官方writeup:https://github.com/ustclug/hackergame2018-writeups?tdsourcetag=s_pctim_aiomsghttps://github.com/ustclug/hackergame2018-writeups?tdsourcetag=s_pctim_aiomsg
参考:https://github.com/ustclug/hackergame2018-writeups/blob/master/official/mining_pool_of_Z/README.md
http://www.cnblogs.com/yof3ng/p/9797318.html#%E7%8C%AB%E5%92%AA%E5%92%8C%E9%94%AE%E7%9B%98
签到题:

方法一:题目说是要提交 hackergame2018 但是提交时不管怎样会少一个字母,说明题目对提交时的字母长度进行了限制。
之前我想说答案会不会不是 hackergame2018 ,而是它的子串,于是就提交了此字符串的组合
错了,发现每次提交时 地址栏 会变化,所以可以在那里加一个 8

方法二:因为题目是对输入字符串长度进行了限制,所以用 F12 用开发者工具找到相对应的部分,将对长度的限制修改

猫咪问答
社工题,百度搜索
游园会的集章卡片
用ps拼起来,不行的话也可以选择手拼
拼出来的字字体不是很容易辨认,但是给了提示
猫咪键盘
参考:http://www.cnblogs.com/yof3ng/p/9797318.html#%E7%8C%AB%E5%92%AA%E5%92%8C%E9%94%AE%E7%9B%98
https://www.codercto.com/a/32487.html
文件打开是乱码,应该是让我们还原原本的顺序,但从何下手?
我们经过还原,可以从前面的信息知道作者是谁 nicekingwei
去github上找发现有该作者,并根据文件种类为C++在code类别里面找到了源文件
https://github.com/NiceKingWei/enjoyable-lab/blob/10bf1893f8dafa59a92e52b6e2a229e901981cee/cpp-dt/typed_printf.cpp
编译,发现报错
根据提示,使用 g++ -std=c++17 typed_printf.cpp 编译并运行
可以在线:https://wandbox.org/
如果你会的话,也可以人脑编译
Word文档
打开后它是一段维基百科的介绍,从介绍中感觉可能是个压缩包,那就改后缀名,解压
发现 flag.txt ,复制粘贴过去不对,后来才知道每个字母后面有一个 ' ' (就是回车)
(用windows自带的记事本打开就是一行的,默默吐槽)
1 import re 2 data=open("flag.txt").read() 3 res=re.findall(".+",data) 4 str ="".join(res) 5 print(str)
后来看别人的,他们说他们打不开,这个时候你就可以用 winhex 打开,发现文件头是 PK ,那么此文件就是压缩包了
(文件打不开,那么可能就是文件格式错误,毕竟你说它是word那就是word了吗?)
猫咪银行
这题主要是想让同学们了解一些整数溢出的坑
题目的是说原本有 10CTB,通过存款并取出来赚钱,赚够 20CTB去买 flag。但是问题在于有效期就 10 分钟,赚不够 20CTB,取出的时间远远超出 10 分钟。
(这题我不会。。。以下摘自官方)
解法:简单来说,只需要现兑换 TDSU,购买理财产品,购买时精心构造使得时间溢出为负或者是浮点数,而收益非常大即可


直接点击取出

将CTB兑换到 20 个即可
黑曜石浏览器
题目说用黑曜石浏览器打开,google到了官网 https://heicore.com/index.php ,但是下载不了。。。
但我们只能用黑曜石浏览器才能打开,那么怎么办?
可以伪装自己是黑曜石浏览器
但用F12查看源码看不出什么
方法一:
手动输入view-source:https://heicore.com
可以找到判断 User-Agent 的核心逻辑,就是判断 User-Agent 是否为:

User-Agent(UA) 是每个浏览器最大的不同的特征,所以可以猜测题目中的 FLAG.txt 需要我们以这个 UA 来访问。
方法二:
curl https://heicore.com 和查看源代码的效果相同
接下来请看官方解题步骤:https://github.com/ustclug/hackergame2018-writeups/blob/master/official/heicore/README.md
---------接下来整合各方writeup,希望把思路写下来,早日成为大牛---------------
回到过去
我是谁
这一题有两个小题,充满哲学。考察的是客户端错误相应代码和 “递茶”协议。。。
第一题通过在页面上打开开发者工具,查看network(如果什么都没有刷新一下页面)可以看到status code里面有
418 I AM A TEAPOT,正好问我是谁嘛,把TEAPOT填进去,getflag1:
flag{i_canN0t_BReW_c0ffEE!}
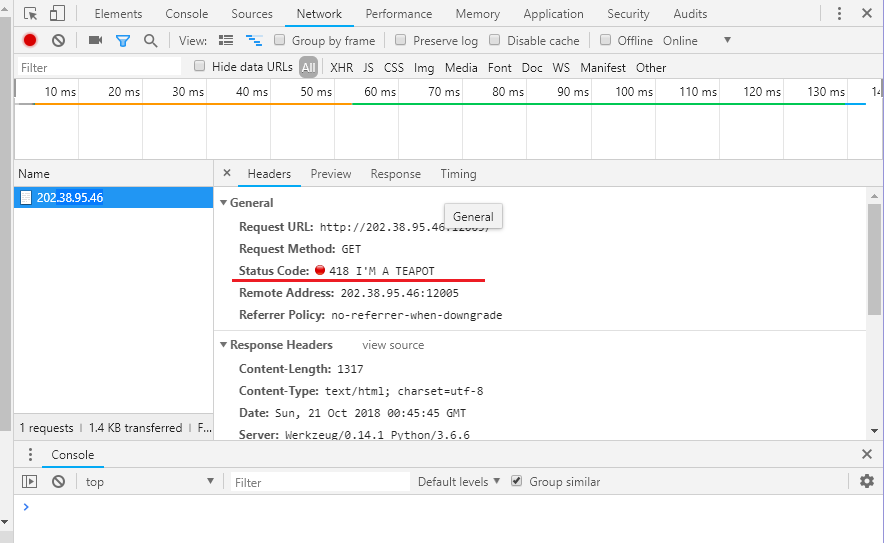
然后可以获取第二小题的链接,简单查看一下,响应如下:
#这年头给大佬递茶都不简单了
Brewing tea is not so easy.
Try using other methods to request this page.
#试试post请求,响应如下:
The method "POST" is deprecated.
See RFC-7168 for more information.
#试试brew请求,响应如下:
Please check if there is anything missing in your header.结合两题的信息 I AM A TEAPOT + brew tea + RFC-7168搜索一下,可以得到说明文档:
https://tools.ietf.org/html/rfc7168
根据文档构造请求header里面的Content-Type: message/teapot,发送过去得到如下信息:
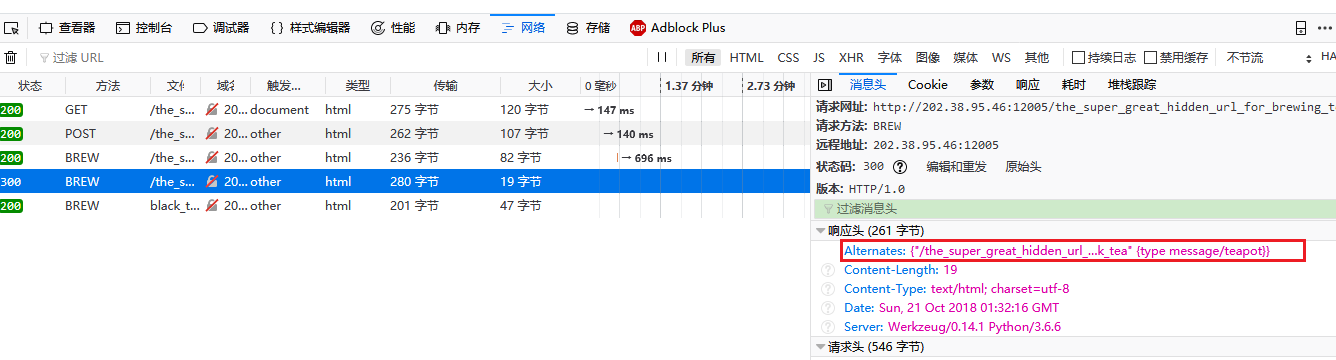
根据返回的信息,我们需要将构造的请求发送到另一个url,即在原url后面加上递茶类型black_tea:
/the_super_great_hidden_url_for_brewing_tea/black_tea
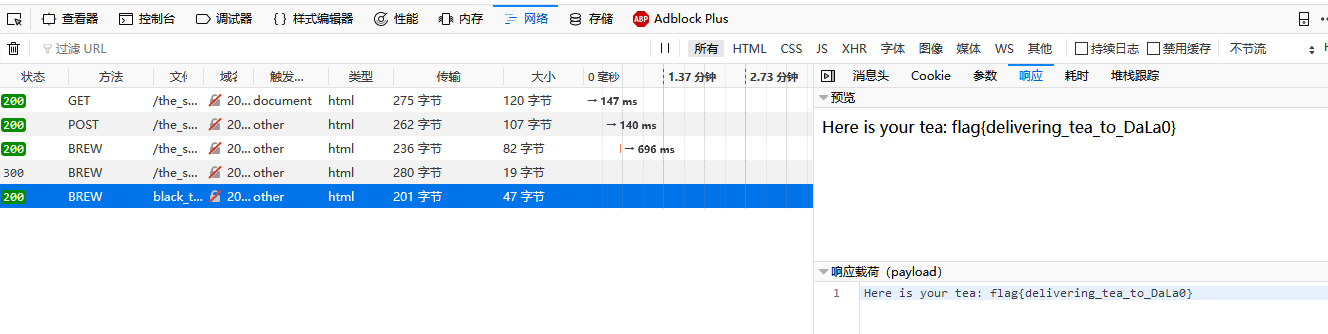
嗯?你说不知道怎么请求?发送特定请求的方式有很多,这道题中可以使用的一种方式是使用 curl 的 -I, -X 和 -H 参数来完成。具体内容可以查看 man curl。用 BurpSuite 等工具,甚至是 Firefox 的开发者工具改请求也都是可以的。
家里有矿
秘籍残篇
滑稽 Art
用fiirefox打开,将页面缩到30%,就可以看到一个畸变的图片

