最近打算写写数据库建模的文章,所以打算分析微软官方提供的SQL Server示例数据库AdventureWorks,看看这个数据库中有哪些值得学习的地方。
首先我们需要下载安装一个SQL Server数据库引擎,然后下载示例数据库,这里笔者用的是SQL2008R2,所以下载的是AdventureWorks2008R2,下载地址:
http://msftdbprodsamples.codeplex.com/
下载数据库后附加到SQL Server中即可看到这个数据库。
这是一个自行车制造和销售公司的数据库,该公司建立自己的销售网站,提供在线销售。首先看看这个数据库的结构,其建立了多个Schema,通过Schema来划分表所在的模块,比如HumanResources,Person,Production,Purchasing和Sales。如果是非常通用的表,比如日志表,那么就不属于任何模块,使用系统默认的Schema:dbo。
对于这么一个复杂的模型,我们可以按照:主要实体、附属实体、事务实体关联关系的顺序进行分析。
主要实体
对于整个系统来说,BusinessEntity是最核心的实体,用于表示一个“人”,这里的人是打引号的,因为它既可以表示真实的自然人,也可以表示:公司、组织甚至一个商店,可以认为是一个法人。对于这个数据库模型来说,有3个实体继承自BusinessEntity,那就是Person,Store,Vendor。
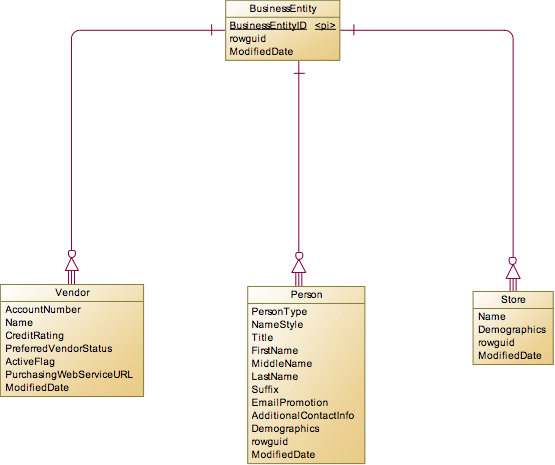
对于Person自然人来说,他可能是公司的员工,也可能是客户,所以我们又关联出了两个实体Employee和Customer。这里需要注意的是,在这个模型中,他并不把一个自然人标识为一个客户,而是对不同的Store,会形成不同的客户。也就是说对于公司来说,他并没有客户主数据,同一个人在不同的店消费,那么就会在不同的店中记为一个客户。为什么要这么设计,确实很奇怪,可能是业务上的需求吧。
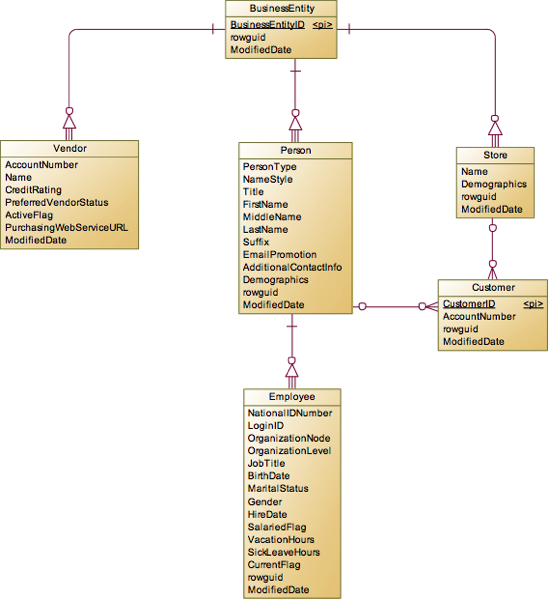
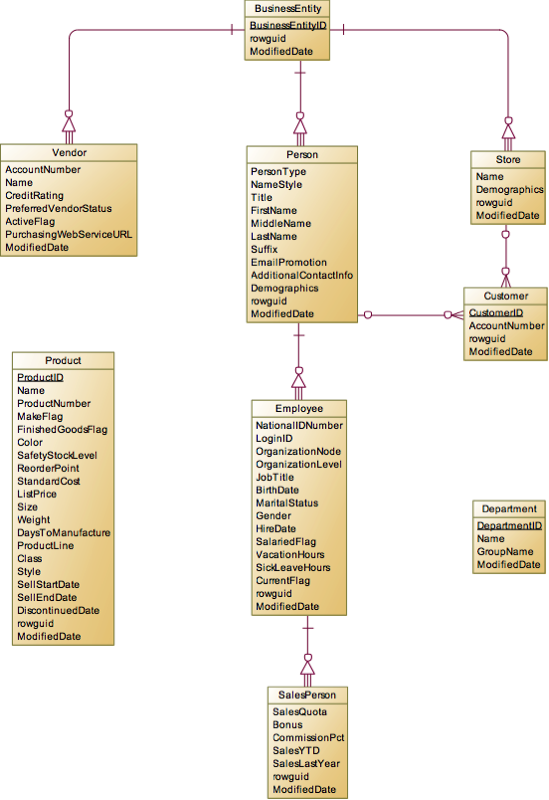
这里延伸到Employee,就可以把HumanResources下面的实体分析一下,很显然Department是主要实体,至于Employee和Department之间的关系,我们接下来再分析,这里我们只找主要实体。Employee如果在销售部门,那么就是一个SalesPerson,所以这个实体是继承自Employee。另外在Production中还有一个很重要的实体Product,用于表示生产和销售的产品。
附属实体
所谓附属实体,就是依附于主要实体而存在,对主实体的属性进行补充的实体,如果主要实体不存在,那么附属实体里面的数据就没有意义。对于前面找的主要实体,我们一个一个的分析:
BusinessEntity
