啥是hive?为啥学习它?
Hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供类SQL查询功能。
因为直接使用MapReduce实现复杂查询逻辑开发难度格外的大,使用Hive能够使用类SQL语法,提供效率。
有这么些个特点:可扩展(自由扩展规模),可延展(支持自定义函数),有容错(节点有问题SQL仍可工作)
Hive与Hadoop关系 -------> Hive利用HDFS存储数据,利用MapReduce查询数据

Hive与传统数据库有什么区别?(自我感觉最大的区别是Hive能处理大量数据,但是执行很慢)
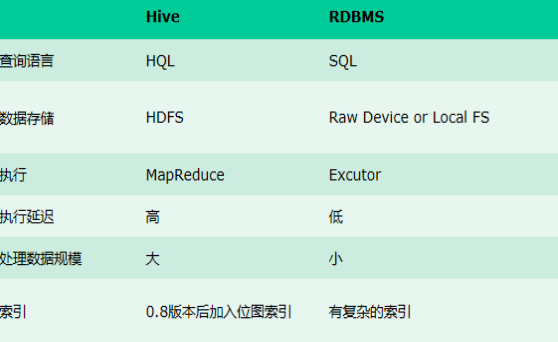
区别:hive是类sql语言,存储在Hadoop上;不支持对数据的改写和添加;没有建立索引,具有高延迟;通过MapReduce执行;可扩展性与Hadoop一致,很高;支持大规模数据。
详细区别可以看这篇文章 -----------> Hive 和sql数据库区别
1.安装hive(元数据库版)
(Hive只在一个节点上安装即可,安装hive的机器必须要安装hadoop,hadoop可以不运行,但是必须安装,hive的执行依赖hadoop的jar包)
1.上传hive
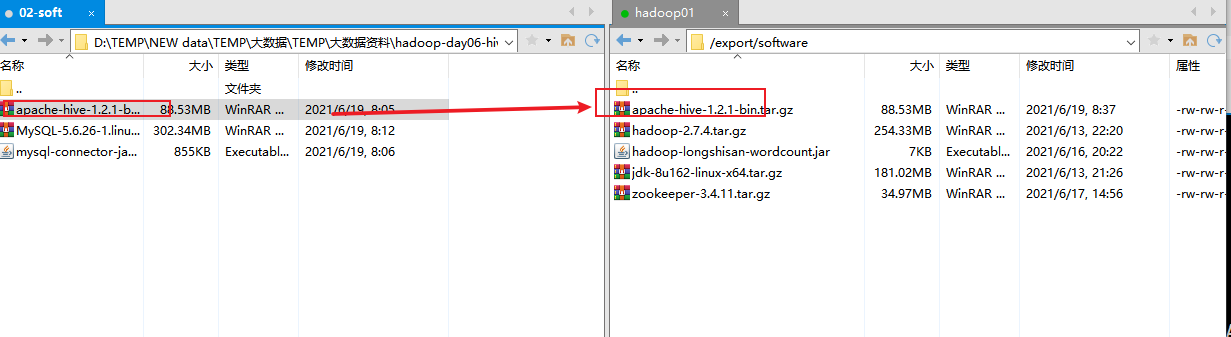
2.解压 输入;tar -zxvf apache-hive-1.2.1-bin.tar.gz -C /export/servers/