flxg{University_of_Ridiculous}
猫咪遥控器
根据题目留下来的内容,将行走的轨迹画出来
seq=[] r=open('seq.txt').read() now=[130,1] for i in r: if 'L'==i: seq.append(now) now=[now[0],now[1]-1] if 'R'==i: seq.append(now) now=[now[0],now[1]+1] if 'D'==i: seq.append(now) now=[now[0]-1,now[1]] if 'U'==i: seq.append(now) now=[now[0]+1,now[1]] op='' for y in range(550): for x in range(130): if [x,y] in seq: op+='A' else: op+=' ' op+=' ' print op
用turtle库
coding=utf-8
import turtle as T
with open('seq.txt','r') as f:
strings = f.read()
#print(strings)
t=T.Turtle()
t.speed(10)
T.screensize(canvwidth=1300, canvheight=800)
for i in strings:
if (i=='U'):
# 默认方向向右,此命令为前进方向的角度变化
t.seth(90)
#前进一步
t.fd(1)
elif(i=="D"):
t.seth(270)
t.fd(1)
elif(i=="L"):
t.seth(180)
t.fd(1)
elif(i=="R"):
t.seth(0)
t.fd(1)
#下面这一行是窗口运行后不会自动关闭
t.screen.mainloop()
Flag: flag{MeowMeow}
她的诗
https://blog.csdn.net/qq_38412357/article/details/83092575
有一个文件下意识的就运行它,但是题目说了
「我要提醒一下你,只纠结于字面意思是很费劲的,而且……你不会得到任何有用的结论。」
所以运行出的文件并没有什么用
helper.py 里面的 begin 666 <data> 是什么?搜索引擎可以很快告诉你,这是 uuencoding 编码。可以看到,这个脚本将文件的每一行当作一个被 uuencoding 编码后的文件进行解码。如果你去试一下,会发现一大部分明文行重新编码之后获得的字符串和原文件在末尾的地方不一样。那么很明显,这里有问题。
Uuencoding 编码的结构是这样的:
<length character><formatted characters><newline>
第一个是长度字符,通过长度 + 32,再转成 ASCII 的方式出现(比如说,有 3 个字符,就是 chr(3 + 32),即 #)。之后每三个字节(字符)为一组,以如下的方式编码:

(摘自维基百科对应页面)
但不是每一行的字符都是 3 的倍数,那么如果最后一组没法填充的话(即长度乘 4 模 3 不为 0),那么对应部分就会填 0。那么我们想要隐藏的东西能不能就这样塞在填 0 的部分里面呢?答案当然是可以的,不然就没有这道题目了。
获得 flag 的做法中其中一种是一行一行用位运算的方式把 flag 的每个比特拼起来;另一种特定于这道题的方式是:直接扩大每行第一个长度字符到正确的值,具体的原因见下。
from codecs import decode
lines = open("poem.txt", "r").readlines()
flag=''
for i in lines:
i=i[:-1]
j=1
s=''
while True:
a=i[j:j+4]
if len(a)<=0: break
a=a.ljust(4,' ')
b=chr((((ord(a[0])-32)<<2)&0xff)+((ord(a[1])-32)>>4))
c=chr((((ord(a[1])-32)<<4)&0xff)+((ord(a[2])-32)>>2))
d=chr((((ord(a[2])-32)<<6)&0xff)+(ord(a[3])-32))
s+=b+c+d
j+=4
data = "begin 666 <data>
" + i + "
end
"
decode_data = decode(data.encode("ascii"), "uu").decode("ascii")
flag+=s[len(decode_data):]
print (flag)
Flag: flag{STegAn0grAPhy_w1tH_uUeNc0DE_I5_50_fun}
猫咪克星
https://blog.csdn.net/y_kolafish_y/article/details/83038485