BusinessEntity有两个附属实体:BusinessEntityContact和BusinessEntityAddress,对于联系人实体,是和Person形成多对多关系,所以BusinessEntityContact是多对多产生的中间表,另外再加上ContactType说明联系人的类型。而对于业务实体的地址,系统也抽象出了一个Address表,使得BusinessEntity和Address之间形成多对多关系。
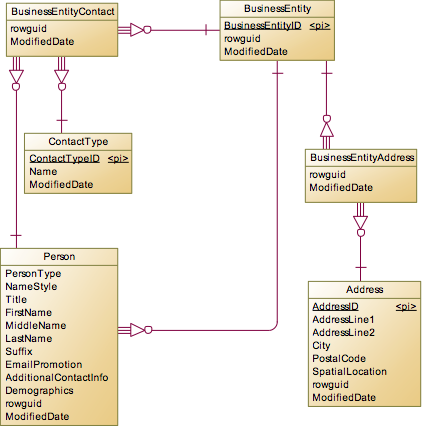
Person
对于Person表,关联的表分为两类,一类是一对多或多对多的普通关联表,比如一个人有多个PersonPhone,一个人有多个EmailAddress,或者一个人持有多张信用卡PersonCreditCard。这里把CreditCard和Person设置成多对多的关系,我想应该这里的CreditCard包含公司商务卡的情况,这种卡的真正持有人是公司,但是公司会派发给Sales用,如果Sales离职了,那么这张卡会收回,派发给其他的员工用,所以这就形成了多对多关系。另外一类是一对一的拆分或继承关系,比如Password表。如果是简单的设计,我们完全可以把Password相关字段放在Person表中,而这里却独立出来形成一对一关系,主要可能是以下几方面的原因:
安全考虑:Password的内容很机密,独立成表后可以单独对这个表进行加密,权限分配等。
性能考虑:Password的内容只用于登录系统时验证,以后接下来的所有查询都用不到这些字段,所以不放在Person表中,系统在查询Person表时就不需要连带着把不需要的字段查出来。
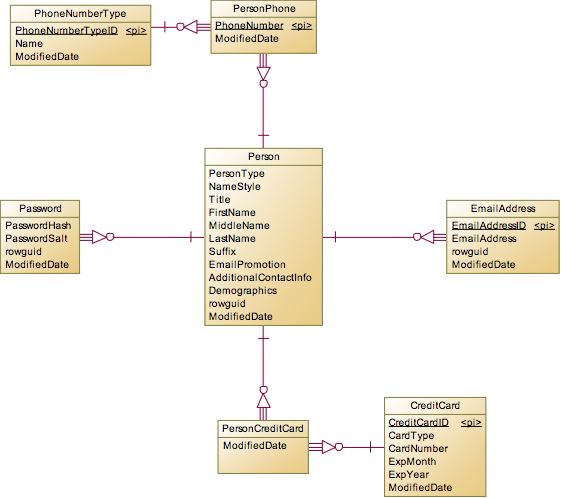
Employee
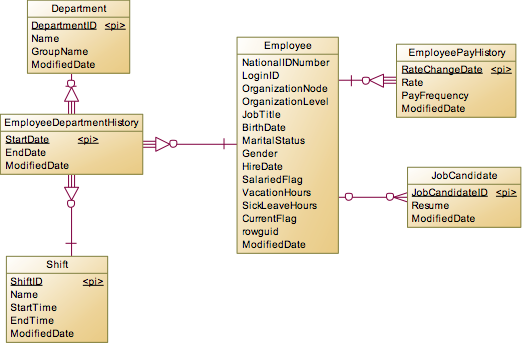
这里主要涉及到的是HumanResources下的表,除了员工的基本信息外还记录了员工的履历,工资变动,部门变动情况。一个Employee对应多个JobCandidate,为什么是一对多关系呢?因为应聘者可以制作个人简历的多个版本,然后投公司的不同部门,最后如果应聘者被录取了,那么就可以把JobCandidate中的BusinessEntityID设置为Employee的ID,如果应聘失败,那么BusinessEntityID就是NULL。EmployeePayHistory是员工的工资表,但是不是发工资的记录表,只是记录员工的工资基本信息,如果工资变动就创建一条新的记录。Employee和Department是多对多的关系,并不是因为一个员工身兼数职,在多个部门同时干活,而是因为要记录员工的部门调动情况,所以保留了所有历史记录,形成了多对多关系。另外比普通公司的部门员工表不同,这个系统还有一个轮班表Shift,那是因为这是个制造业公司也有门店进行销售,所以会分为早班,中班和晚班,一个员工的轮班是固定的,如果发生变化,比如以前是上夜班,现在改为上早班,那么EmployeeDepartmentHistory中也会对应生成一条新的记录。
