ipython notebook
命令行输入ipython notebook
此时,浏览器会自动运行并打开ipython网页
基本操作
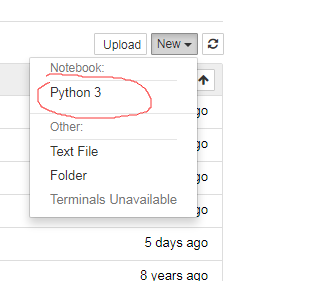
如上图所示,新建一个项目
导入相关模块,建立一个数据集
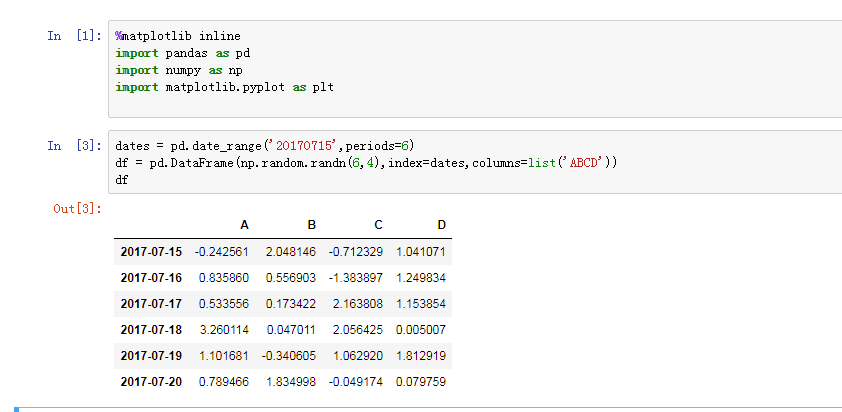
制造数据缺失项,并给新插入部分部分赋值

这样就构造了一个二维的DataFrame数组,其中包含了一些空数据
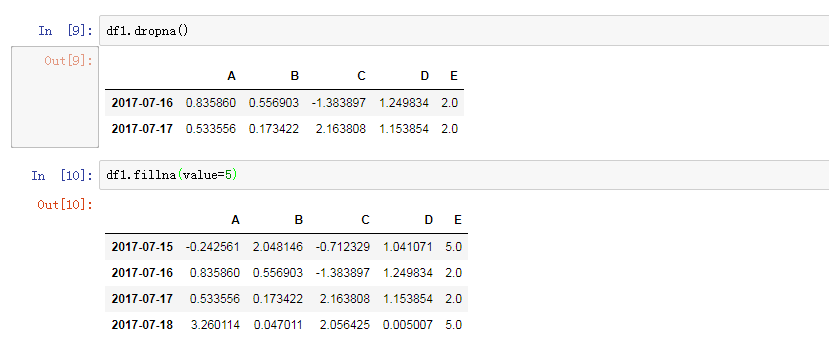
处理空数据一般有两种
dropna(),将含有空值行去掉
fillna(values=5)将空值替换成默认值
pd.isnull(df1) 可以判断元素是否是空数据,加any().any()可以得到是否有空数据的布尔值


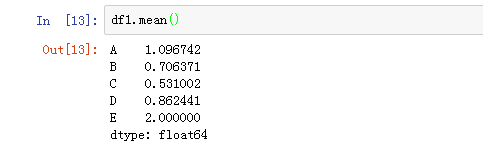
按列求平均值计算:(空值不参与计算)
按行求平均值计算:(空值不参与计算)

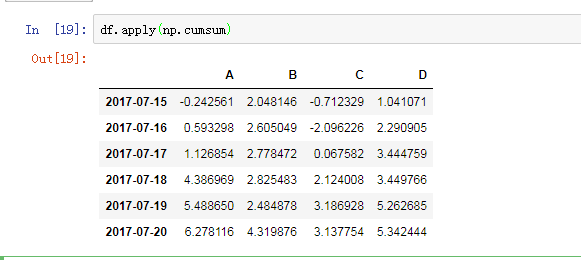
按列求累加值:(空值不参与计算)

