郑重声明:原文参见标题,如有侵权,请联系作者,将会撤销发布!

Abstract
强化学习(RL)最近以击败欧洲围棋冠军等重大成就重新受到欢迎。在这里,我们第一次表明,RL可以有效地用于训练一个脉冲神经网络(SNN),以在不使用外部分类器的情况下在自然图像中执行目标识别。我们使用了前向卷积SNN和时间编码方案,其中激活最强的神经元最先发放,而激活较弱的神经元随后发放,或者根本不发放。在最高层,每个神经元都被分配到一个目标类别,并且假设刺激类别是第一个要发放的神经元类别。如果这一假设是正确的,神经元就会得到奖励,即采用脉冲时间相关可塑性(spike-timing-dependent plasticity,STDP),从而增强神经元的选择性。另外,anti-STDP被应用,这鼓励了神经元学习其他东西。正如在各种图像数据集(Caltech、ETH-80和NORB)上所证明的那样,这种奖励调节STDP(reward-modulated STDP,R-STDP)方法提取了特别有区分度的视觉特征,而经典的无监督STDP提取了任何持续重复的特征。因此,R-STDP在这些数据集上的性能优于STDP。此外,R-STDP适合于在线学习,能够适应标签置换等剧烈变化。最后,值得一提的是,特征提取和分类都是用脉冲来完成的,每个神经元最多使用一个脉冲。因此,该网络对硬件友好且节能。
Index Terms
基于首次脉冲的分类、强化学习(RL)、奖励调节脉冲时间相关可塑性(R-STDP)、脉冲神经网络(SNN)、时间编码、视觉目标识别。
I. INTRODUCTION
大脑中的神经元通过突触连接,随着时间的推移,突触可以被加强或减弱。长期突触可塑性对学习至关重要,其背后的神经机制多年来一直在研究中。脉冲时间相关可塑性(STDP)是突触可塑性的一种无监督形式,在不同脑区[1-4]观察到,特别是在视觉皮层[5-7]。STDP的工作原理是考虑突触前和突触后脉冲的时差。根据这一规律,如果突触前神经元比突触后神经元更早(晚)发放,则突触增强(减弱)。研究表明,STDP产生符合检测器,通过这种检测器,神经元可以选择频繁的输入脉冲模式,从而在模式出现时产生动作电位[8-11]。STDP能够很好地发现统计上频繁出现的特征;然而,作为任何无监督的学习算法,它在检测罕见而可诊断的特征以实现决策等重要功能上都面临困难。
一些研究表明,大脑的奖励系统在决策和行为形成中起着至关重要的作用。这也被称为强化学习(RL),它鼓励学习者重复奖励行为,避免那些导致惩罚的行为[12–18]。研究发现,多巴胺作为一种神经调节剂,是奖励系统中的重要化学物质[19],其释放量与预期的未来奖励成正比[17, 20, 21]。多巴胺和其他一些神经调节剂也影响突触可塑性,如改变极性[22]或调整STDP的时间窗口[23-27]。
对奖励系统的作用进行建模的一个很好的研究思路是调节甚至逆转由STDP决定的权重变化,称为奖励调节STDP(R-STDP)[28]。R-STDP存储符合STDP的突触的迹,并在接收到调节信号时应用调节的权重变化:奖励或惩罚(负奖励)。
2007年,Izhikevich[29]提出了一个R-STDP规则来解决远端奖励问题,在这个问题上,奖励不会立即收到。他用一个逐渐衰退的合格迹来解决这个问题,根据这个迹,最近的活动被认为是更重要的。他证明了他的模型可以同时解决经典条件和起重要作用的条件[30, 31]。同年,Farries and Fairhall[32]使用R-STDP训练神经元产生特定的脉冲模式。他们测量了输出和目标脉冲训练之间的差异来计算奖励的价值。此外,Florian[33]还表明R-STDP能够通过脉冲或时间输入编码来解决异或任务,并学习目标发放率。一年后,Legenstein et al.[34]研究了R-STDP达到预期学习效果的条件。他们通过理论分析以及在生物反馈和两类别的孤立语音数字识别任务中的实际应用,证明了R-STDP的优越性。Vasilaki et al.[35]研究了R-STDP关于连续空间问题的思想。结果表明,该模型能够较快地求解Morris水迷宫问题,而标准的策略梯度规则失效。通过Frémaux et al.[36]的工作继续研究R-STDP的能力,其中理论上讨论了成功学习的条件。结果表明,对R-STDP同时学习多个任务来说,预测期望奖励是必要的。近年来,对大脑中RL机制的研究引起了人们的关注,研究人员试图通过奖励调节突触可塑性来解决更实际的任务。