3.安装MySQL数据库 (装哪里没关系,只要能联通hadoop集群节点就好)
首先看看有没有冲突 输入:rpm -qa | grep mysql

发现有冲突,删除它 输入:rpm -e mysql-libs-5.1.73-5.el6_6.x86_64 --nodeps
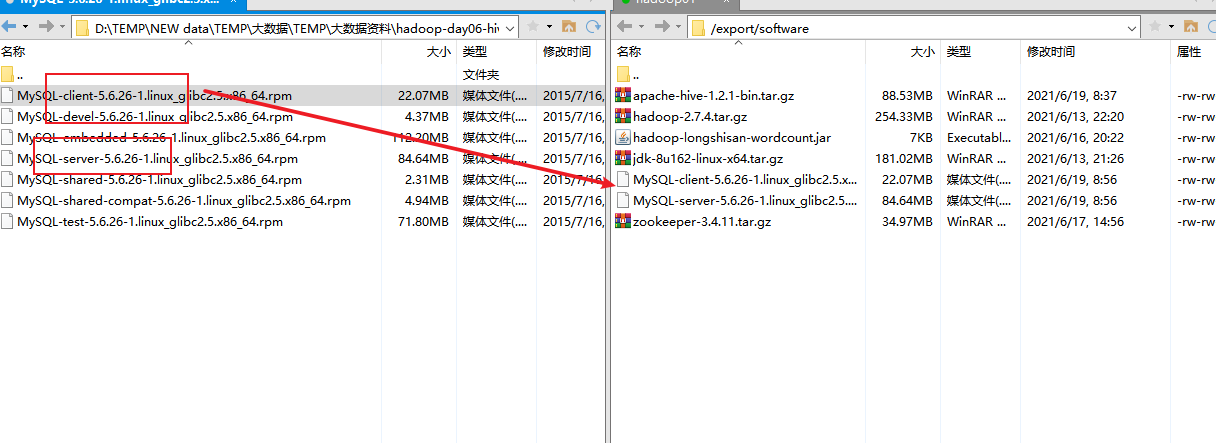
导入包
4.安装server 输入: 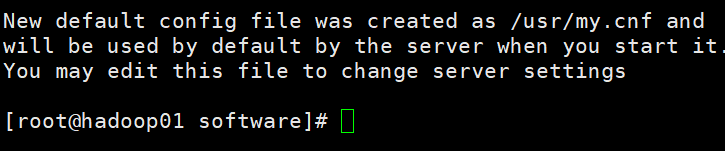

查看密码

启动mysql

5.安装客户端 输入:rpm -ivh MySQL-client-5.6.26-1.linux_glibc2.5.x86_64.rpm

用初始密码登陆 输入:mysql -uroot -pZDjxi2FzziHtlrQB
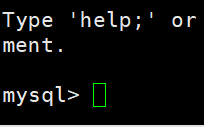
修改密码 输入: set password=password("123456")

2.配置hive
首先进入配置文件目录下

拷贝一份,然后配置环境变量

配置元数据库信息 输入:vim hive-site.xml(如果出现can not open file for write说名)

5.拷贝jar包

拷到虚拟机上还要拷到指定目录 输入:cp mysql-connector-java-5.1.28.jar /export/servers/apache-hive-1.2.1-bin/lib/
之后进入mysql授权,输入:mysql -uroot -p 进去之后输入:GRANT ALL PRIVILEGES ON.TO 'root'@"%"IDENTIFIED BY'123456' WITH GRANT OPTION;

开放localhost连接

解决包版本不一致的问题,进去hive(注意开MySQL)

注:hive启动时,保错cannot access /export/servers/spark/lib/spark-assembly-*.jar: No such file o 修改hive中sparkAssemblyPath,修改为/jars/*.jar 详情看这个 Hive启动时报错
hive的清屏命令 ctrl l 删除表 :hive> drop table if exists 表名;
看一下数据库

6.内部表操作
启动hive 输入:/export/servers/apache-hive-1.2.1-bin/bin/hive
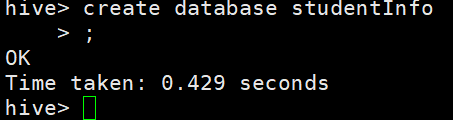
创建数据库 输入:create database studentInfo;
上网页可以看到

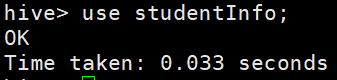
接下来在student这个数据库中建表 输入:use studentInfo;
建表 输入: create table student(Sno int,Sname string,Sex string,Sage int,Sdept string) row format delimited fields terminated by ',' stored as textfile;

create table course(Cno int,Sname string) row format delimited fields terminated by ',' stored as textfile;
create table sc(Sno int,Cno int,Grade int) row format delimited fields terminated by ',' stored as textfile;
(先进库才能show tables)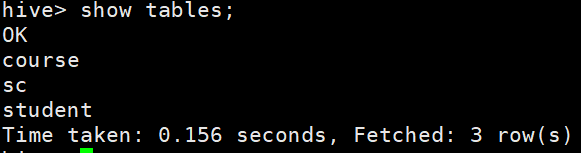
在data下建立个文件夹,在文件夹下导入表


接着去hive下输入:load data local inpath '/export/data/hive/students.txt' overwrite into table student;