Sales
销售继承至Employee,主要有销售区域,销售配额等附加的属性。本身销售区域和销售配额可以看做是Sales表的属性,但是为了记录历史,所以独立出来了一对多的表:SalesTerritoryHistory和SalesPersonQuotaHistory。
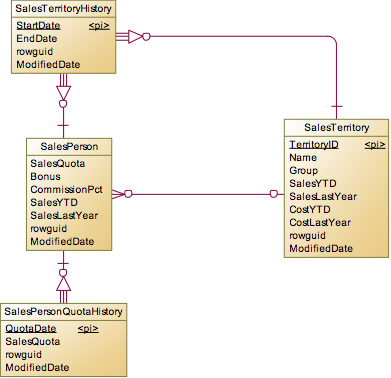
这里需要说明一下SalesTerritory表并不是Sales的附属表,他本身是一个独立的实体。
Product
这个实体应该是各个主实体中属性最复杂的实体了。主要分为ProductModel和Product两块。
先说ProductModel,可以理解为样品,样机或者是模型,在进行量产前需要先生产ProductModel。对于ProductModel,主要有产品的部件关系图Illustration和描述ProductDescription。ProductModel和Illustration是普通的多对多关系,一个模型有多个部件关系图,一个部件关系图也可以用于多个样机中。而对于描述,除了普通的多对多关系外,还增加了一个多语言的关系。于是增加了Culture表,形成了三个表的多对多关系。实际上这种多语言模型并不好,很容易产生错误,对于多语言的处理,可以建立更好的模型。
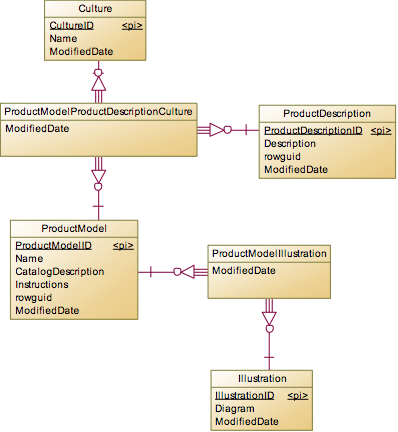
接下来就是Product实体,可以将相关的表分为三类:
多对一:产品的分类Category和前面提到的ProductModel。
一对多:产品成本历史ProductCostHistory,产品的组成BillOfMaterials,产品的库存ProductInventory,产品价格历史ProductListPriceHistory,产品的复查ProductReview。
多对多:产品文档ProductDocument和产品照片ProductPhoto。
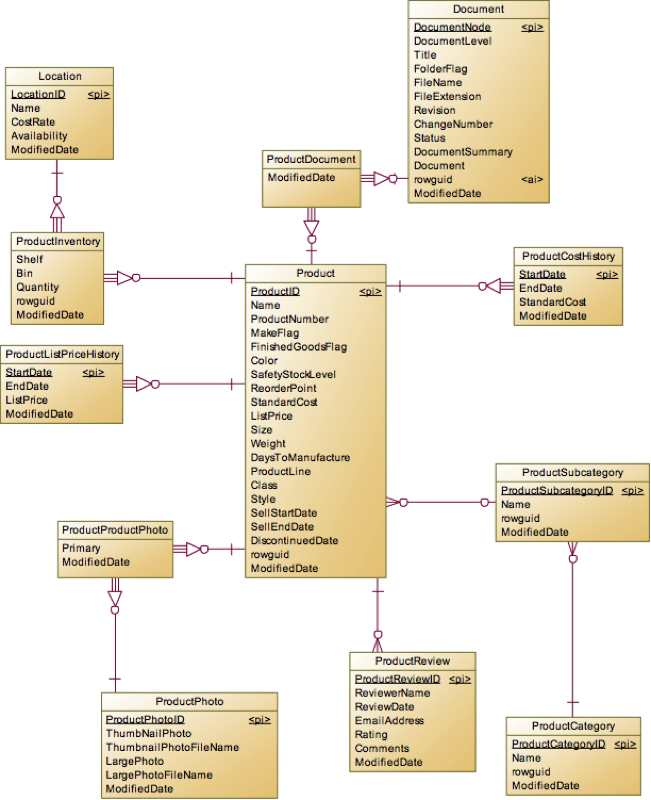
产品分类没啥好说的,就是普通的二级分类法,一级大分类在ProductCategory,二级小分类在ProductSubcategory,然后所有产品都必须归属到二级小分类上。ProductCostHistory和ProductListPriceHistory都是因为要记录基于时间段的历史而形成的一对多关系,其中必有StartDate和EndDate来划分时间区间。【历史数据记录】
关于产品文档和产品照片,由于存在复用的情况(比如产品的外观是一模一样的,只是某些内部参数不一样,那么产品照片就可以复用。)所以就形成了多对多关系,有多对多关系就会有中间表。产品图片由于会有细节照片,各个角度的照片,所以在多对多关系表中另外定义了一个Primary字段用于说明当前选用的照片是不是主体照片。