视觉目标识别是一项复杂的任务,在这方面人类是专家。这项任务既需要由大脑视觉皮层完成的特征提取,也需要对涉及更高大脑区域的目标类别做出决策。脉冲神经网络(SNN)在计算目标识别模型中得到了广泛的应用。在网络结构方面,有几个模型具有浅层[40-43]、深层[44-46]、递归[47]、全连接[48]和卷积结构[40, 46, 49, 50]。一些使用基于脉冲的编码[51–53],而另一些使用时态编码[40, 43, 46, 48, 54]。从反向传播[49, 55]、Tempotron[43, 56]和其他有监督的技术[52, 53, 57, 58],到无监督的STDP和STDP变体[42, 48, 59],各种学习技术也被应用于SNN。虽然支持STDP的网络提供了一种更符合生物学原理的视觉特征提取方法,但它们需要外部读出,例如支持向量机(SVM)[46, 60],来对输入刺激进行分类。此外,STDP倾向于提取不一定适合所需任务的频繁特征。本文提出了一种基于R-STDP的分层SNN算法,在不使用任何外部分类器的情况下解决了自然图像中的视觉目标识别问题。相反,我们把特定类的神经元放在网络中,如果它们的目标刺激被呈现给网络,这些神经元会被增强到尽可能早的发放。因此,输入刺激仅根据初次脉冲延迟以一种快速且生物学上合理的方式进行分类。R-STDP使我们的网络能够找到特定任务的诊断性特征,从而降低最终识别系统的计算成本。
我们的网络基于Masquelier and Thorpe的模型[40],共有四层。网络的第一层基于其定向边缘的显著性将输入图像转换为脉冲延迟。这个脉冲序列在第二层执行局部池化操作。网络的第三层包括多个网格的IF神经元,它们将接收到的定向边缘信息结合起来,提取复杂的特征。这是我们网络中唯一一个使用R-STDP进行突触可塑性训练的层。调节突触可塑性的信号(奖惩)由第四层提供,在第四层作出网络的决定。我们的网络只使用第三层神经元发出的最早的脉冲信号来做决定,而不使用任何外部分类器。如果它的决定是正确的(不正确的),则会生成一个全局奖励(惩罚)信号。此外,为了提高计算效率,网络中的每个cell只允许每幅图像出现一次脉冲。每个神经元最多出现一个脉冲的动机不仅是计算效率,而且是生物学现实[61, 62]。在没有任何分类的情况下,每个神经元最多只能有一个脉冲,这样的决策使得所提出的方法非常适合硬件实现。
我们做了两个虚拟实验来说明R-STDP的能力。我们发现采用R-STDP的网络比STDP使用更少的计算资源来发现信息特征。我们还发现,如果需要的话,R-STDP可以通过鼓励神经元忘却以前所学到的东西来改变神经元的行为。因此,重用计算资源不再有用。此外,我们使用三个不同的基准,即Caltech face/motorbike(两个类)、ETH-80(八个类)和NORB(五个类),评估了所提出的自然图像目标识别网络。实验结果表明,R-STDP比STDP更能有效地识别特定任务的特征。我们的网络在Caltech face/motorbike上的性能(识别精度)达到了98.9%,在ETH-80上达到了89.5%,在NORB数据集上达到了88.4%。
本文的其余部分安排如下。第二节对提出的网络作了详细说明。然后,在第三节中,给出了实验结果。最后,在第四节中,从不同的角度讨论了所提出的网络,并着重介绍了未来可能的工作。
II. MATERIALS AND METHODS
在这一部分中,我们首先描述了提出的网络结构和每一层的功能。然后我们解释R-STDP,通过它,神经元对一组特定的输入刺激实现增强选择性。最后,我们详细描述了用于评估网络性能的分类策略。
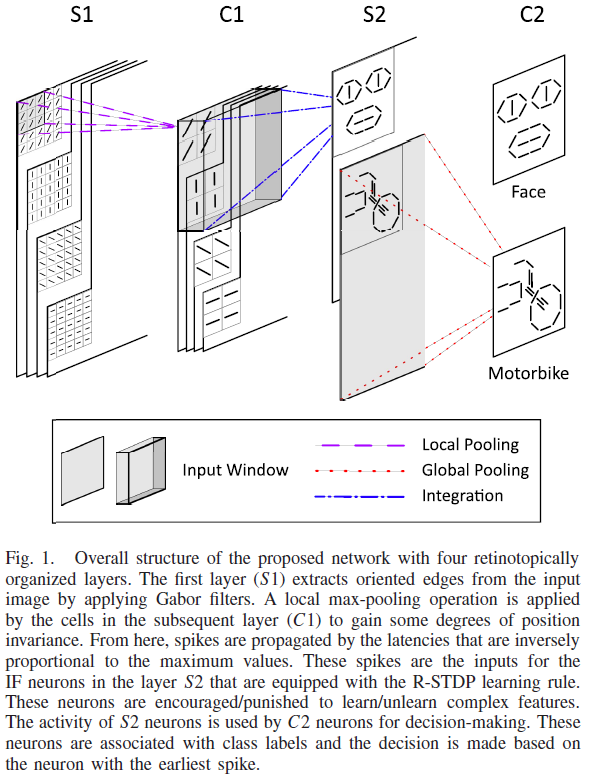
A. Overall Structure
与Masquelier and Thorpe的模型[40]相似,我们的网络由两个简单层和两个复杂层组成,以前馈方式交替排列(见图1)。
网络的第一层(S1)是一个简单的层,其单元检测输入图像中的定向边缘。这些cell发出一个延迟与边缘显著性成反比的脉冲。在S1之后,有一个复杂的层(C1),它通过应用局部池化操作引入了某种程度的位置不变性。C1神经元传播在其输入窗口中最早的脉冲。
第二个简单层(S2)由IF神经元(详解见后)组成。这一层的神经元检测到一个复杂的特征,接收来自C1神经元的输入,并在其膜电位达到阈值时产生一个脉冲。对于突触可塑性,我们使用基于三个因素的学习规则:1)突触前脉冲时间;2)突触后脉冲时间;3)奖惩信号。这种突触可塑性提供了根据神经元对输入模式的选择性来控制其行为的能力。
我们网络的第二个复杂层(C2)是决策层。该层中的每个神经元被分配到一个类别,并对特定网格中的S2神经元执行全局池化操作。使用排序解码方案,首先发放的神经元表示网络对输入图像的决定。根据神经网络的决策,产生奖惩信号,驱动S2神经元的突触可塑性。
网络的实现主要是用C#完成的,代码可以在ModelDB(https://senselab.med.yale.edu/ModelDB/ShowModel?model=240369)上获得。
IF神经元:
硬件模型:IF模型只有一个电容,没有并联的电阻,因为电阻实际等效于泄露电流,对应LIF模型。
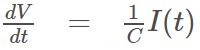