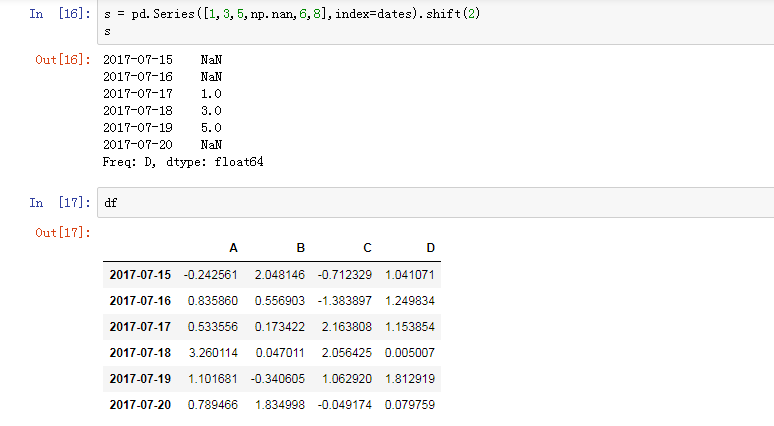
当两个维数不同的数组相减时,被减的数组会复制当前列补全被减数组的维数,空值不参与运算

按行累加
每一列最大值减最小值
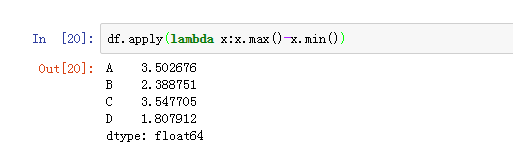
apply函数输入的是个序列

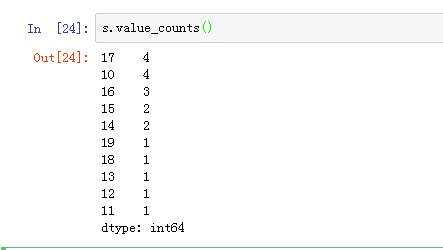
value_counts()查看元素出现的次数与.mode()查看出现次数最多的元素
先创建一个随机序列
调用value_counts()
调用.mode()查看出现次数最多的元素

数据合并
先创建一个10*4的数组

(1)调用concat()函数合并数组(concat接受的是一个数组,数组里面是要合并的数组)
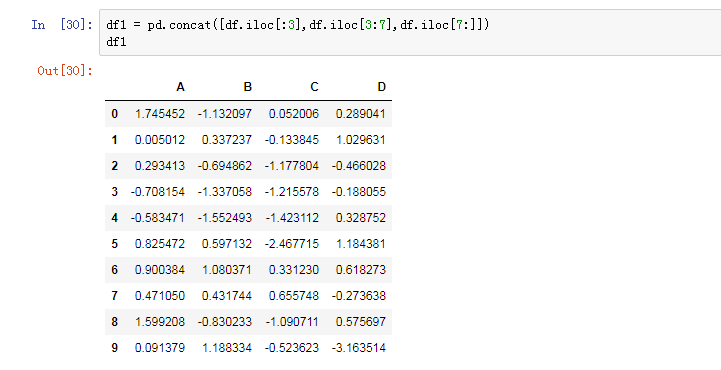
查看合并后的数组是否与原数组相等

或

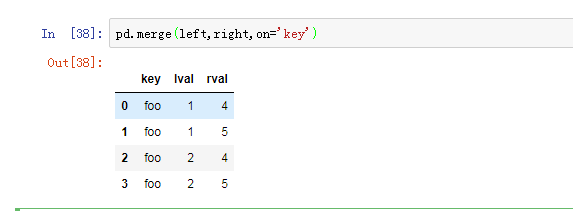
(2)通过merge合并,类似于表join关联
先创建两个数组

调用merge,等价于select * from left inner join right on left.key = right.key;
(3)插入方式合并数组
先创建一个数组

调用append,如果插入列数不同,将为缺失值

分类统计
先创建数组

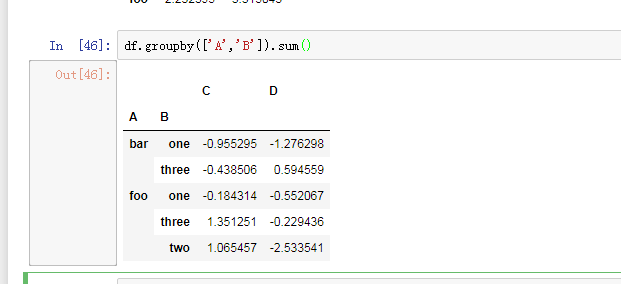
单个对'A‘’分组,groupby('A')
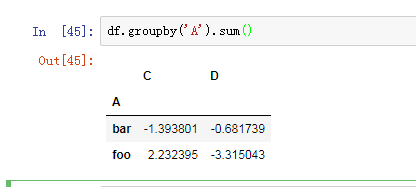
多分组,groupby([])
数据整形
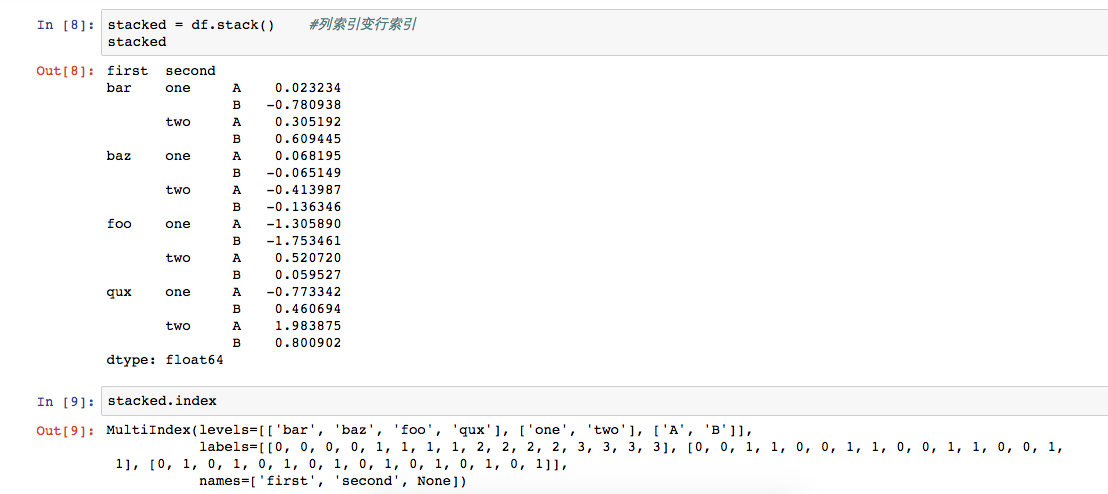
概括:行索引与列索引做位置互换
先创建一个元组列表

给双层索引重新命名

创建一个8*2的数组
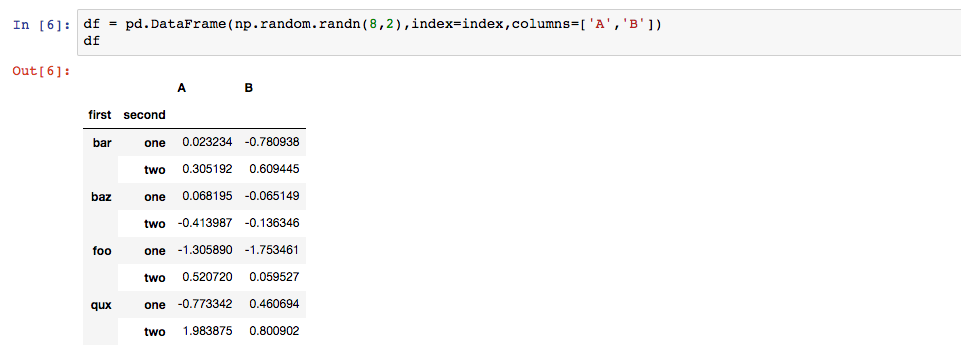
调用stack()函数将列索引变行索引,
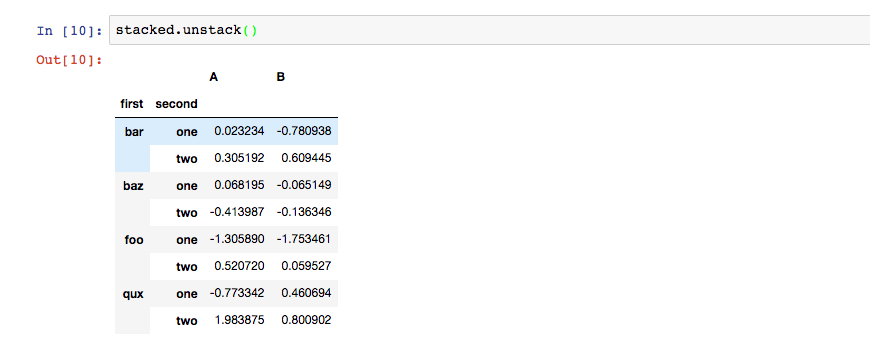
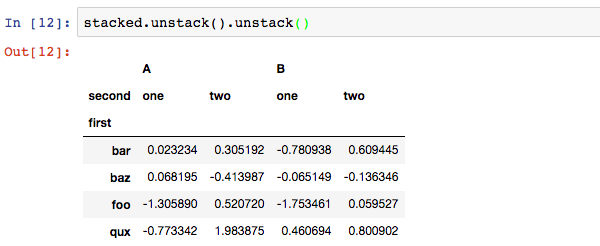
调用unstack()将最后一层行索引转换为列索引,每调用一次,取一层行索引转换为列索引
数据透视
概念:根据需求只看数组中的一部分
先创建一个数组
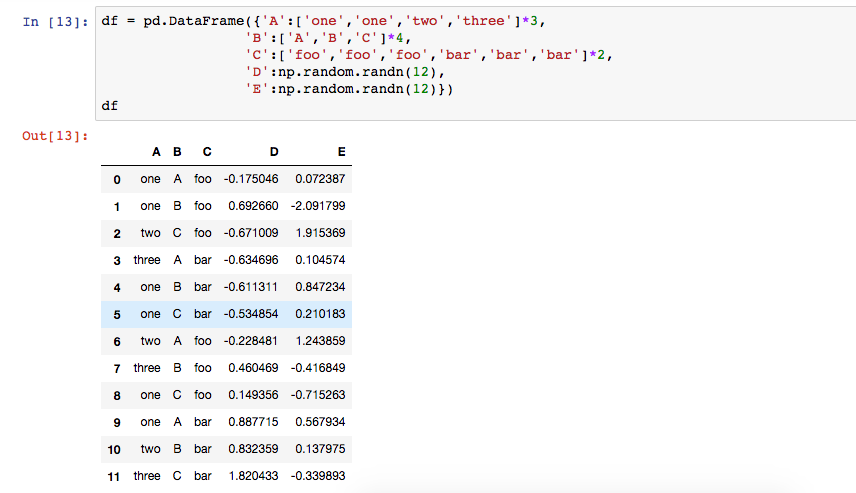
调用pivot_table(),参数为values、index、columns,分别表示要查看的列数据与行索引与列索引范围
比如查看D这一列,以A、B为联合行索引,以C为列索引的数据,如果对应数据不存在则为NaN,如果对应位置有多个值,则为平均值

