前言背景
消息系统经过多年使用和运维管理平台开发迭代,能较好支持支撑业务发展,公司主流语言为java,但缺乏一个基于Kafka二次封装简单好用的java客户端。遇到问题如下所示:
- 使用好kafka客户端对业务要求高,非专业技术方向很难有精力全面掌握
- 异常情况会catch不全
- 客户端生产消息及双活机房容灾缺失
- 集群升级难度增加,因为无法全面及时掌握客户端信息(kafka版本、groupid)
- 不支持动态配置更新,业务使用错误及引发的潜在故障无法及时修正,例如Producer写入倾斜导致磁盘报警,参数batch.size当做消息条数使用
设计目标
通过对客户端设计,希望达到如下目标:
- 提供简单好用客户端,对业务进行细节屏蔽掉,暴露出足够简单的接口
- 支持客户端及双活机房容灾
- 热配置支持在线修改灵活的策略和配置优化
- 新功能特性支持(例如:客户端信息采集与上报、消息轨迹跟踪、热配置更新、新增安全性模块、消费失败消息重投递)
系统架构

Kafka管理平台:Apollo配置中心只是负责存储配置信息及接受客户端监听,指令下发是通过Ykafka管理平台进行的。管理员负责维护Ykafka管理平台修改热配置信息,然后同步给Apollo,Apollo推送给相应客户端
Apollo配置中心:所有Kafka集群共用一个分布式Apollo集群配置服务,用于管理所有集群的客户端配置信息,并进行动态更新管理,按照某一维度下发给相应客户端,客户端根据获取的热配置信息,进行相关管理操作。
MetaServer:所有Kafka集群共用对等节点的MetaServer集群服务,主要为存储客户端认证和权限信息,启动时获取认证信息,运行时通过cache来check,存储服务为分布式,避免单点故障。支持热配置启停开关
客户端(Producer和Consumer):客户端启动时不能直接访问Kafka集群,先要请求MetaManager服务,经过授权赋予相应权限资源后,才能访问Kafka集群授权资源。同时客户端通过Apollo监听相应配置,通过自身监听变更获取操作信息
注意事项:Apollo客户端能否优雅兼容多个AppID的问题,目前的结论是,一个客户端只能使用唯一的appId,如何A->B→C服务依次依赖,就会有冲突会被替换掉可能,那如何解决呢?
答曰:官网中关于namespace关联的情况,是通过类似于类继承的方式来实现配置继承的,可以实现配置复用。
客户端架构
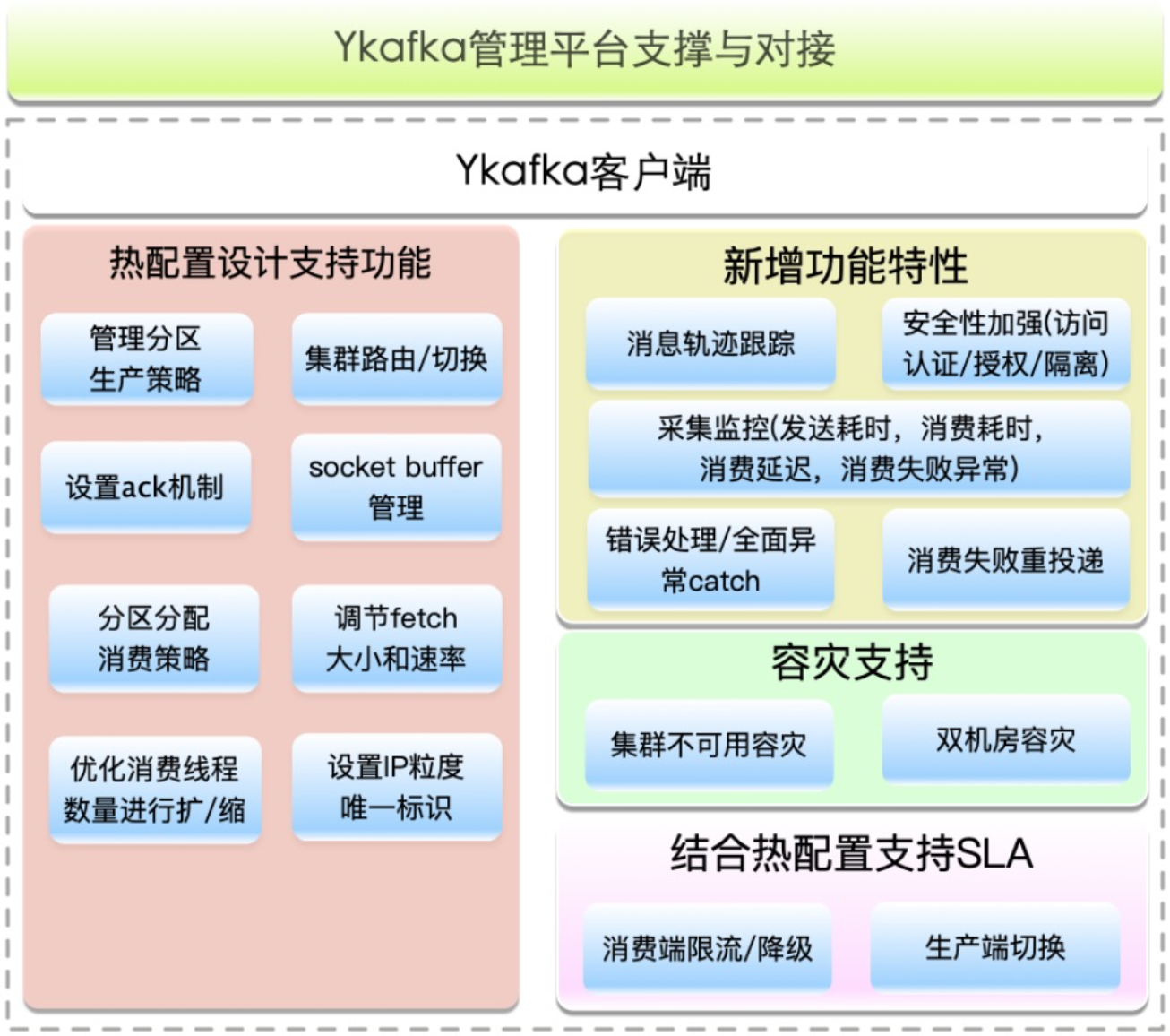
热配置设计支持功能:
- 管理分区生产策略:支持动态修改消息发送分区策略,因为业务可能使用错误,导致数据写入倾斜,也有可能运维需要,例如硬件损坏或下线等等
- 集群路由/切换:用于支持集群容灾/容错/升级,集群运行过程中可能社会突发热点事件(例如新冠病毒),导致流量飙升,集群临时扩容不能快速完成,集群调度切换是最佳选择
- 设置ack机制:动态修改写成功N个副本才返回客户端
- socket buffer管理:根据硬件配置和业务需要,修改socket buffer大小来支撑吞吐量需求
- 分区分配消费策略:除了默认Range、RoundRobin、sticky三种类型外,希望有业务消费出现异常时或不足时,服务不硬重启优雅退出消费group
- 调节fetch大小和速率:用于调节消息端对端延时和吞吐量
- 优化消费线程数量进行扩/缩:Kafka中partition是最小消费单元,一个消费线程可以消费多个partitions,为了提高消费吞吐量,可以适当增加线程数
- 设置IP粒度唯一标识:某个时刻或某突发事件造成集群负载超过了实际载荷,需要进行流量限制,Kafka是对clientid进行限制的,多个客户端会共享同一个clientid,调控粒度可以小到IP级别
- topic分级/消息轨迹功能分级开关
按级或作用域范围生效热配置,它们分别为集群、group、topic
新增功能特性:
- 消费轨迹跟踪:在topic中Message的整个生产消费生命周期中,保存生产消费链路中各个环节的执行情况,通过关键字key和时间戳可查询到可能遇到的问题
- 安全性支持(认证/授权/隔离):当前集群安全性较低,任何人只要知道集群地址和topic信息,就能访问集群,为了提高集群安全性,提供授权访问支持
- 监控报警(发送耗时、消费耗时、消费延时、消费延时异常)
- 错误处理/异常catch
- 对groupid进行生命周期管理,定期 + 实时相结合清除group
- 消费失败重投递:当前Kafka中每条message只会投递一次,如果业务处理失败,就不会再次投递,消息丢失,增加消息重投递机制
- 采集客户端并展示信息,客户端启动自主上报信息,历史上报 + 实时上报相结合
容灾支持:
- 集群不可用容灾:网络或集群异常保证仍然可用,如果网络或集群不可用,数据会先落到本地,等恢复的时候再从本地磁盘恢复到Kafka中
- 双机房容灾:机房容灾Kafka目标原则,保证数据不丢、生产者写入优先、消费可以暂停;双活容灾处理流程,A机房负责所有读写,B机房容灾备份,如A机房有故障切换写B机房进行备份,如A机房恢复则B机房同步数据,同时producer立即切回A机房,kafka客户端负责路由和调度,Consumers由于语言众多,非java语言连接填写裸地址
SLA支持:
- 消费端限流/降级:支持消费端限流、暂停,调节粒度可到IP级别
- 生产端切换:与热配置结合,支持集群间调度切换