B. Layer S1
该层的目标是从灰度输入图像中提取定向边缘,并将其转化为脉冲延迟。为此,输入图像被四个不同方向的Gabor滤波器(参见https://www.jianshu.com/p/f1d9f2482191)卷积。因此,该层包括4个特征图,每个特征图表示特定优选方向上的边缘显著性。
设I为灰度输入图像,G(θ)表示窗口大小为5×5的Gabor滤波器(卷积核),波长为2.5,有效宽度为2,方向为θ。然后,使用以下公式生成层S1的第 l 个特征图:
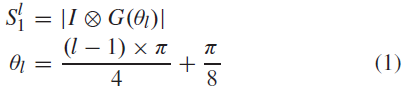
其中⊗是卷积算子,l∈{1,2,3,4}。为了使图像负运算具有不变性,采用卷积的绝对值。此外,由于垂直和水平边缘在自然图像中非常常见,因此应用a(π/8)偏移来放松这种偏差[40]。
对于每个特征图(方向),我们放置一个大小相同的二维网格,其中包含虚拟神经元来传播脉冲。使用强度-延迟编码方案,将获得的特征图转换为与边缘显著性成反比的脉冲延迟。换句话说,边缘越突出,对应的脉冲传播越早。
我们以基于事件的方式实现了所提出的网络,其中脉冲按其延迟的升序排序并按顺序传播(即第一个脉冲在时间步骤t=1中传播,第二个脉冲在t=2中传播,依此类推)。
C. Layer C1
我们的第一个复杂层是来自层S1的脉冲上的局部池化层。这里,有四个二维神经元网格对应于每个方向。在特定网格中的S1神经元上,每个C1神经元用大小为ωc1×ωc1,步长为rc1(这里我们设置rc1=ωc1-1)的窗口执行局部池化操作,然后在接收到其最早的输入脉冲后立即发放脉冲。这种池化操作减少了S1层的冗余,减少了所需神经元的数量,从而提高了计算效率。它还为定向边缘的位置添加了局部不变性。
设Pc1(i)为C1层第 i 个神经元所有突触前神经元的集合。然后,该神经元的发放时间计算如下:![]()
其中![]() 表示Pc1(i)中第 j 个神经元的发放时间。
表示Pc1(i)中第 j 个神经元的发放时间。
此外,还采用了两种侧向抑制机制,有助于网络传播更显著的信息。如果位于第 i 个网格(方向)位置(x,y)的神经元进行发放:1)其他网格位于同一位置的神经元会被阻止发放;2)同一网格中相邻神经元的延迟会增加一个与其欧式距离相关的因子。在我们的实验中,对1到5个像素的距离(浮点距离被截断为整数值)进行抑制,抑制因子分别为15%、12%、10%、7%和5%。
D. Layer S2
该层结合了刚收到的定向边缘信息,将其转化为有意义的复杂特征。这里有n个阈值为T的IF神经元二维网格。每个神经元通过可塑性突触从C1神经元的一个ωs2×ωs2×4窗口接收输入。对于同一个网格的神经元也采用了一种权重分享机制。这种机制提供了在整个空间位置检测特定特征的能力。准确地说,Ps2(i)是与第 i 个神经元对应的所有突触前神经元的集合。然后,该神经元在时间步骤t处的膜电位由以下方程更新:
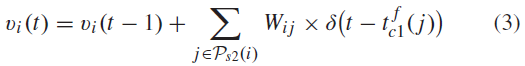
其中Wij表示突触权重,δ表示Kronecker delta函数,![]() 表示C1层第 j 个细胞的发放时间。对于每一幅输入图像,S2中的一个神经元的膜电位达到阈值T。而且,这些神经元没有泄漏,并且在呈现图像时最多可以发放一次。
表示C1层第 j 个细胞的发放时间。对于每一幅输入图像,S2中的一个神经元的膜电位达到阈值T。而且,这些神经元没有泄漏,并且在呈现图像时最多可以发放一次。
当神经元发放时,它们的突触权重——它们所检测到的特征——将根据突触前和突触后的脉冲顺序以及奖惩信号进行更新(见第II-F节)。这个信号来自下一层的活动,它表示网络的决定。此外,突触的初始权重是随机产生的,均值为0.8,标准差为0.05。注意,为均值选择较小或中等范围的值会导致神经元不活动而未被训练。此外,较大的方差值增加了网络初始状态的影响。因此,具有小方差的高均值是合适的选择[46]。
E. Layer C2
这一层正好包含n个神经元,每个神经元被分配到S2神经元网格中的一个。C2神经元只传播从其相应的神经元网格接收到的第一个脉冲。换言之,将Pc2(i)定义为第 i 个神经元网格中的S2神经元集合(对于i∈{1,2,…,n})。然后,第 i 个C2神经元的发放时间计算如下:

其中![]() 表示第S2层第 j 个神经元的发放时间。
表示第S2层第 j 个神经元的发放时间。
如前所述,C2神经元的活动表明了网络的决定。为此,我们将C2神经元分为若干组,并将每组分配给特定类别的输入刺激。然后,假设网络对输入刺激类别的决定是在C2组中最早传播脉冲的组。
假设输入刺激有m个不同的类别,标签从1到m,在S2层有n个神经元网格。因此,在C2层中n个神经元被分成m组。设![]() 表示返回C2神经元的组索引的函数,并令