事务实体
前面分析的实体都是在主谓宾语句中当主语的对象,接下来我们要分析这些主语之间发生关联,进行事务操作后产生的宾语对象。
对于SalesPerson、Product、Customer在一起时,联想到的就是销售订单:
SalesOrder
只要是涉及表单的东西(销售订单、报销单、采购订单、发货单等)大部分情况都会分为Header和ItemDetail两个表,在销售订单中Header用于记录单据的销售的人员,客户,总金额等信息,而ItemDetail中记录了具体销售的产品,数量等信息。
下面先分析Header:
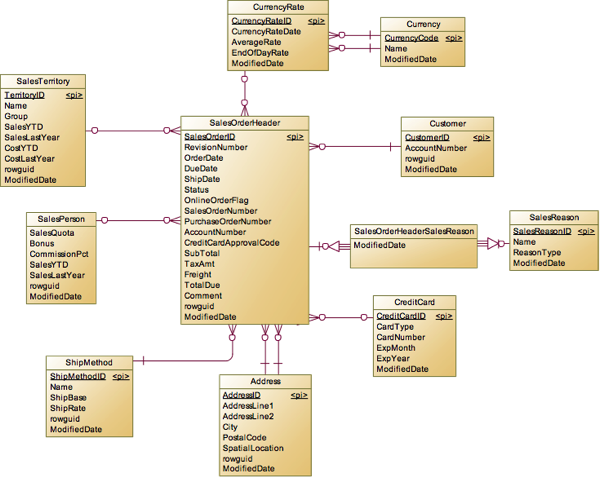
Header建立了SalesPerson与Customer的联系,另外还有范式化的一些字段,比如ShipToAddress,BillToAddress,ShipMethod等。除了这几个实体外,我们需要单独分析一下以下几个实体:
Territory,这是在前面介绍Sales的时候说到,这个销售区域和SalesPerson是有关联的,按理来说,Header表已经关联了SalesPerson表,我们就可以通过SalesPerson获得其下单时对应的Territory,为什么还需要额外添加这个Header到Territory的直接关系呢?这是出于性能的考虑而增加的冗余,对于有时效性的对象,最好是直接关联,而不是通过中间对象jion多个表去关联。让我们看看如果没有直接关联Territory,那么我们的查询到底有多复杂:
select h.*,st.*
from Sales.SalesOrderHeader h
left join Sales.SalesPerson sp
on h.SalesPersonID=sp.BusinessEntityID
left join Sales.SalesTerritoryHistory sth
on sp.BusinessEntityID=sth.BusinessEntityID and h.OrderDate between sth.StartDate and sth.EndDate
left join Sales.SalesTerritory st
on sth.TerritoryID=st.TerritoryID
下面再来看看币种和汇率的相关表Currency。在这个系统中,Header并没有直接说明用什么币种付款,什么币种结算,汇率是多少,而是把这几个字段放在CurrencyRate表中,通过引用CurrencyRate来表示。虽然说独立出来后没有直接放在Header表中直观,不过减少了冗余,只需要做一次Join就能拿到结果,所以性能上还是能接受的。【虽然从关系上需要Join了CurrencyRate后再JoinCurrency表才能完整,但是一般来说Currency表只用于CurrencyRate的限定,而不需要在查询时使用Currency表,因为CurrencyCode是国际标准编码,只需要显示Code就够了。】