时间序列
先创建时间序列

根据时间序列创建对应的随机数数组
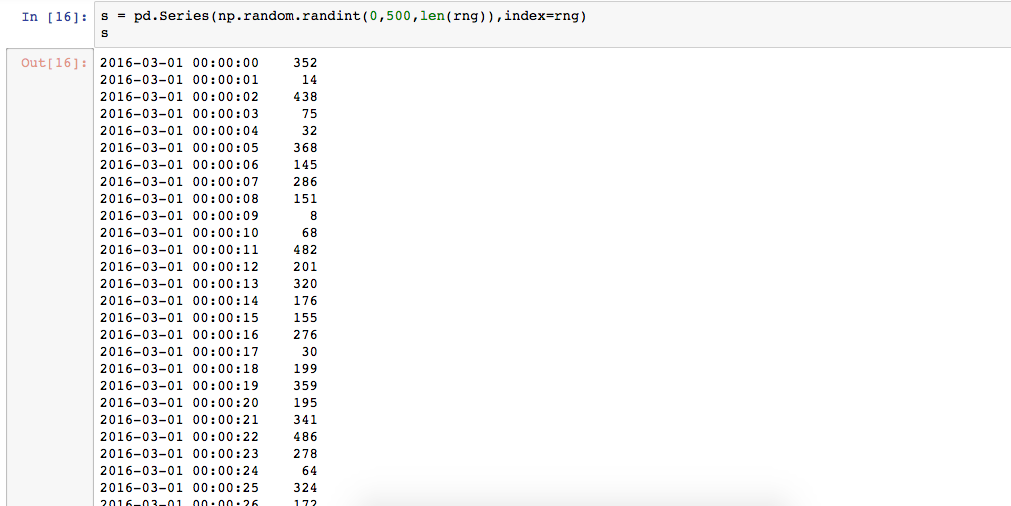
数据量过大时可以定义采样方法,调用resample()函数
如没两分钟采样求平均值

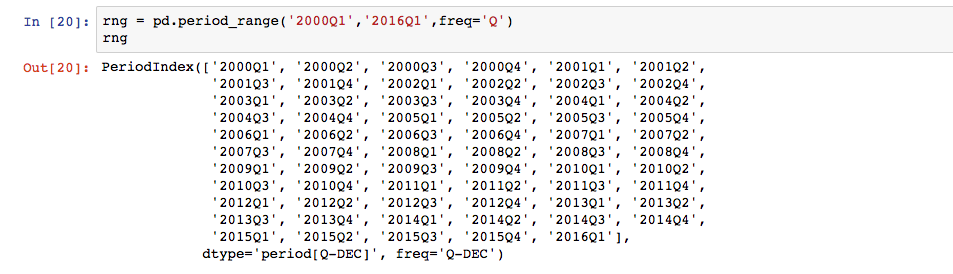
还有一种创建时间序列的方式:以季度创建
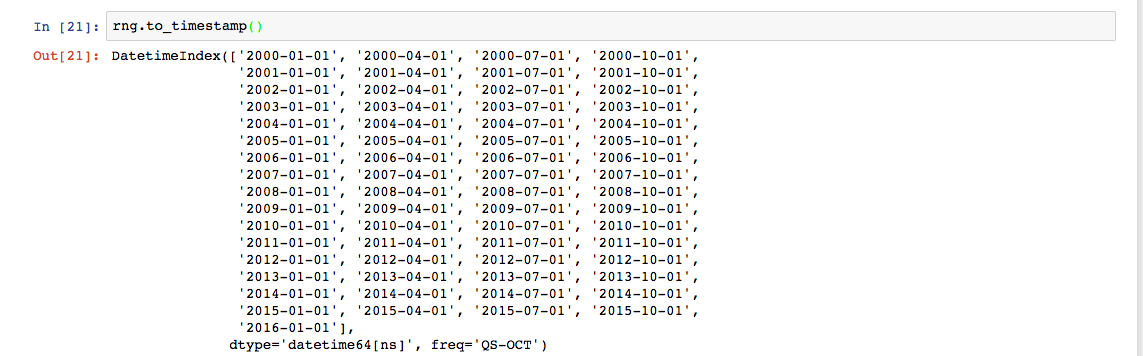
调用to_timestamp()可以转换为时间日期的格式
pandas对于时间的计算相当简单,如