同时还有另外两个表 输入:load data local inpath '/export/data/hive/sc.txt' overwrite into table sc;
输入:load data local inpath '/export/data/hive/course.txt' overwrite into table course;


7.开始测试(类SQL语句)(注意要在自己的那个数据库里 use database)
查询全体学生的学号和姓名 输入:select Sno,Sname from student;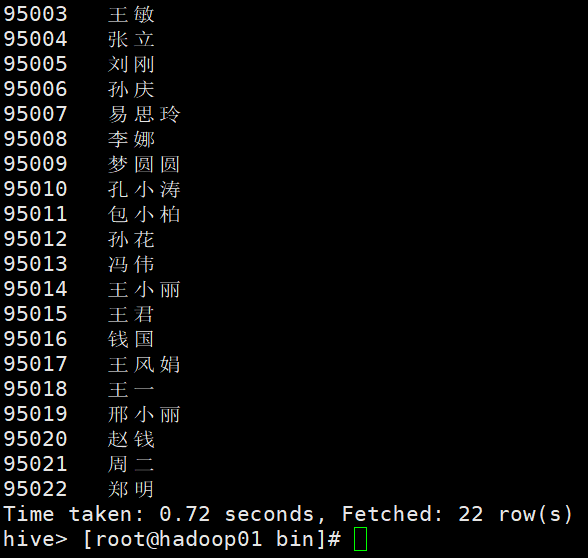
查询选修课程的学生姓名 输入:select distinct Sname from student inner join sc on student.Sno=Sc.Sno (select distinct 用于返回唯一不同的值。inner join内连接)(每一次这种查找都会通过mapreduce进行操作可以看到 )
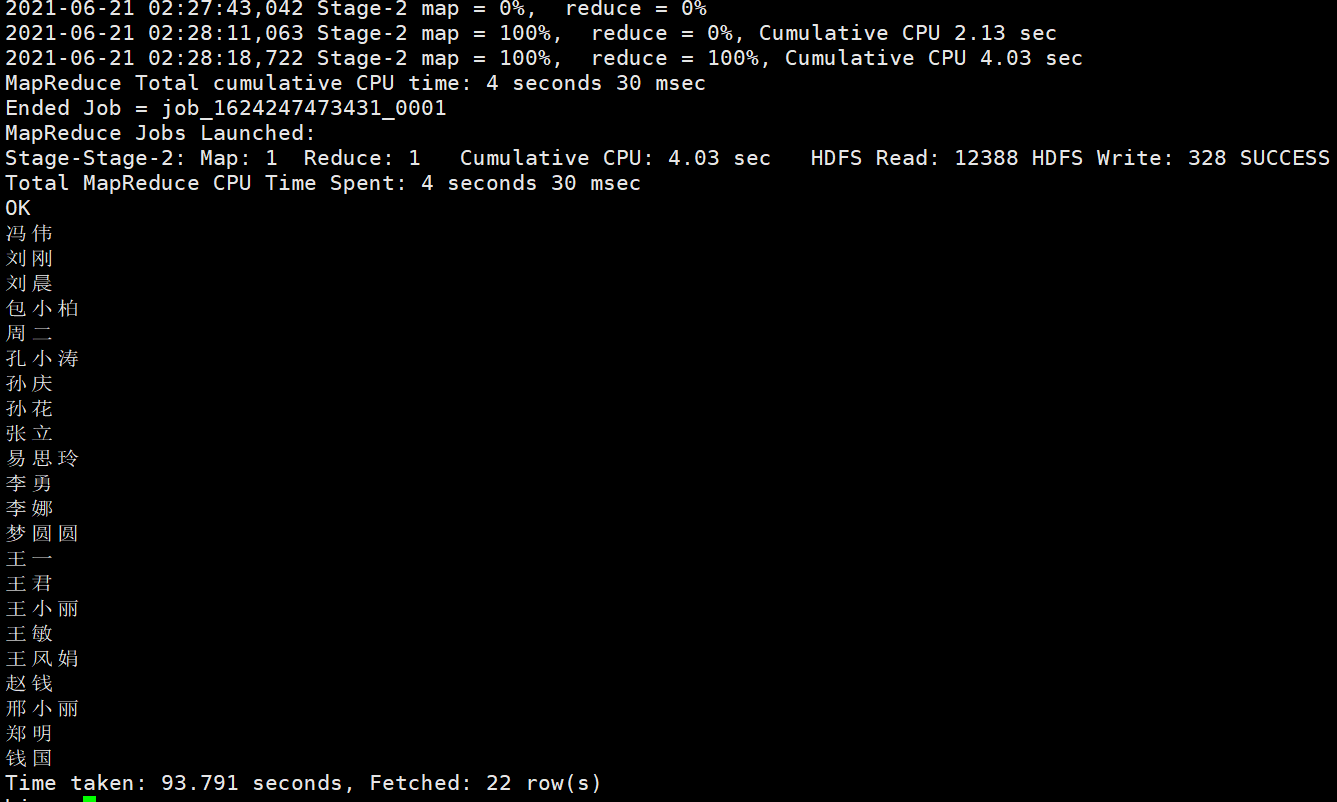
查询学生的总人数 输入:select count(*) from student