Header和SalesReason是多对多关系,在客户下单的时候让用户复选购买原因,是因为促销,还是看了杂志广告之类的,简单多对多关系,这个没啥好说的。
SalesOrderDetail
Header和OrderDetail是一对多关系,Detail记录了具体购买了啥产品,购买单价,数量等,所以关联的是Product,但是在这个系统中,他并不是直接关联Product对象,而是在之间建立了SpecialOfferProduct,该表是Product和SpecialOffer的多对多中间表。
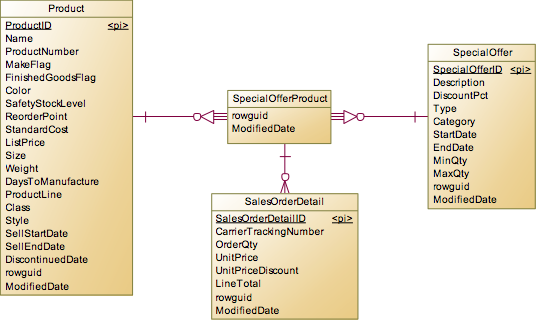
为什么会这么做呢?这主要是跟具体的业务相关。产品在生产出来以后有一个标价Product.ListPrice,但是在实际销售中,商家会有各种促销活动(比如买10个以上9.8折,25个以上9折等),所以会形成Product和SpecialOffer的多对多关系,维护了哪些产品能够有哪些折扣。为了统一模型,如果产品不做任何打折促销,也会在SpecialOffer中维护一条记录“No Discount”。
这里有一个特别的技巧,SpecialOfferProduct是没有自己独立的主键的,而是使用ProductId和SpecialOfferId作为联合主键,然后在OrderDetail引用具体的SpecialOfferProduct时,就会将ProductId和SpecialOfferId引用到其列中。所以在模型上来说,是OrderDetail关联SpecialOfferProduct,然后再关联Product,但是我们在实际查询中,完全可以忽略SpecialOfferProduct表,直接用OrderDetail去Join Product即可,所以性能上没有任何影响,这是一个漂亮的设计。
而当Employee、Product和Vendor在一起时,联想到的就是采购订单:
PurchaseOrder
和销售订单类似,采购订单也 分为PurchaseOrderHeader和PurchaseOrderDetail。
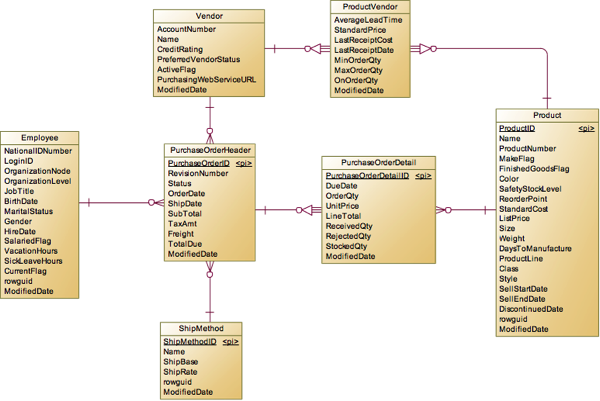
系统中先使用ProductVendor定义了哪些Vendor能供应哪些产品,在生成采购订单时会基于这里面的内容来生成,但是在模型上并不直接反应,因为Product属于Detail表,而Vendor是属于Header表,不能像前面说到的SpecialOfferProduct一样通过引用来传递这种限制。