表示返回C2神经元的组索引的函数,并令![]() 表示第 i 个神经元在C2层的发放时间。然后,网络的决策D由下式定义:
表示第 i 个神经元在C2层的发放时间。然后,网络的决策D由下式定义:
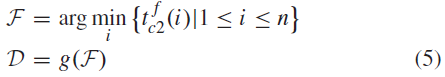
其中F是首先发放的C2神经元的索引。如果网络的决策与输入刺激的正确类别相匹配(不匹配),则它将获得奖励(惩罚)。如果没有一个C2神经元发放,则不会产生奖惩信号,因此不会应用权重变化。此外,如果一个以上的神经元早发放(以最短的脉冲时间),则选择索引(i)最小的神经元。
F. Reward-Modulated STDP
我们提出了一种RL机制来更新S2神经元的突触前权重。这里,权重变化的大小由奖惩信号进行调制,奖惩信号根据网络决策的正确性/不正确性接收。我们还应用了S2神经元之间的一个赢家通吃学习竞赛,其中最早出现脉冲的神经元是赢家,也是唯一一个更新其突触权重的神经元。注意,这个神经元是决定网络决策的神经元。
为了制定我们的R-STDP学习规则,如果接收到奖励信号,那么
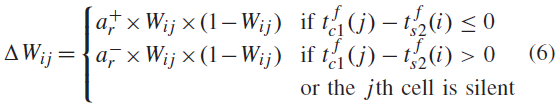
如果收到惩罚信号,我们有下式:
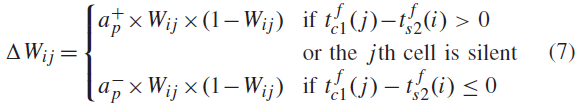
其中 i 和 j 分别指突触后cell和突触前cell,ΔWij是连接两个神经元的突触的权重变化量,![]() 和
和![]() 缩放权重变化的幅度。此外,为了指定权重变化的方向,我们设置
缩放权重变化的幅度。此外,为了指定权重变化的方向,我们设置![]() 和
和![]() 。在这里,我们的学习规则没有考虑确切的脉冲时间差,而是使用一个有限的时间窗口。根据这一学习规则,惩罚信号逆转STDP的极性(也称为anti-STDP)。换言之,它将长期抑制(LTD)与长期增强(LTP)进行交换,这是用来实施厌恶效应(避免重复不良行为),
。在这里,我们的学习规则没有考虑确切的脉冲时间差,而是使用一个有限的时间窗口。根据这一学习规则,惩罚信号逆转STDP的极性(也称为anti-STDP)。换言之,它将长期抑制(LTD)与长期增强(LTP)进行交换,这是用来实施厌恶效应(避免重复不良行为),![]() 是用来鼓励神经元学习其他东西的。
是用来鼓励神经元学习其他东西的。
G. Overfitting Avoidance
在RL问题中,有可能陷入局部最优,或是在训练实例上获得最大可能的奖励。为了帮助该网络,探索其他可能的解决方案,这些解决方案更一般地涵盖已见和未见的例子,我们在训练阶段应用了两种额外的机制。这些技术仅用于对象识别任务。
1) 自适应学习率:由于神经元的初始权重是随机设置的,因此在训练阶段开始时,误分类样本的数量相对较高(即,性能处于chance level)。随着训练试验的进行,正确分类样本与错误分类样本的比率增加。在高误分类率的情况下,网络接收更多的惩罚信号,这会迅速削弱突触的权重,并产生覆盖少量输入的死亡或高选择性神经元。同样,当正确分类率越高,获得奖励的比率也会增加。在这种情况下,网络倾向于通过对正确样本越来越多的选择来排除错误分类的样本,并对其他样本保持沉默。无论哪种情况,过拟合都是由于奖惩的不平衡影响而导致的。
为了解决这个问题,我们用一个调整因子乘以权重修正量,通过这个因子,正确和错误的训练样本的影响在试验中得到平衡。假设网络在每次训练迭代中看到所有训练样本,并让Nhit和Nmiss分别表示在上一次训练迭代中正确和错误分类的样本数。如果N是所有训练样本的数量,则当前训练试验的权重变化修改如下:
 注意,Nhit+Nmiss≤N,因为可能有一些样本在S2神经元上都不活跃。
注意,Nhit+Nmiss≤N,因为可能有一些样本在S2神经元上都不活跃。
2) 随机失活:在RL场景中,学习者的目标是最大化获得奖励的预期价值。在我们的例子中,由于网络只看到训练样本,它可能会发现一些足以正确分类几乎所有训练样本的特征。在面对复杂的问题时,这个问题似乎会导致严重的过拟合,网络更倾向于让一些神经元未经训练。这些神经元在测试样本上降低了网络的命中率,因为它们盲目地发放几乎所有的刺激。
在这里,我们采用了随机失活技术[63],这使得C2神经元以pdrop的概率暂时关闭。这项技术提高了神经元的整体参与率,反过来,这不仅增加了发现更具区分性的特征的机会,而且降低了盲目发放率(见补充材料中的随机失活)。
H. Classification
如前所述,最后一层的活动,特别是C2层最早的脉冲,是我们的网络用于对输入刺激做出最终决定的唯一信息。这样,我们就不需要外部分类器,同时增加了网络的生物学合理性。
为了建立m个类别的分类任务的网络,我们在S2层放置n=k×m个神经元网格,其中k是与每个分类相关的特征数。然后,我们通过关联函数![]() 将每个C2神经元分配到一个类别,定义如下:
将每个C2神经元分配到一个类别,定义如下:
![]()
然后,网络使用(5)对输入刺激进行分类。在训练阶段,将每个网络的决策与刺激标签进行比较,如果决策与标签匹配(不匹配),则生成奖励(惩罚)信号。
I. Comparison of R-STDP and STDP
在目标识别任务中,我们比较了我们的模型,SNN和R-STDP,以及使用STDP的模型。为此,我们首先使用STDP对网络进行训练,并让网络以无监督的方式提取特征。接下来,我们从S2层计算出三种长度为n的特征向量。
- 初次脉冲向量:这是一个二进制向量,其中所有的值都是零,除了一个对应于具有最早脉冲的神经元网格的值。
- 脉冲计数向量:该向量保存每个网格中神经元发放的脉冲总数。
- 电位向量:这个向量包含了忽略阈值的每个网格中神经元之中的最大膜电位。
在为训练集和测试集提取特征向量之后,使用K近邻(KNN)和SVM分类来评估网络的性能。此外,学习策略和STDP公式与文献[40]相同,为了进行公平比较,我们在两个模型中使用相同的参数值。研究STDP的唯一参数是LTP和LTD的幅度。
III. RESULTS
为了评估所提出的网络和学习策略,我们进行了两类实验。首先,我们用一系列手工问题来说明R-STDP相对于STDP的优越性。其次,我们在多个目标识别基准上评估所提出的网络。
A. R-STDP Increases Computational Efficiency
使用STDP,当一个神经元暴露在输入的脉冲模式下时,它倾向于找到最早的重复子模式。通过该模式,神经元达到其阈值并发放[8, 11, 64, 65]。这种有利于早期输入脉冲的倾向在与脉冲模式有时差的后期部分进行区分的情况下,可能是麻烦的。
假设有几类输入刺激具有相同的空间结构[图2(a)]。它们也有相同的早期脉冲。这些模式被重复地呈现给一组IF神经元,其突触可塑性受STDP与赢家通吃机制控制。如果神经元的阈值较低,其中一个神经元会选择输入刺激的早期公共部分,并抑制其他神经元。由于所有输入刺激的早期部分在空间和时间上是相同的,所以其他神经元没有机会发放并赢得突触可塑性。因此,对于所有的输入刺激,神经元群的整体活动是相同的,并将它们归类为一个单一的类别。
我们将在图2(c)中看到,也有一些基于STDP的解决方案,但是,它们在使用计算资源方面是不够的。例如,如果我们增加感受野的大小和阈值,神经元就有机会接收到最后的脉冲和早期的脉冲。另一种可能的解决方案是使用多个局部相互抑制的神经元,去掉一个赢家通吃的约束。这样,对于初始随机权重,神经元就有机会学习输入刺激的其他部分。
在这里,我们证明R-STDP学习规则比STDP更有效地解决了这个问题。为此,我们设计了一个包含两个3×11输入刺激的实验。输入在空间上是相似的,这意味着脉冲从两个输入的相似位置传播。如图2(a)所示,每个输入是由白色和灰色正方形组成的二维网格。用白色(灰色)正方形表示脉冲(不)传播过来的位置。在向网络呈现这些模式中任何一个的时刻,脉冲以时间顺序传播,时间顺序由写在正方形上的数字确定。根据这个顺序,数值越低的脉冲传播越早。
由于输入刺激是人造脉冲模式,因此不需要应用Gabor滤波器,因此,它们被直接输入S2层。在那里,我们放置了两个参数为ωs2=3且T=3的神经元网格。因此,每个网格包含1×9个神经元来覆盖整个输入刺激。
我们还设置![]() 和
和![]() 。这项任务的目标是第一个(第二个)C2神经元在第一个(第二个)模式中更早发放。我们研究了STDP和R-STDP的学习规则,看看网络是否发现了区别性特征。
。这项任务的目标是第一个(第二个)C2神经元在第一个(第二个)模式中更早发放。我们研究了STDP和R-STDP的学习规则,看看网络是否发现了区别性特征。
如图2(b)所示,使用STDP,网络提取了非区别性特征,即两个输入刺激之间的共享特征。另一方面,所提出的RL机制引导神经元提取特征,其出现的时间顺序是导致模式识别成功的唯一因素。我们使用不同的随机初始权重重复这个实验100次。结果表明,我们的网络成功率达98%,而STDP却没有机会发现区别性特征。当我们将阈值增加到4(至少需要两个子模式),并将感受野的大小增加到11×11(覆盖整个模式)时,使用STDP的网络也可以在80%的时间内找到区别性特征[见图2(c)]。

B. Plastic Neurons
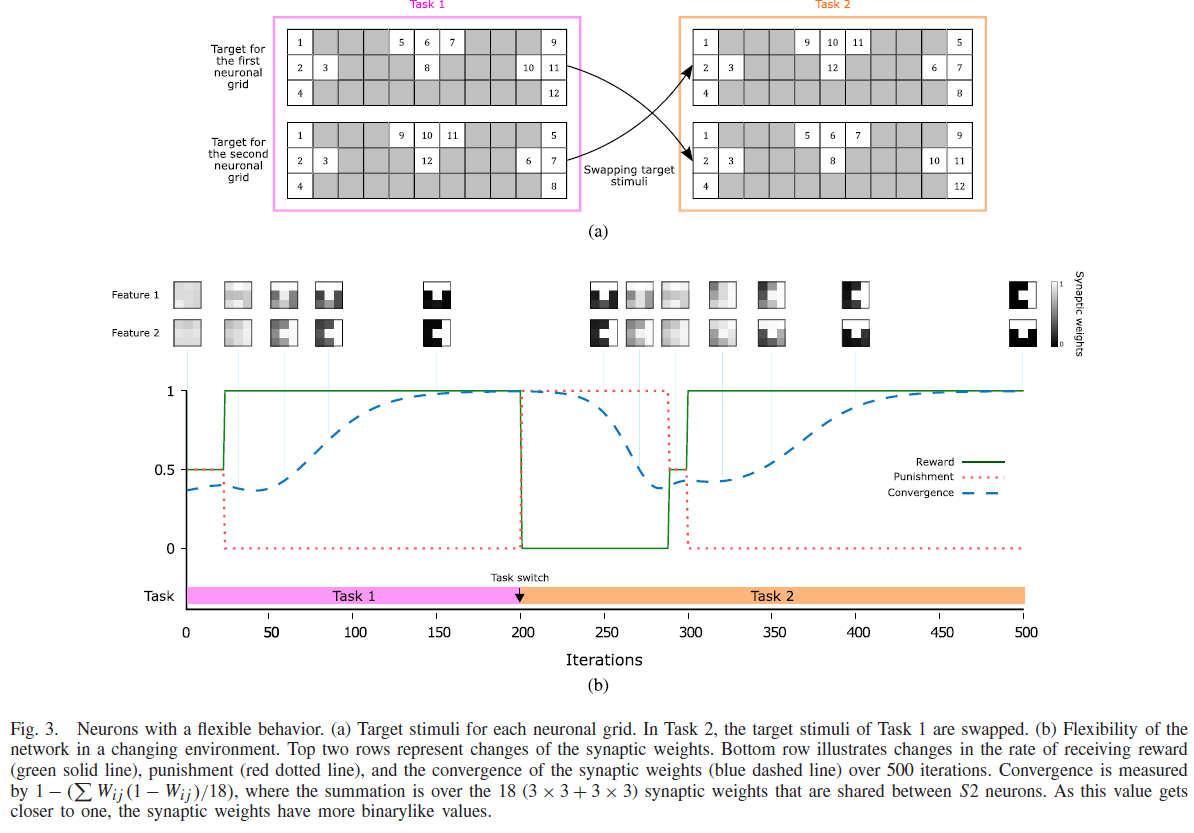
如前所述,大脑奖励系统在特定行为的出现中起着重要作用。在这一节中,我们展示了R-STDP在线调节神经元行为的能力。
我们设计了一个实验,在模拟过程中,神经元预先设定的期望行为会发生改变。实验设置与具有相似输入刺激和参数值的“时间辨别”任务非常相似,只是我们在训练迭代期间交换了目标输入刺激[参见图3(a)中的任务1和2]。如图3(b)所示,在模拟开始时,期望的行为是属于第一个网格的神经元对第一个刺激的反应早于第二个网格的神经元,反之亦然。经过200次迭代后,当充分收敛时,我们交换了目标刺激。在这个阶段,由于神经元对先前的目标刺激完全敏感,它们开始产生假警报。因此,网络在大约80次迭代中(参见图3(b)中第200到280次迭代)接收到高惩罚率,这反过来交换了LTD和LTP(参见第II-F节)。随着神经网络受到惩罚,先前减弱(加强)的突触得以增强(减弱)。因此,敏感度降低了一段时间,神经元重新获得了学习新事物的可能性。经过300次迭代后,神经元发现了新的目标刺激,并再次收敛到区分性特征上(参见图3(b)中前两行的突触权重图)。
总之,R-STDP能使神经元忘却迄今为止所学的知识。这种能力导致神经元具有灵活的行为(可塑性神经元),能够在不断变化的环境中学习有益的行为。这种能力也有助于神经元忘记并逃离局部最优状态,以便学习能获得更多奖励的东西。在这样的场景中应用STDP根本不起作用,因为从无监督的角度来看,任务1和任务2之间没有区别。
C. Object Recognition
在这一部分中,我们评估了我们的网络在自然图像分类方面的性能。我们首先描述实验中使用的数据集。然后,我们展示了如何利用RL机制从自然图像中提取特征,然后在目标识别任务中比较了R-STDP和STDP。最后,我们说明了随机失活和适应性学习技术如何减少训练样本过拟合的机会。
1)数据集:我们使用三个著名的目标识别基准来评估所提出的网络的性能。第一个也是最简单的一个是Caltech face/motorbike,主要用于演示目的。后两个用于评估所提出网络的数据集是ETH-80和small NORB。这些数据集包含来自不同视点的目标图像,这使得任务更加困难(参见补充材料中的图S1)。
2)增强选择性:先前的实验表明,R-STDP使网络能够在空间和时间上发现信息性和区分性特征。在这里,我们证明R-STDP鼓励神经元对特定类别的自然图像具有选择性。为此,我们对网络进行了训练,并对来自Caltech数据集的人脸和摩托车这两类图像进行了测试。
在这个实验中,我们为每一个类别放置了10个神经元网格,为了赢得初次脉冲竞争,这些网格被增强,以响应来自其目标类别的图像。因此,网络的期望行为是前10个网格的神经元对人脸类别有选择性,而其他网格的神经元对摩托车有选择性。
图4展示了网络在训练迭代期间的行为。因为早期的迭代包含了快速的变化,所以它们被绘制得更宽。在早期的迭代过程中,强突触权重(见第II-D节)和50%的随机失活率会导致一个不稳定的网络,其神经元对随机输入刺激作出反应。这种混沌行为在中间图的早期迭代中很容易被发现[见图4(b)]。随着网络不断训练迭代,奖惩信号使神经元对目标类别的选择性越来越强。如图4(b)所示,在200次迭代之后,对训练样本显示出相当健壮的选择性,而在测试样本上,它被延长了300次迭代。训练样本的这种快速收敛是由于网络在发现成功区分所见样本的特征方面相对较快[见图4(a)]。这些主要特性需要收敛到更适合于测试样本的地方,因为自适应学习率的存在,这需要更多的迭代。此外,我们不允许学习率下降到参数![]() 值的20%以下。这允许网络以恒定速率继续收敛,即使所有训练样本都被正确分类[参见图4(c)]。
值的20%以下。这允许网络以恒定速率继续收敛,即使所有训练样本都被正确分类[参见图4(c)]。
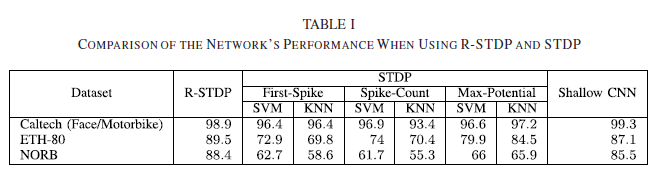
我们用随机的初始权重和不同的训练和测试样本重复了30次实验,所提出的网络的性能达到了98.9±0.4%(均值±标准差)。当我们用STDP尝试相同的网络结构时,97.2%是它最好的成绩(见表一)。

3) 性能:我们已经展示了该网络是如何成功地将摩托车与人脸进行高精度分类的。在这里,我们研究了在更具挑战性的ETH-80和NORB数据集上该网络的性能(见补充材料中的数据集)。在每次训练迭代后,在整个测试集上测试网络的性能,其中网络以随机顺序接收所有训练样本。
对于ETH-80数据集,我们将网络配置为每个类别提取10个特征,导致全部特征数目是8×10=80。S2层中每个神经元的感受野设置为覆盖整个输入图像。在这里,每个类别的9个实例作为训练样本提交给网络,其余的在测试阶段使用。经过250次训练和测试迭代,网络的测试性能达到了最佳。
再次,我们重复这个实验30次,每次使用不同的训练和测试集。如前所述,该网络成功地提取了区分性特征(参见补充材料中的图2),并且达到了89.5±1.9%(均值±标准差)。我们还将STDP应用于具有相同结构的网络。为了检验STDP的性能,我们使用线性核SVM和KNN(K从1变为10)。当最大电位作为特征向量且分类为KNN时,根据计算结果,该网络的精度为84.5%。考虑到所提出的网络仅基于初次脉冲信息对输入模式进行分类,R-STDP的性能优于STDP。表一提供了R-STDP和STDP之间比较的详细情况。
