需求分析:
主要存储第三方的id数据,其中包括各媒体cookie与自身cookie(以下统称supperid)的mapping关系,还包括了supperid的人口标签、移动端id(主要是idfa和imei)的人口标签,以及一些黑名单id、ip等数据。
数据特点:
- 媒体自身的cookie长短不一;
- 需要为全量数据提供服务,supperid是百亿级、媒体映射是千亿级、移动id是几十亿级;
- 每天有十亿级别的mapping关系产生;
- 对于较大时间窗口内可以预判热数据(有一些存留的稳定cookie);
- 对于当前mapping数据无法预判热数据,有很多是新生成的cookie。
存在的技术挑战:
1)长短不一容易造成内存碎片;
2)由于指针大量存在,内存膨胀率比较高,一般在7倍,纯内存存储通病;
3)虽然可以通过cookie的行为预判其热度,但每天新生成的id依然很多(百分比比较敏感,暂不透露);
4)由于服务要求在公网环境(国内公网延迟60ms以下)下100ms以内,所以原则上当天新更新的mapping和人口标签需要全部in memory,而不会让请求落到后端的冷数据;
5)业务方面,所有数据原则上至少保留35天甚至更久;
6)内存至今也比较昂贵,百亿级Key乃至千亿级存储方案势在必行!
解决方案:
5.1 淘汰策略
存储很紧的一个重要原因在于每天会有很多新数据入库,所以及时清理数据尤为重要。主要方法就是发现和保留热数据淘汰冷数据。
5.2 减少膨胀
Hash表空间大小和Key的个数决定了冲突率(或者用负载因子衡量),再合理的范围内,key越多自然hash表空间越大,消耗的内存自然也会很大。再加上大量指针本身是长整型,所以内存存储的膨胀十分可观。
1).如何把key的个数减少。
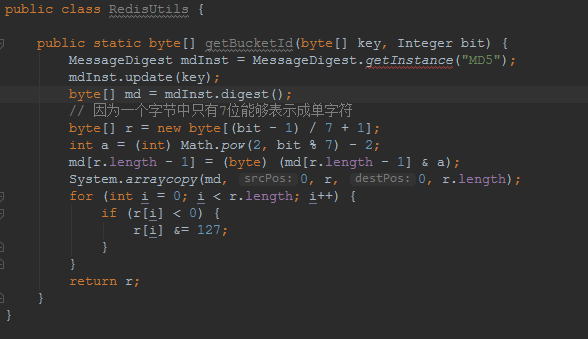
我们希望将key1=>value1存储在redis中。先用固定长度的随机散列md5(key)值作为redis的key,我们称之为BucketId,而将key1=>value1存储在hashmap结构中,这样在查询的时候就可以让client按照上面的过程计算出散列,从而查询到value1。
过程变化简单描述为:get(key1) -> hget(md5(key1), key1) 从而得到value1。
如果我们通过预先计算,让很多key可以在BucketId空间里碰撞,那么可以认为一个BucketId下面挂了多个key。比如平均每个BucketId下面挂10个key,那么理论上我们将会减少超过90%的redis key的个数。
具体实现: