业务问题
据滴滴介绍2014年使用的Kafka-0.8.2,一个核心业务在使用Kafka的时候,出现了集群数据写入抖动非常严重的情况,经常会有数据写失败。
• 随着业务增长,Topic的数据增多,集群负载增大,性能下降
• 有个文件读写锁bug,会导致副本重新复制,复制的时候有大量的读,我们存储盘用的是机械盘,导致磁盘IO过大,影响写入
发展历程
滴滴初期MQ现状
初期,公司内部没有专门的团队维护消息队列服务,所以消息队列使用方式较多,五花八门很凌乱:
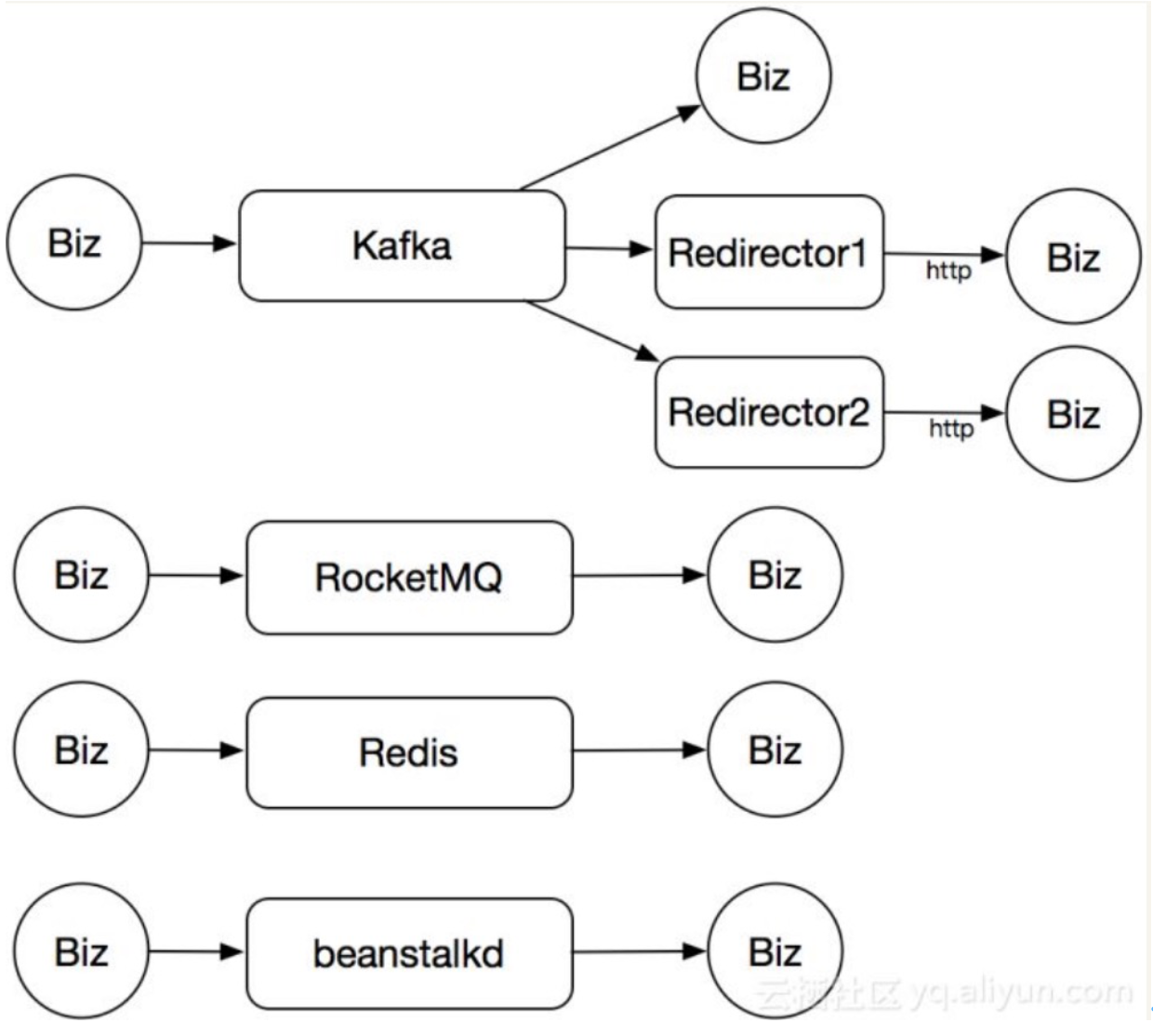
- 主要以Kafka为主,有的业务直连的,也有通过独立的服务转发消息的
- 有一些团队业务用RocketMQ
- 有部分团队业务Redis的list
- 少数业务非主流的beanstalkkd。
因为以上原因,导致的结果就是,比较混乱,无法维护,资源使用也很浪费。以下图表示业务基本使用情况
Kafka前置Proxy服务
Kafka在滴滴属于重度使用,一个topic涉及到的下游业务也就非常多,没办法一次性直接替换Kafka,只能分步骤进行。首先解决业务生产失败问题,为Kafka集群前置增加一个Proxy