通过查看混淆矩阵[参见补充材料中的图3(a),我们发现R-STDP和STDP都同意最易混淆的类别,即牛、狗和马。然而,由于RL,R-STDP不仅降低了混淆误差,而且提供了更均衡的误差分布。
同样的实验也在NORB数据集上进行。同样,我们为五个类别中的每一个放置了10个神经元网格,它们的神经元能够看到整个传入的刺激。用R-STDP构建的网络在测试样本上的性能达到88.4±0.5%(均值±标准差),而STDP最多达到66%。通过回顾两种方法的混淆矩阵,我们发现这两种网络都遇到了困难,主要是在区分四条腿的动物和人类,以及汽车和卡车[参见补充材料中的图3(b)]。和以前一样,R-STDP产生了更均衡的误差分布。
此外,我们还将提出的网络与卷积神经网络(CNN)进行了比较。尽管所提出的网络不能打败VGG16[66]等预训练的深度CNN(DCNN)(见补充材料中与深度卷积神经网络的比较),但将其与具有类似网络结构和相同输入的浅层CNN进行比较是公平的。我们使用一个浅层CNN重复了所有的目标分类实验,这个CNN以Keras神经网络API和Tensor flow作为后端。如表1所示,所提出的网络在ETH-80和NORB数据集上均成功地优于监督CNN。
4) 过拟合问题:过拟合是监督或RL场景中最常见的问题之一。随着深度学习算法的出现,这个问题变得更加严重。许多研究集中在开发提高学习算法泛化能力的技术上。在深度神经网络中显示出有希望的经验结果的机制之一是随机失活技术[63]。这项技术通过抑制特定数量神经元的活动,暂时降低了网络的复杂性。这种神经元资源的减少迫使网络进行更多的泛化,以减少预测误差。
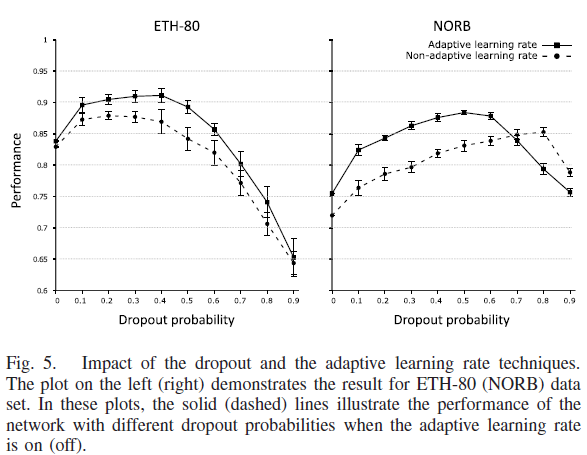
所提出的网络也不例外,而且通过我们的测试,已经显示出对训练样本的过拟合的趋势。因此,我们在实验中采用了随机失活技术。我们还发现,稳定的学习率确实会增加过拟合的机会。因此,我们使用了与网络性能相关的动态学习率(见第II-G节)。
为了说明上述机制的影响,我们以不同的随机失活率和稳定的学习率重复了目标识别实验。图5同时展示了上述两种机制对测试样本分类的影响。很明显,当采用自适应学习率机制时,网络取得了更高的性能(实线)。文中还指出,必须根据数据集和网络的复杂性来选择随机失活率。由于NORB数据集包含比ETH-80更复杂的样本,因此它更倾向于对训练样本进行过拟合。因此,它需要更多的随机失活率来克服这个问题。当使用稳定的学习率时,这种趋势的程度更加明显。换言之,更快的收敛速度以及样本的复杂性会导致更高的过拟合,而这反过来又需要更高的随机失活率。
IV. DISCUSSION
哺乳动物对视觉目标的识别速度快且准确。他们的视觉皮层以一种分层的方式处理输入的数据,通过这种方式,神经元偏好的复杂性逐渐增加。这种层次化处理提供了一种稳健和不变的目标识别[67–71]。哺乳动物视皮层的计算模型研究已经有很多年了。开发一个生物学上合理的模型不仅使科学家能够以低成本检验他们的假设,而且还为人工智能机器提供了一个类似人类的视野[40, 72, 75]。
DCNN是这方面最成功的工作[63, 66, 76–78]。这些网络背后的想法受到视觉皮层层次结构的启发。尽管DCNN取得了很有希望的结果,但由于使用了监督学习规则,它们在生物学上并不合理。此外,它们采用基于脉冲的编码方案,既消耗能量又消耗资源。还有一组研究试图使用脉冲神经元和无监督STDP学习规则[40, 42, 46, 48, 59]。这些模型在生物学上更为合理,但在准确性方面无法超过DCNN。理论上,SNN比DCNN具有更强的计算能力,但由于其复杂的动态特性和高维的有效参数空间,使得其难以控制。此外,由于大多数模型都是在无监督的情况下接受训练的,因此分类步骤是通过外部分类器或统计方法完成的。
在这里,我们使用一个带有称为R-STDP的RL规则的分层SNN来解决目标识别任务。有几项研究表明,大脑使用RL来解决决策问题[15-18]。因此,对于能够决定输入图像类别的特定类神经元来说,它是一个合适的选择。因此,我们进一步发展了一个更符合生物学原理的模型,该模型能够完全独立地进行视觉分类。所提出的网络功能在时域内,其中的信息是由脉冲时间编码的。输入图像首先用定向Gabor滤波器卷积,然后基于延迟-强度编码方案生成脉冲序列。生成的脉冲随后传播到特征提取层。利用R-STDP,提出的网络利用预先分配给类标签的神经元,成功地找到了特定任务的诊断性特征。换言之,每个神经元被分配到一个先验类,其期望的行为是对属于特定类的实例做出早期响应。为了进一步降低计算成本,神经元被强迫对输入图像进行至多一次的发放,并且其脉冲的延迟被认为是刺激偏好的度量。因此,如果一个神经元比其他神经元更早发放,它就会收到它所偏好的刺激。这种偏好的衡量方法可以作为网络决策的指标。也就是说,当一个属于某个特定类别的神经元更早发放时,网络的决定被认为是该类别。