Header记录的是采购人员Employee与供应商Vendor的关系。一个采购订单Header中会包含多个明细Detail,里面记录了采购哪些Product。采购订单比销售订单简单很多,最为买方,不会去记录促销,购买原因之类的信息。另外采购中没有涉及到币种汇率问题,我估计这是因为产品都在国内采购和结算,所以只有一种币种,而销售是面向世界各地,所以涉及到币种汇率。
WorkOrder
除了前面说到的销售订单和采购订单外,在生产过程中还有生产订单,用于表示产品的生产情况。主要有WorkOrder和WorkOrderRouting两个实体。
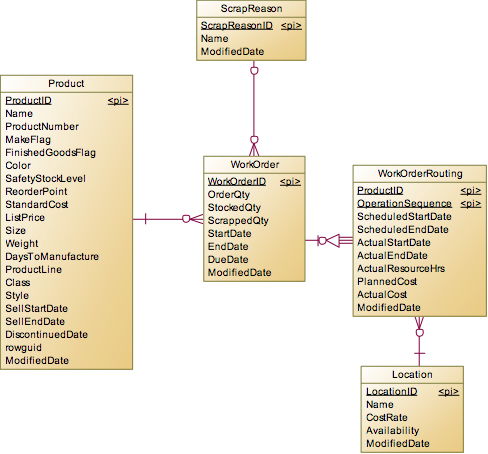
WorkOrder记录了生产某个产品的数量、报废和时间情况,而WorkOrderRouting记录的是在某个产品的具体生产过程中有哪些工序,每个工序的时间、成本等情况。总的来说,这是一个非常非常简化的生产工作订单模型。
其他实体
除了前面说到的实体外,还有其他几个独立出来的实体需要说明一下:
TransactionHistory
另外还有一个其归档表TransactionHistoryArchive,其结构和TransactionHistory一模一样,这里面记录的是生产工作订单或者采购订单或者销售订单这3个事务的产品、日期,数量等公共信息。这个表可以认为是一个事务的日志表,平时并不参与各个实体的查询,只有在审计或者跟踪数据变化时才用到。
TransactionHistory表中的数据是在各个Order表上建立Trigger自动插入进去的,而不是由外部程序代码去控制。由于本身事务表的数据量就比较大,而这个表却存了三个事务表中的数据,所以增长特别快,必须进行归档操作,把老数据搬移到另一个归档表中,这样才能保证查询新TransactionHistory表的速度。
AWBuildVersion
这是一个记录当前数据库定义创建时数据库的版本也可以定义当前数据库定义脚本的版本。对于通用的产品来说,这个表比较重要,因为产品可能需要升级,升级程序在升级前读取这个表,知道了当前数据库定义是什么个版本,然后就可以查询到将当前版本的数据库升级到新版的数据库所需要修改的SQL,然后执行这些SQL。
而应用程序在运行时第一件事就是检查这个表中的版本信息,保证数据库定义的版本与程序要求的版本匹配,这样程序才能正常运行。
对于企业内部系统,一般只有一个实例,而且由企业内部的IT人员开发维护,所以这个表没有也没什么问题。
DatabaseLog
这是记录数据库DDL(数据定义语言,比如CREATE, ALTER, DROP等)操作的日志表。这个表是由Database Trigger自动维护,当在这个数据库中执行了DDL的时候,系统会触发Trigger,往这个表中记录一条数据。这是一个好东西!
另外还有一些因为范式化抽象出来的码表,我在前面的模型中没有提到,比如CountryRegion,StateProvince等这些都比较简单,就不一一累述了。
这篇文章我只是简单分析了下实体和实体关系,下面一篇文章会进一步分析其中的细节,有哪些优缺点。