计算1好课程的学生平均成绩 hive> select avg(Grade) from sc where Cno=1;

计算各科成绩平均分 select Cno,avg(Grade) from sc group by Cno;
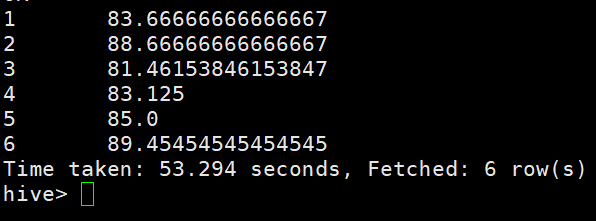
查询选修1号课程的学生最高分数 select Grade from sc where Cno=1 order by Grade;

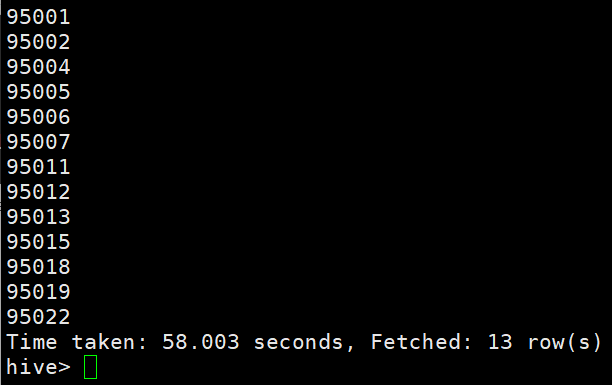
选修了3门以上的课程的学生学号 select Sno from sc group by Sno having count(Cno)>3;
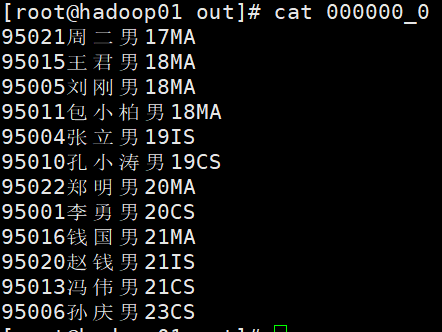
查询学生信息,结果区分别性别按年龄有序 输入:insert overwrite local directory '/home/apps/hadoop-2.7.4/out' select * from student distribute by Sex sort by Sage;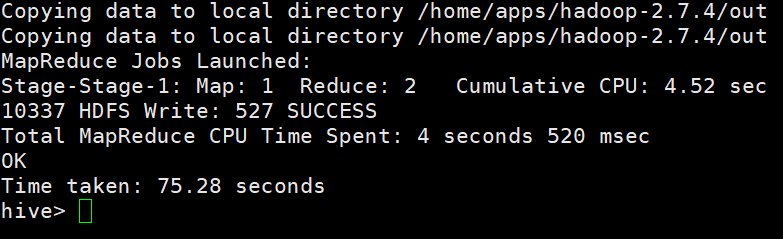
查询每个学生及其选修课程的情况
select student.*,sc.* from student join sc on student.Sno = sc.Sno;