通过实验,我们从不同角度对R-STDP和STDP进行了比较。我们证明了R-STDP可以节省计算资源。这是由一个手工设计的辨别任务来解释的,在这个任务中,脉冲的顺序是唯一的区分性特征。R-STDP用最少的神经元、突触和阈值解决了这个问题,而STDP需要更多的神经元、突触和阈值。STDP的这个缺点是因为它倾向于发现统计上频繁出现的特征[8-11],而这些特征不一定是诊断性特征。因此,需要使用更多的神经元或更多的突触,以确保最终发现诊断性特征。另一方面,由于R-STDP会通知神经元它们的结果,它们可以使用最少的资源更好地工作。
在展示了R-STDP在发现诊断性特征方面的优势之后,我们研究了如何将其与层次SNN结合起来,以一种生物学上合理的方式解决视觉特征提取和目标分类问题。我们在Caltech face/motorbike、ETH-80和NORB这三个自然图像数据集上评估了所提出的网络和使用STDP的类似网络,以及具有相同结构的CNN。最后两个包含来自不同视角的目标图像,这使得任务更加困难。当我们比较网络的性能时,我们发现R-STDP的性能比STDP和相同结构的CNN强。更有趣的一点是,所提出的网络仅基于初次脉冲就实现了这种优势决策,而对于其他网络,即使是SVM和误差反向传播等强大的分类也没有任何帮助。
为了比较R-STDP和STDP,除了学习率外,两个网络使用相同的参数值(见第II-I节)。然而,可以使用具有更高数量的神经元和调谐阈值的STDP来补偿盲目的无监督特征提取并获得更好的性能[60]。再次,我们得出结论,R-STDP有助于网络更有效地消耗计算资源。
综上所述,提出的网络具有以下突出特点。
- 自然图像中鲁棒的目标识别。
- 每个神经元在每张图像中只允许出现一次脉冲。这导致了能源消耗的大幅减少。
- 决策(分类)使用初次脉冲延迟而不是强大的分类来执行。因此,模型的生物学合理性得到了提高。
- 突触可塑性受RL(R-STDP规则)支配,可以找到支持这一规则的生物学证据[28],并允许提取高度诊断性特征。
我们的网络对于神经形态工程来说可能很有趣[79],因为它在生物学上是合理的,而且对硬件也是友好的。尽管硬件实现和效率不在本文的讨论范围内,但我们认为,基于以下几个原因,可以以节能的方式在硬件中实现所提出的网络。首先,SNN比传统的人工神经网络更适合硬件,因为能耗高的“乘法累加器”单元可以被更节能的“累加器”单元替代。为此,近年来,关于训练深度卷积SNN(DCSNN)[44, 46]和将DCNN转化为DCSNN[80]以及受限DCNN[81-83]的研究引起了人们的兴趣。其次,大多数SNN硬件使用事件驱动的方法,将脉冲视为事件。这样,能量消耗会随着脉冲的数量而增加。因此,通过允许每个神经元最多有一个脉冲,所提出的模型是尽可能有效的。最后,与基于高精度梯度的权重更新给硬件实现带来困难的深度网络中的误差反向传播相比,本文提出的学习规则更适合于在线片上学习。
到目前为止,我们还没有找到其他具有上述特点的工作。提到最近的一次尝试,Gardner et al.[84]试图通过一个配备R-STDP的读出神经元来对泊松分布的脉冲序列进行分类。虽然他们的方法是有效的,但由于其基于时间的编码和目标标签,它不能应用于自然图像。Huerta and Nowotny[85]的另一项相关工作是,作者设计了蘑菇体内RL机制的模型。他们将RL机制应用于一个随机连接的神经元池中,其中有10个读出神经元来对手写数字进行分类。本文在几个方面与他们的工作不同。首先,我们使用基于哺乳动物视觉皮层的层次结构,而他们使用随机连接的神经元。其次,我们使用R-STDP学习规则,而他们使用概率方法来研究突触可塑性。第三,我们的网络输入是自然图像,使用强度-延迟的编码,而他们使用二值编码和人工图像的阈值。
尽管提出的网络的结果明显优于采用带外部分类器的STDP的网络,但它们仍然无法与最先进的深度学习方法竞争。当前方法的一个限制是只使用一个可训练层。此外,最后一层神经元的感受野设置得足够大,足以覆盖图像的信息部分。因此,除非使用越来越多的神经元,否则网络无法抵抗物体的高变化率。扩展现有网络的层数是未来研究的方向之一。通过提供一个从简单到复杂的渐进特征提取,加深层次似乎可以提高性能。然而,更深层次的结构需要更多的参数调整和合适的多层突触可塑性规则。最近的研究也表明,将深度网络和RL结合起来可以得到显著的结果[86, 87]。
未来研究的另一个方向是利用RL学习语义关联。例如,STDP能够从不同的角度提取不同种类动物的特征,但由于不同的动物没有共同出现的理由,因此它不能将所有的特征都归入“动物”的范畴。或者,它可以为正脸和侧脸提取特征,但它不能生成一个关联,将两者都归入“人脸”的一般类别。另一方面,通过强化信号和使用学习规则,如R-STDP,神经元不仅能够提取诊断性特征,而且能够学习类别之间的相对联系,并创建超类。