这些实验中,我们首先教给人们一个规则,该规则定义了一组对象如何相互作用。 我们使用的确切规则可以在论文中找到。但是,以“水,花瓶,狗”为例,我们可以将规则看作是这样的知识,即狗会造成花瓶破损,而花瓶会在地板上积水。然后,我们以混乱的顺序将这些对象呈现给人们(例如“水,花瓶,狗”)。这样,我们可以问他们的大脑是按照他们经历的混乱顺序还是按照有意义地将各项联系在一起的无扰动顺序回放了这些物品。向他们展示了混乱的顺序,然后坐在MEG脑部扫描仪中休息了5分钟。
As in previous experiments, fast replay sequences of the objects were evident in the brain recordings. (In yet another example of the virtuous circle between neuroscience and AI, we used machine learning to read out these signatures from cortical activity.) These spontaneous sequences played out rapidly over about a sixth of a second, and contained up to four objects in a row. However, the sequences did not play out in the experienced order (i.e., the scrambled order: spilled water –> vase –> dog). Instead, they played out the unscrambled, meaningful order: dog –> vase –> spilled water. This answers–in the affirmative–the questions of whether replay can imagine new sequences from whole cloth, and whether these sequences are shaped by abstract knowledge.
和以前的实验一样,在大脑记录中可以清楚地看到对象的快速回放序列。(在神经科学与AI之间良性循环的另一个例子中,我们使用机器学习从皮质活动中读取了这些特征。) 这些自发序列在大约六分之一秒内迅速播放,并在一列中包含多达四个对象。但是,这些序列并没有按照经验顺序显示(即乱序:洒水–>花瓶–>狗)。取而代之的是,他们播放了无误的有意义的顺序:狗–>花瓶–>洒水。这肯定地回答了以下问题:回放是否可以想象整个经历中的新序列,以及这些序列是否由抽象知识塑造而成。
However, this finding still leaves open the important question of how the brain builds these unscrambled sequences. To try to answer this, we played a second sequence for participants. In this sequence, you walk into your factory and see spilled oil on the floor. You then see a knocked over oil barrel. Finally, you turn to see a guilty robot. To unscramble this sequence, you can use the same kind of knowledge as in the "water, vase, dog" sequence: knowledge that a mobile agent can knock over containers, and those knocked-over containers can spill liquid. Using that knowledge, the second sequence can also be unscrambled: robot –> barrel –> spilled oil.
但是,这一发现仍然留下了一个重要的问题,即大脑如何构建这些未打乱的序列。为了回答这个问题,我们为参与者播放了第二个序列。按此顺序,你走进工厂,看到地板上洒了油。然后,你会看到撞倒的油桶。最后,您转向看一个有罪的机器人。要弄清楚该序列,可以使用与“水,花瓶,狗”序列相同的知识:移动智能体可以撞倒容器,而那些被撞倒的容器可以溢出液体的知识。利用这些知识,第二个序列也可以理解为:机器人–>桶–>漏油。
By showing people multiple sequences with the same structure, we could examine two new types of neural representation. First, the part of the representation that is common between spilled water and spilled oil. This is an abstract code for "a spilled liquid", invariant over whether we're in the home sequence or the factory sequence. And second, the part of the representation that is common between water, vase and dog. This is an abstract code for "the home sequence," invariant over which object we're considering.
通过向人们展示具有相同结构的多个序列,我们可以检查两种新型的神经表征。首先,表征的部分在泄漏的水和泄漏的油之间很常见。这是“溢出的液体”的抽象代码,无论我们是在家中还是在工厂中,它都是不变的。第二,水,花瓶和狗之间常见的表示部分。这是“家序列”的抽象代码,它与我们正在考虑的对象无关。
We found both of these types of abstract codes in the brain data. And to our surprise, during rest they played out in fast sequences that were precisely coordinated with the spontaneous replay sequences mentioned above. Each object in a replay sequence was preceded slightly by both abstract codes. For example, during a dog, vase, water replay sequence, the representation of "water" was preceded by the codes for "home sequence" and "spilled liquid".