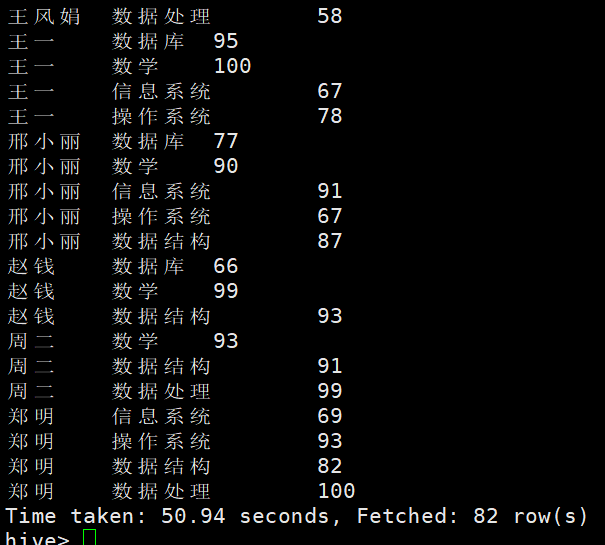
查询学生的得分情况
select student.Sname,course.Sname,sc.Grade from student join sc on student.Sno=sc.Sno join course on sc.cno=course.cno;
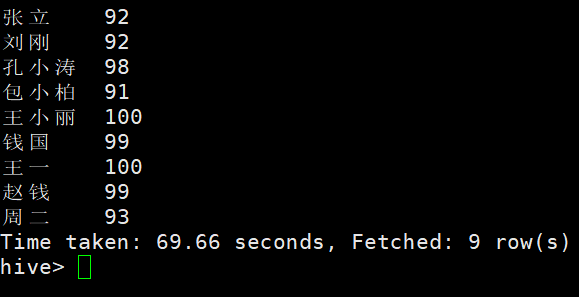
查询选修2号课程且成绩在90分以上的所有学生
select student.Sname,sc.Grade from student join sc on student.Sno=sc.Sno
where sc.Cno=2 and sc.Grade>90;
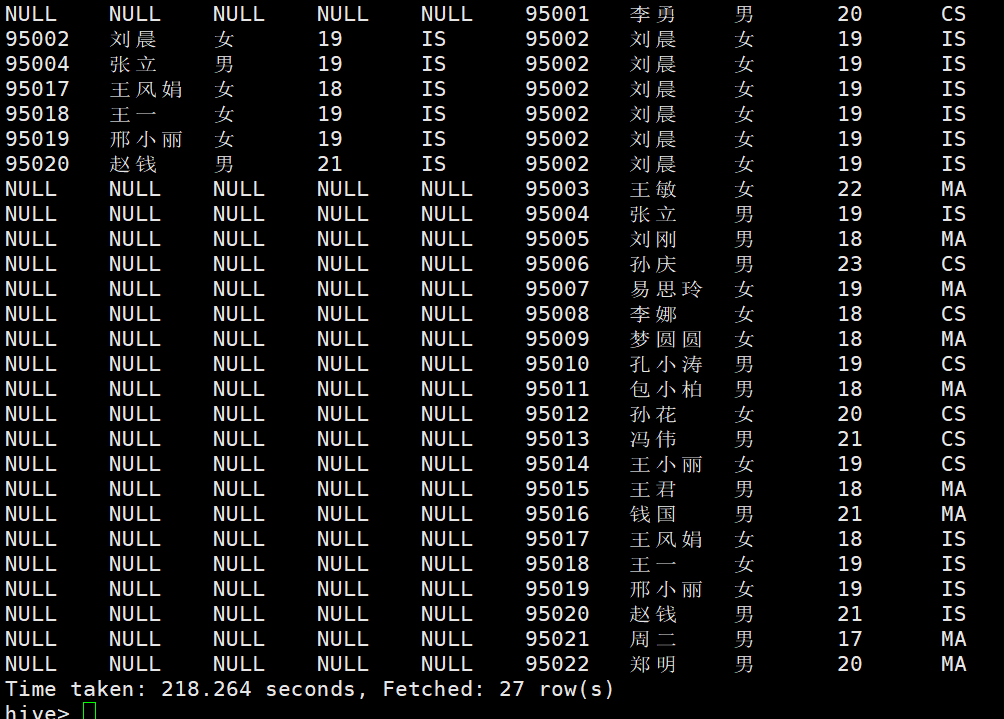
查询所有学生的信息,如果在成绩表中有成绩,则输出成绩表中的课程号
select student.Sname,sc.Cno from student left outer join sc on student.Sno=sc.Sno;
查询与“刘晨”在同一个系学习的学生
select s1.Sname from student s1 left semi join student s2 on s1.Sdept=s2.Sdept and s2.Sname='刘晨';
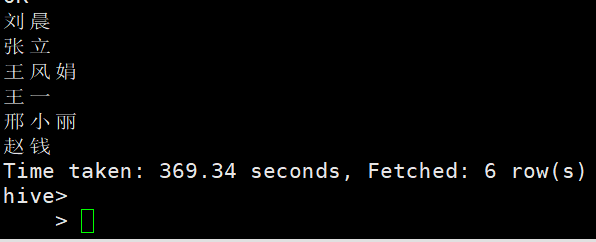

左
右

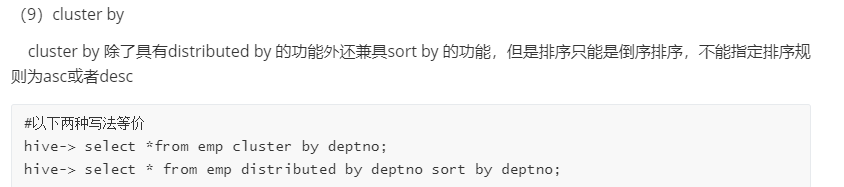
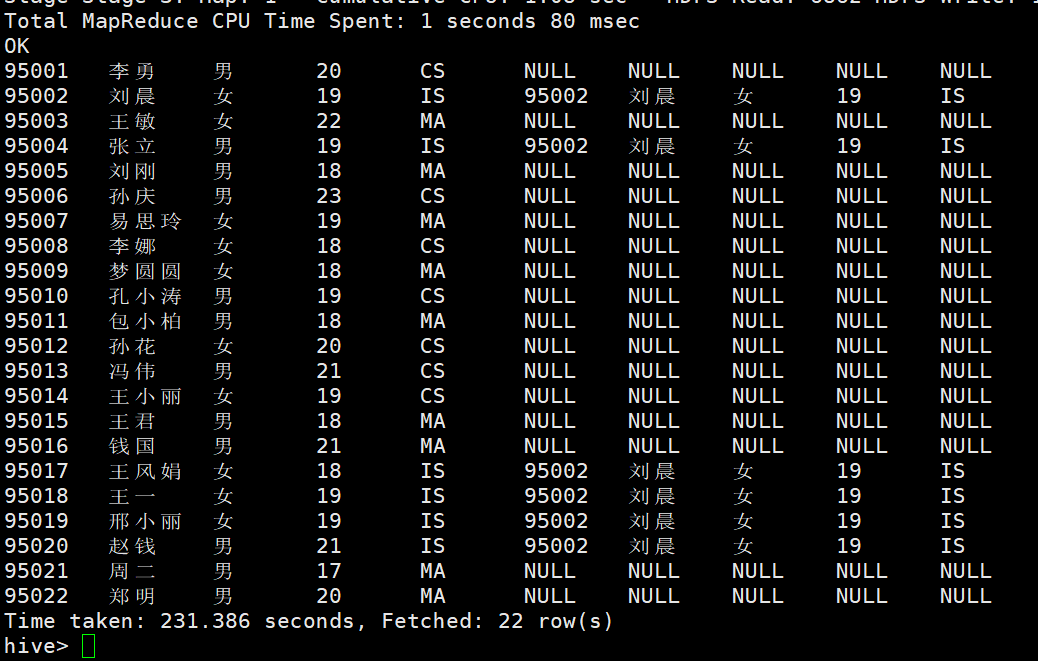
sort by order by distribute by 的区别:
sort By,它通常发生在每一个redcue里,“order by” 和“sort by"的区别在于,前者能给保证输出都是有顺序的,而后者如果有多个reduce的时候只是保证了输出的部分有序。set mapred.reduce.tasks=<number>在sort by可以指定,在用sort by的时候,如果没有指定列,它会随机的分配到不同的reduce里去。distribute by 按照指定的字段对数据进行划分到不同的输出reduce中
此方法会根据性别划分到不同的reduce中 ,然后按年龄排序并输出到不同的文件中
九.外部表操作
1.将student.txt 文件上传到hdfs的/stu目录下,用来模拟生产环境下的数据文件

2.创建一张外部表
create external table student_ext(Sno int,Sname string,Sex string,Sage int,Sdept string) row format delimited fields terminated by ',' location '/stu';
创建了一张外部表,最后和根下的/stu相关联

3.查看数据库中的数据表
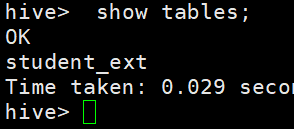
4.查看数据表内容:


十:分区表
1.现在expor/data/hive/user.txt下建立文件

2.创建分区表
create table t_user(id int,name string) partitioned by(country string) row format delimited fields terminated by ',';

3.加载数据是讲数据文件移动到与hive表对应的位置,从本地(linux虚拟机)复制或移动到hdfs的操作,由于分区表在映射数据时不能实用hadoop命令移动文件,需要使用load命令。

4.看一眼,可以看出,分区表与结构化数据完成映射。
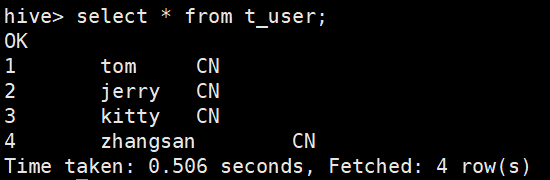
5.再次新增分区


再修改分区,查看情况


动态分区
1.开启动态分区功能 (默认值strict,表示必须指定至少一个静态分区,nonstrict表示允许所有的分区字段都可以使用动态分区。)

2.在建一个新的txt /export/data/hivedata/dynamic_partition_table.txt

3.建表

4.导数据

看一眼

5创建目录表

6.动态插入

7.看一眼(我这里动态插入好像有点问题)

桶表
桶表,是根据某个属性字段把数据分成几个桶,也就是在文件的层面上把数据分开。(这里有问题!)
环境配置,使hive能够识别桶

创建桶表 以学生编号Sno分为4个桶,以','为分隔符的桶表
create table stu_buck(Sno int,Sname string,Sex string,Sage int,Sdept string) clustered by(Sno) into 4 buckets row format delimited fields terminated by ',';

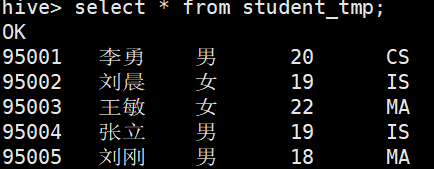
将hdfs的/stu/目录下的结构化文件student.txt 复制到/hivedata 目录下,创建临时的student表,代码如下:
create table student_tmp (Sno int, Sname string,Sex string,Sage int,Sdept string) row format delimited fields terminated by ',';


把student.txt上传,加载数据至student_tmp 表

将数据导入stu_buck 表(额,卡住不动了,查看数据也没有导入进去,兓了)(如果成了就应该能同select*fromstu_buck看到有分布)
语句练习
先建表
建emp表 create table emp(empno int,ename string,job string,mgr int,hiredate string,sal double,comm double,deptno int) row format delimited fields terminated by ' ';
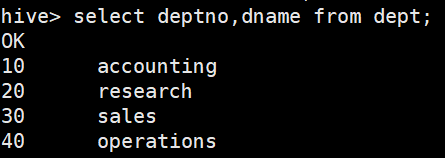
建dept表 create table dept(deptno int,dname string,loc int) row format delimited fields terminated by ' ';
后导文件
load data local inpath '/export/data/hivedata/emp.txt' into table emp;
load data local inpath '/export/data/hivedata/dept.txt' into table dept;
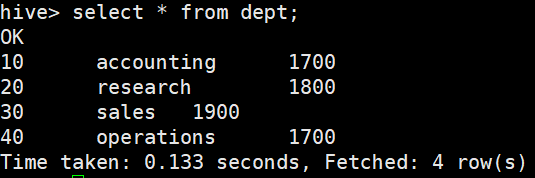
开始操作(导入完后如果发现全是null,那么可能是你分隔符的问题,检查txt文档)
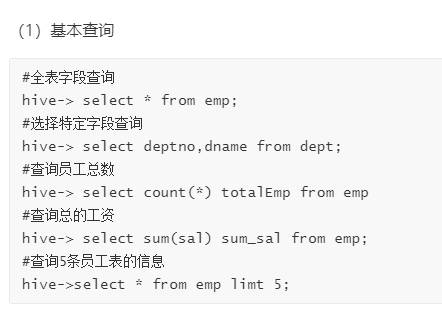
全字段查询
特点字段查询