机器学习的系统设计
确定执行的优先级(这里以垃圾邮箱分类为例子)

如果要我们利用机器学习的知识设计一个垃圾邮箱分类的系统,首先我们就需要明确垃圾邮箱和非垃圾邮箱的区别。这里一般的常见做法就是把垃圾邮箱中容易出现的词汇提取出来,作为识别是否是垃圾邮箱的特征向量。
 于是做完这些工作之后我们就得到了判断是否是垃圾邮箱的特征向量。这里1表示该单词出现在邮箱中,0表示没有出现。这样我们便可以利用所学的逻辑回归和神经网络的方式来对模型进行训练了。
于是做完这些工作之后我们就得到了判断是否是垃圾邮箱的特征向量。这里1表示该单词出现在邮箱中,0表示没有出现。这样我们便可以利用所学的逻辑回归和神经网络的方式来对模型进行训练了。
误差分析
误差的分析有助于我们更好更快地修正模型。例如我们在交叉验证集中有500个邮件,我们的模型分类错了100个,而通过学习曲线的方式我们并没有明显发现过拟合和欠拟合的存在。我们就需要人工检查为什么会出现这么多的错误,把出错的种类都统计出来。
 在这里我们做好了错误统计就可以明显地看出来为什么模型会出错便可以对症下药 了。
在这里我们做好了错误统计就可以明显地看出来为什么模型会出错便可以对症下药 了。
不对称性分类的误差
首先我来解释一下什么叫做不对称性数据(也就是偏斜数据)。例如,我们有一个预测癌症的模型,我们的模型做到了99%的正确率,但是癌症在人群中的出现率仅有0.5%,如果有一种模型一直预测人没有癌症那么它的错误率仅有0.5%.这显然不是我们所想要的效果。于是相比于错误率,我们需要一个更加客观,科学的标志来评判模型的好坏。
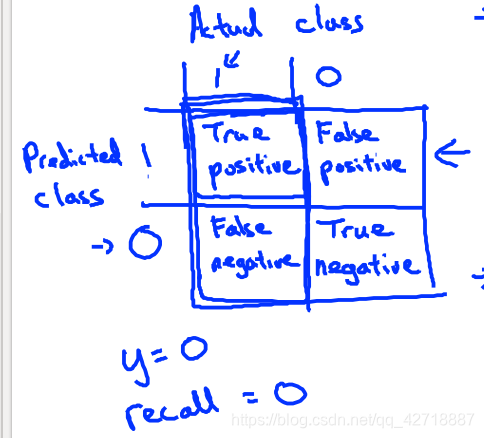
我们先来看看这样一个表格,这里就是真实为1,0以及预测为1,0形成的交叉表格。通过这个表格我们就可以得到精确度和召回率两个概念。