我们在大脑数据中发现了这两种类型的抽象代码。令我们惊讶的是,在休息期间,它们以与上述自发回放序列精确协调的快速序列播放。回放序列中的每个对象都比两个抽象代码稍稍早一点。例如,在“狗,花瓶,水”回放序列中,“水”的表示之前带有“家序列”和“洒出的液体”的代码。
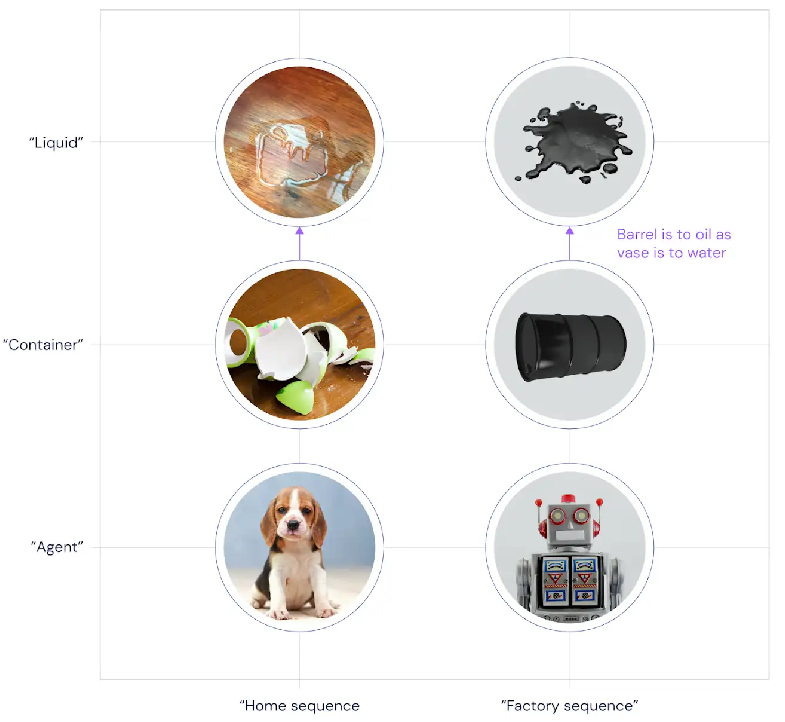
Structurally similar sequences in different contexts slotted into a common analogical framework
在不同上下文中结构相似的序列插入一个通用的类比框架
These abstract codes, which incorporate the conceptual knowledge that lets us unscramble the sequences, may help the brain to retrieve the correct item for the next slot in the replay sequence. This paints an interesting picture of a system where the brain slots new information into an abstract framework built from past experiences, keeping it organized using precise relative timings within very fast replay sequences. Each position within a sequence could be thought of as a role in an analogy (as in the above figure). Finally, we speculate that during rest, the brain may explore novel implications of previously-learned knowledge by placing an item into an analogy in which it's never been experienced, and examining the consequences.
这些抽象代码结合了概念知识,可以让我们对序列进行解读,可以帮助大脑为回放序列中的下一个时隙检索正确项。这描绘了一个有趣的系统图,其中大脑将新信息分配到根据过去的经验构建的抽象框架中,并在非常快速的回放序列中使用精确的相对时间来组织信息。序列中的每个位置都可以被认为是类推的角色(如上图所示)。最后,我们推测在休息期间,大脑可能会通过将一个项目置于从未经历过的类比中并检查其后果,来探索先前学习的知识的新颖含义。
The virtuous circle, continued
Coming back to the virtuous circle, analogy and abstraction are relatively underused in current neural network architectures. The new results described above both indicate that the imagination style of replay may be a fruitful avenue to continue pursuing in AI research, and suggest directions for neuroscience research to learn more about the brain mechanisms underlying analogy and abstraction. It's exciting to think about how data from the brain will continue helping with the advance toward better and more human-like artificial intelligence.
回到良性循环,类比和抽象在当前的神经网络结构中相对未得到充分利用。上面描述的新结果都表明,回放的想象风格可能是继续从事AI研究的富有成果的途径,并且为神经科学研究提供了方向,以了解有关类比和抽象的大脑机制的更多信息。考虑到来自大脑的数据将如何继续帮助实现更好,更像人类的人工智能,这是令人兴奋的。
The new work reported in Cell was done by Yunzhe Liu, Ray Dolan, Zeb Kurth-Nelson and Tim Behrens, and was a collaboration between DeepMind, the Wellcome Centre for Human Neuroimaging (UCL), the Max Planck-UCL Centre for Computational Psychiatry and Ageing Research, and the Wellcome Centre For Integrative Neuroimaging (Oxford).