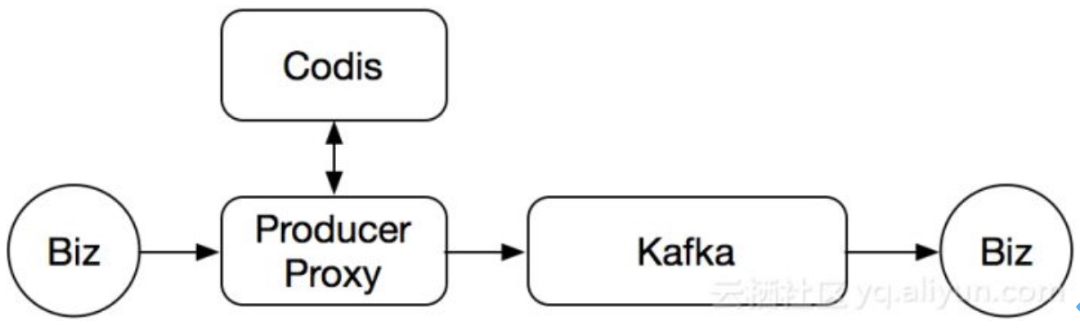
利用codis作为缓存,解决了Kafka不定期写入失败的问题,如上图。当后面的Kafka出现不可写入的时候,我们就会先把数据写入到codis中,然后延时进行重试,直到写成功为止。
Proxy新增消息引擎RocketMQ
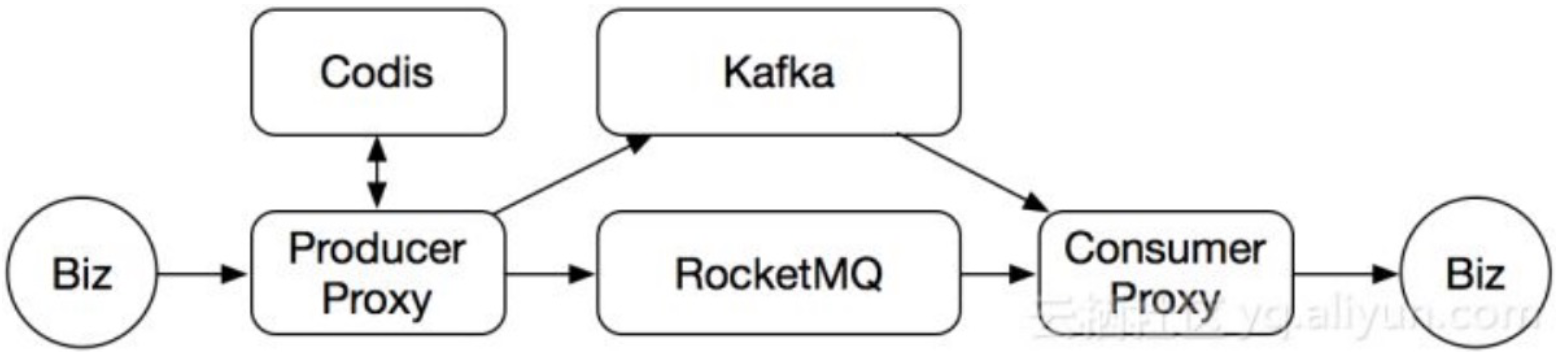
为了支持多语言环境、解决一些迁移和某些业务的特殊需求,新增RocketMQ作为消息引擎,业务端只跟代理层Proxy交互。中间的消息引擎,负责消息的核心存储。后续主要围绕三个方向做深度开发
- 消息队列统一,其他队列迁移到统一消息队列平台上。
- 功能迭代和成本性能上的优化。
- 服务化,业务直接通过管理平台来申请资源,申请审批成功后就可以使用。
滴滴MQ架构
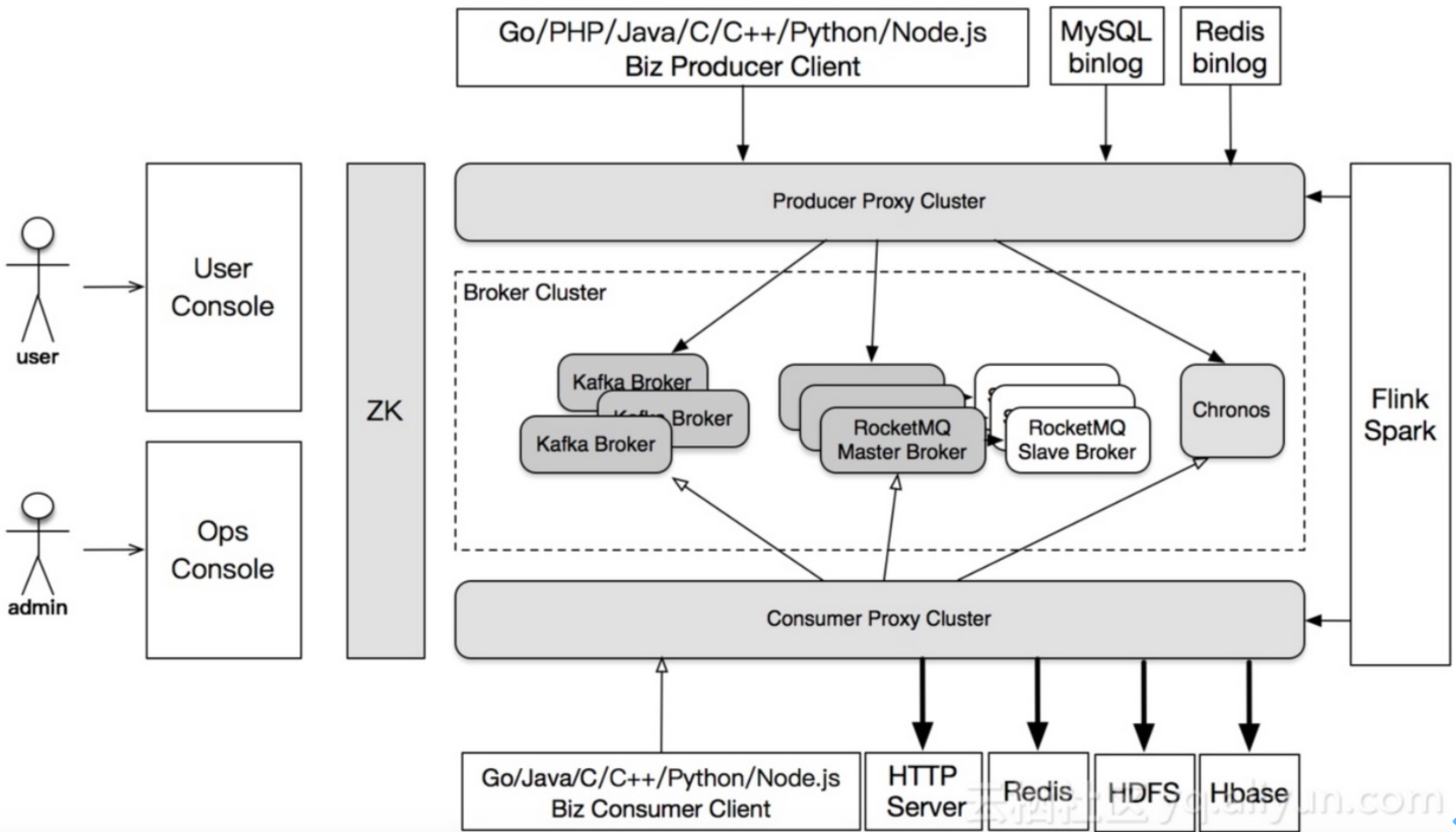
以上是滴滴当前消息队列系统架构,他具有以下特点:
- 支持7种语言客户端
- 其他服务逐步统一迁移到存储引擎RocketMQ上
- 支持多协议,例如HTTP协议RESTfu
- 利用groovy脚本功能可以转存消息到Redis、Hbase和HDFS上
- 与实时计算平台对接,例如Flink,Spark,Storm
- 使用topic要申请审批通过才可使用,填写信息为:Topic,填写各种信息,包括身份信息,消息的峰值流量,消息大小,消息格式等等
- 运维控制台,主要负责我们集群的管理,自动化部署,流量调度,状态显示之类的功能。最后所有运维和用户操作会影响线上的配置,都会通过ZooKeeper进行同步
为什么选择RocketMQ
通过Kafka与RocketMQ进行性能测试比较,结果如下:
- Kafka吞吐受Topic数量的影响特别明显,单机器partitions数量超过2000,超过了越多性能越低。RocketMQ吞吐量比Kafka低30~40%,但不受单机partitions分片数量影响,吞吐性能基本保持稳定不变
- 延迟性比较,同步刷盘方面Kafka延时比RocketMQ高