类别数据
先创建一个数组

添加类别数据
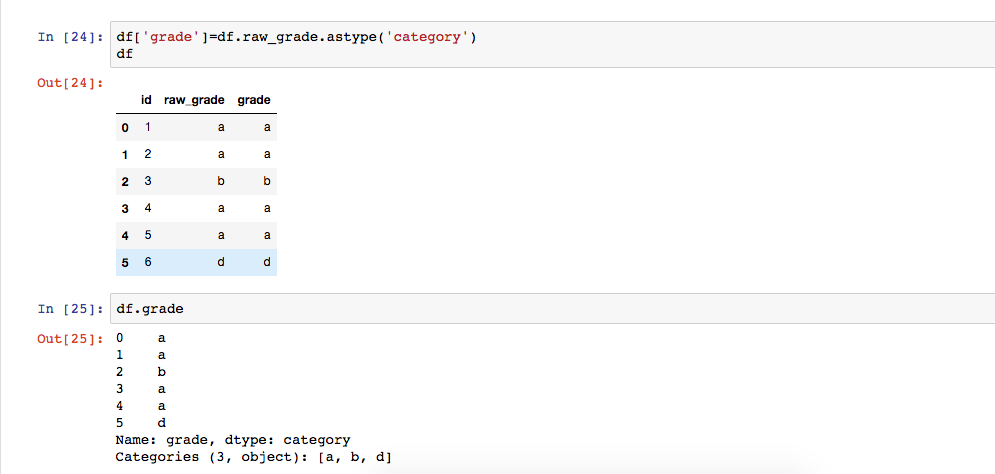
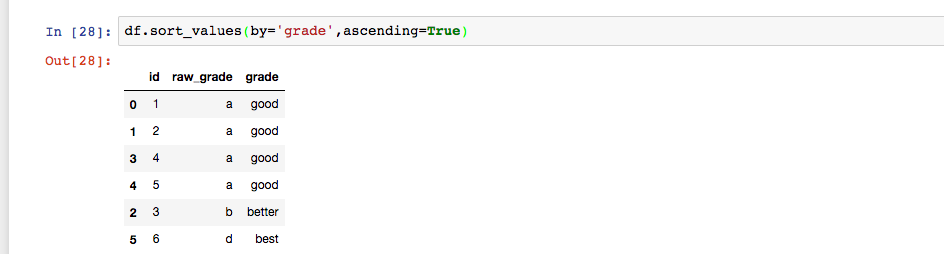
查看类别索引,并给类别索引重新赋值,如果对grade排序,并不是以grade排序,而是以raw_grade来排序

数据可视化
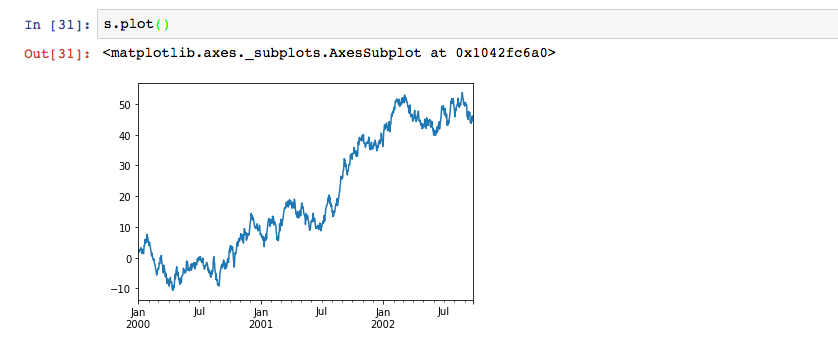
先创建一个数组

调用cumsum函数对数据求和

调用plot(),将数据可视化
数据读写
先创建一个数组
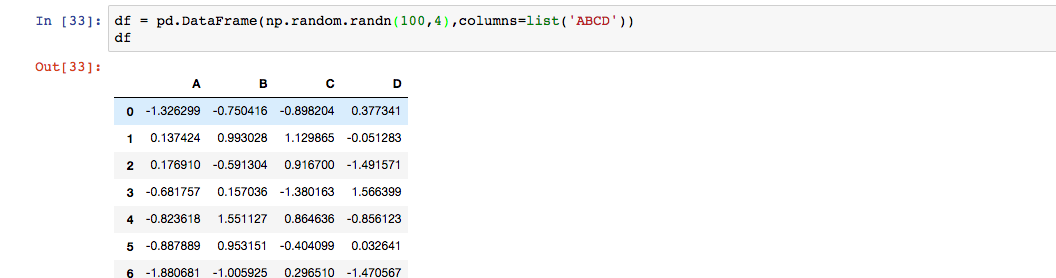
调用to_csv('file.csv')将数据写入磁盘

调用pd.read_csv('file.csv')读出磁盘文件数据,加参数指定索引列,否则之前的索引列会被当成数据列产生异常
